目次
概要編(30min.)
学習編(70min.)
推論編(50min.)
概要編
講師紹介
Scott Allen
多摩美術大学情報デザイン学科非常勤講師
情報科学芸術大学院大学(IAMAS)非常勤講師
慶應義塾大学環境情報学部非常勤講師
武蔵野美術大学通信教育課程デザイン情報学科デザインシステムコース非常勤講師
backspacetokyo所属
IAMAS修了.アーティスト.投影装置・映像メディアに関する作品を制作.
詳細は以下のBiographyを参照.
https://scottallen.ws/biography
AIとは
昨今では,AIや人工知能という言葉を毎日のように目にしますが,今現在完全なAIというものは存在しません.
ですが,AIには約60年ほどの歴史があり,着実に発展を遂げてきました.まずは,これまでAIがどのような経緯で発展してきたか,その歴史を紐解いてみましょう.
歴史的側面
まず,以下の画像を見てください.AI研究は,時代の流れに伴いブーム期と冬の時代を繰り返して発展してきました.このブーム期は全部で3つあり,それぞれ第1次AIブーム,第2次AIブーム,第3次AIブームと呼ばれています.現在は,第3次AIブームの渦中です.
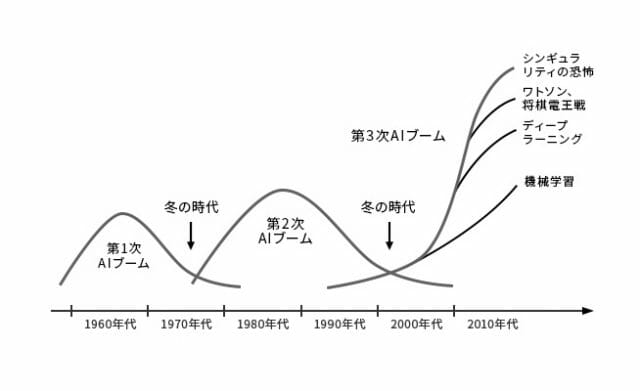
(松尾豊『人工知能は人間を超えるのか ディープラーニングの先にあるもの』KADOKAWA 発行 より引用)
起源
AI研究が本格的に始まったのは,1956年に行われたダートマス会議という会議がきっかけとされています.この会議は,ジョン・マッカーシーという科学者が主催し,他にもマービン・ミンスキーやクロード・シャノンといった科学者等が参加しました.そしてこの会議の提案書において,人類史上初めて人工知能という用語が使われたと言われています.
この会議の提案書では,人間の知的な活動を機械をシミュレートするための研究を進めるといった旨の内容が記載されていました.今は人間にしか解けない問題を機械でも解けるようにする,機械が自ら学習できるようにする,など現在のAIのイメージに近い内容がすでに構想されていました.
そしてこのダートマス会議以降,第1次AIブームが訪れます.第1次ブームでは,推論と探索が中心的に研究されました.ここでの推論とは,人間の思考パターンのことを指します.人間の思考パターンを分解し,問題に対して適切なパターンを探索することで,機械に人間と同じように思考することを目指しました.その成果として,パズルや迷路を人間よりも高速に解くことができるようになりました.しかし,問題もありました.パズルのようなルールが明確な問題に対しては成果を発揮しましたが,それ以外の問題に対しては成果を発揮することができませんでした.その結果,AI研究は一度目の冬の時代へと突入していくことになります.
エキスパートシステム
その後1980年代より,AIは第2次ブームへと突入します.第2次ブームでは,機械に知識を入れるというアプローチで研究が進み,エキスパートシステムというシステムが生まれました.エキスパートシステムではまず,機械に専門家の知識をデータとして入力します.データを入力した後は,第1次ブームで培った推論システムと組み合わせることで,機械は専門家と同じような役割を担うことができるようになります.このエキスパートシステムは医療や金融など様々な分野での応用が期待されました.
しかし第1次ブームの時と同じく,第2次ブームにおいても問題が発生します.知識を機械に入力していくことでエキスパートシステムを構築していきますが,入力されるデータが膨大になりルールの量が増えていくにつれ,ルール同士の一貫性が失われ矛盾が発生してきました.また,私たち人間が普段曖昧に使用している言葉を機械にどのように入力すればいいのか,その難しさが再認識されることとなりました.例えば,「なんとなく気分が重い」という症状の場合,「なんとなく」とはどのような意味なのか,明確にすることは難しいです.このような問題に直面し,AI研究は再び冬の時代へと突入していくことになります.
第3次AIブーム
そしていよいよ,AI研究は第3次AIブームを迎えます.第3次AIブームは現在も続いており,AI研究に大きな発展をもたらしました.その発展を支えるのが,深層学習という技術になります.
第2次AIブームまでは,人間がルールを設定し,機械がそれを計算することにとって問題を解くことが想定されていました.一方で,第3次AIブームで大きく発展した深層学習では,人間がデータを集めて機械に与えることで,機械が自らルールを発見することができます.このことにより,これまでの機械が解けなかった問題を機械が解けるようになりました.
深層学習
古典的プログラムと深層学習の違い
古典的プログラムは人間がある事象を観察したりしてルールを導き出して記述し,そのルールに基づいてコンピュータが演算し結果を出力します.
それに対して,深層学習は人間が用意した素材(データセット)と構成(アーキテクチャ)を元に,コンピュータがルール自体を学び,演算の結果を出力します.
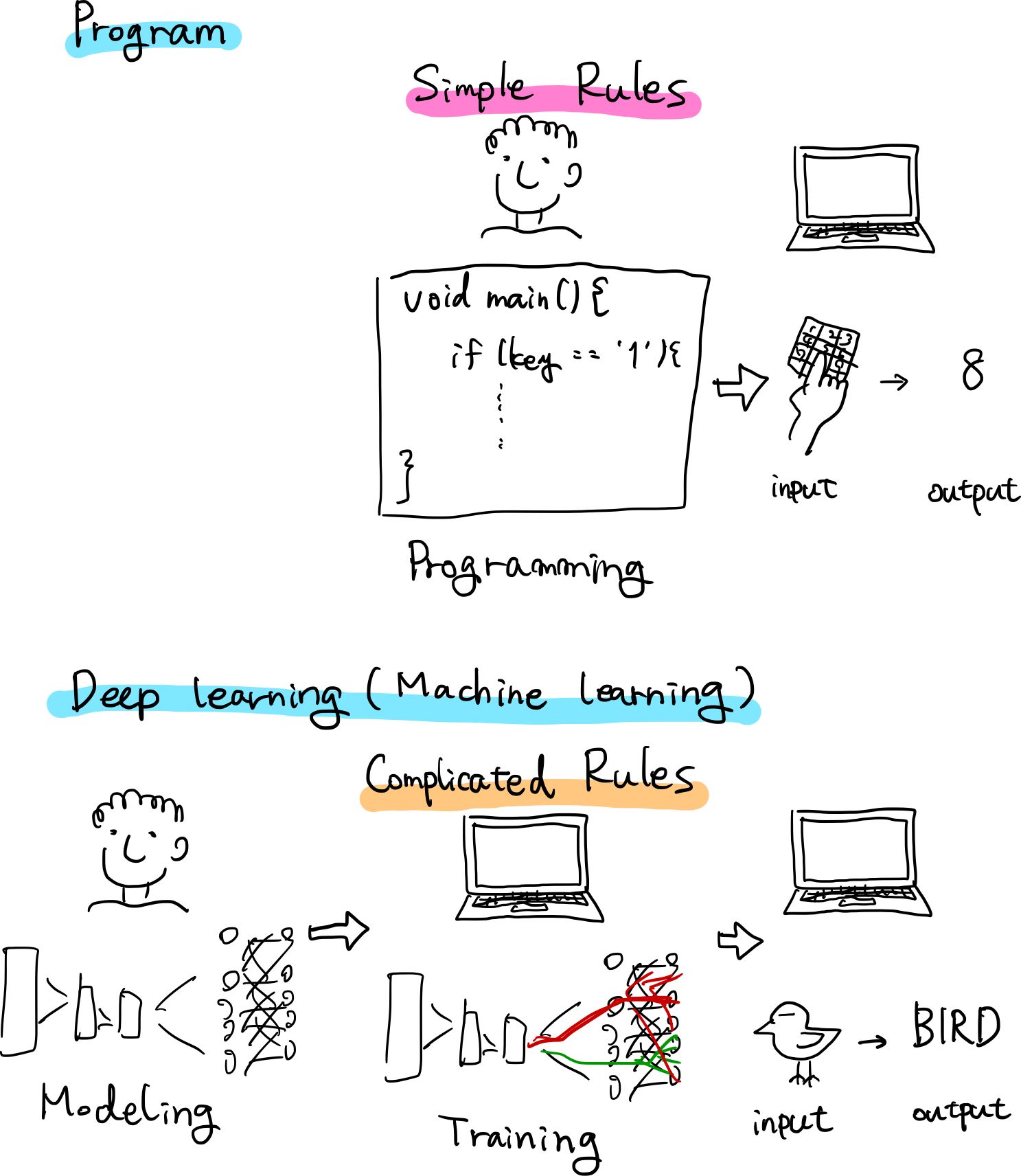
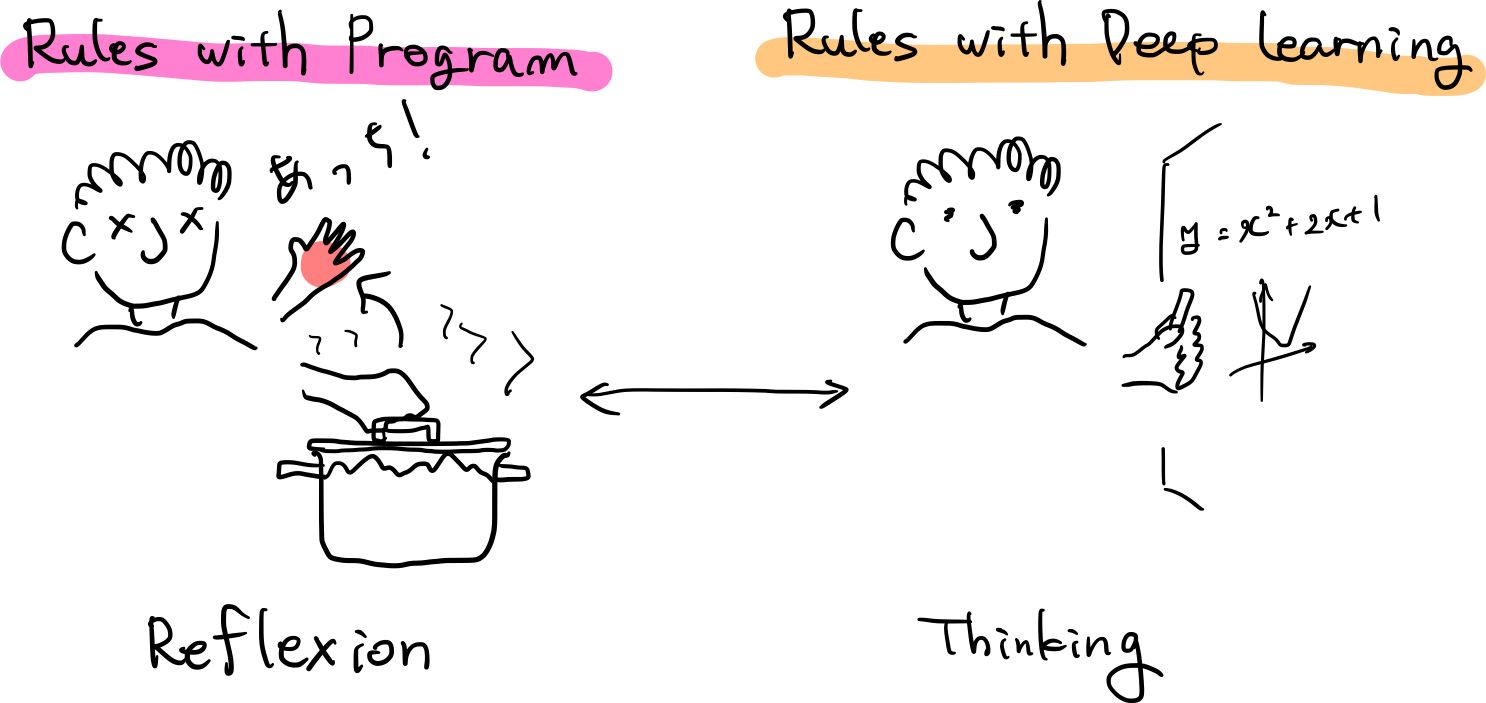
わたしたち人間が普段していることに置き換えると,
- 古典的プログラムは反射
- 深層学習は思考
と言うことができるかもしれません.
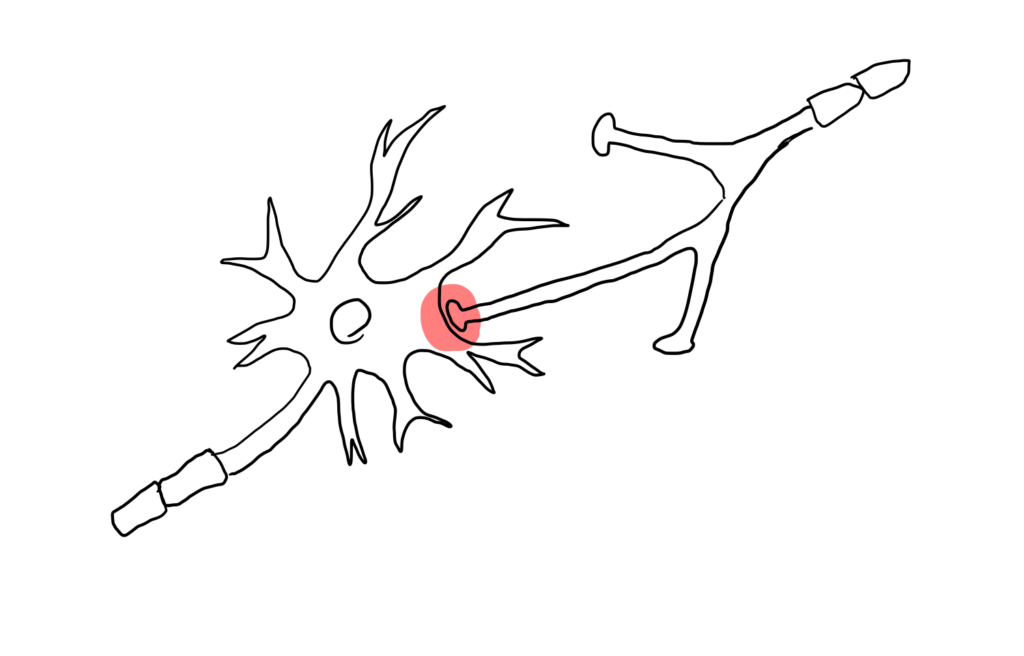
深層学習の仕組み
人間の脳はニューロン上で電気信号が伝わっていくことにより処理が行なわれます.そしてそれらは,シナプス結合の強さによって軸索から次の神経細胞への信号の伝わりやすさが変化します.
一方,人工知能の構造を画像分類を例に説明します.
- 人工的なニューロンをまず場(アーキテクチャ)として作成
- それを乱数でシナプス結合の強さを初期化
- 最終的に0-9の確率を算出
- 学習用のデータである正解ラベルを元に少しずつそれぞれの結合強さを調整(訓練,勾配法)
- 演算結果とラベルとの誤差(loss,損失関数)が少なくなると学習完了
そのモデルと結合強さ(重みW)の情報が学習済みモデルということになります.
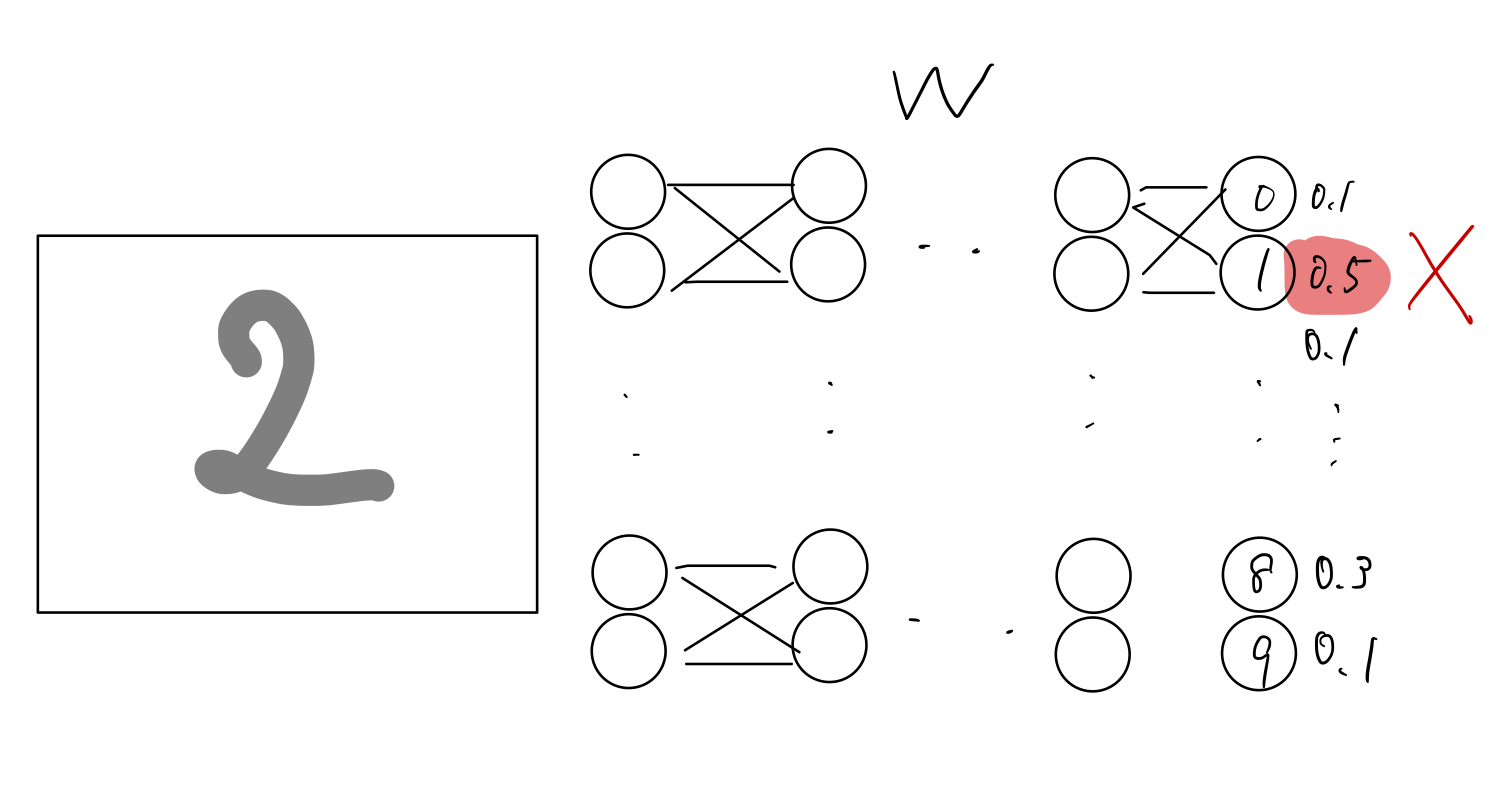
ここの中間層(隠れ層)が複数あるもののことを深層学習と言います.
E(loss): 「目標」と「実際」の出力の誤差 が小さくなるように更新していく方針で,EのWに関する微分をとり,正負からアップデートをかけて調整していきます.
どのようにAIは見るか
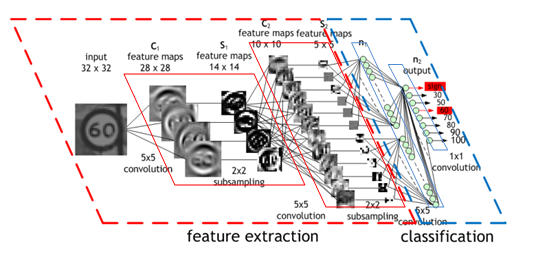
(Convolutional Neural Network (CNN) by NVIDIA より引用)
深層学習を飛躍的に発展させた1つの要素がCNNです.
CNNは単なる深層学習モデルDNNと違い,畳み込み演算(フィルター)を適用することで、画像の時空間的な依存性(隣り合ったピクセルとの関係)をうまく捉えることができます.
畳み込み演算が行われた結果の画像は図のように変化します.
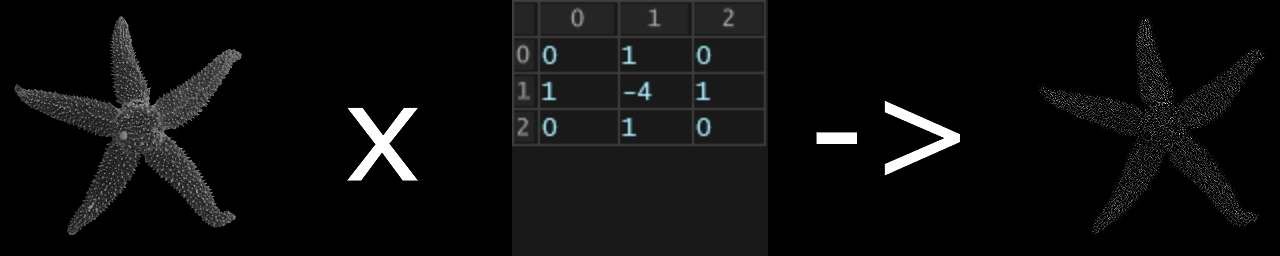
異なるフィルタを複数用いて画像を加工し,層を増やしていくことで
- 第一層: 輪郭
- 第二層: テクスチャ(質感)
- 第三層: パーツ(目,耳など)
.
.
.
などより詳細な特徴マップを得ることができます.
TouchDesignerにもConvolve TOPがあり,畳み込み演算は試すことができます.
以下の可視化動画の”Convolutional Neural Network”部分がわかりやすいです.
モデル
識別モデル
識別モデルとは,先程何度か出てきた画像分類タスクのように,入力が特定のクラスに属するか判定します.
画像分類以外にも,
- オブジェクトディテクション
- セマンティックセグメンテーション
- 深度推定
- 姿勢推定
など,数多く存在します.
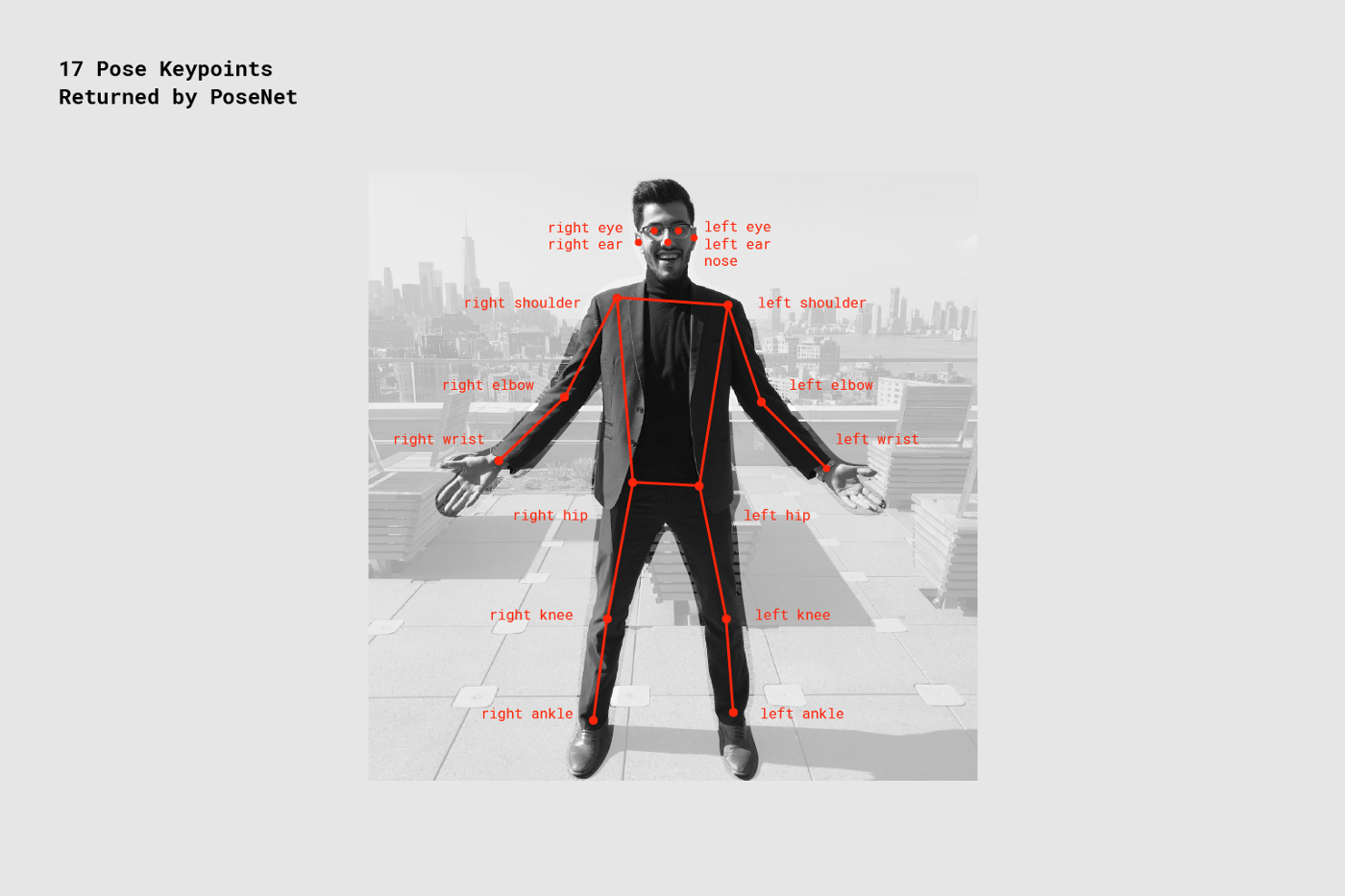
PoseNet
PoseNetは画素の情報から姿勢を推定するタスクです.
Glitch.com上で実行していきましょう.

文字列で関節名を指定して,特定の関節に何か描いたりすることもできます.
対応する文字列は表の通りです.
| 関節名 | 対応文字列 |
|---|---|
| 左耳 | leftEar |
| 右耳 | rightEar |
| 左目 | leftEye |
| 右目 | rightEye |
| 鼻 | nose |
| 左肩 | leftShoulder |
| 右肩 | rightShoulder |
| 左肘 | leftElbow |
| 右肘 | rightElbow |
| 左手首 | leftWrist |
| 右手首 | rightWrist |
| 左尻 | leftHip |
| 右尻 | rightHip |
| 左膝 | leftKnee |
| 右膝 | rightKnee |
| 左かかと | leftAnkle |
| 右かかと | rightAnkle |
パーツの場所の対応は画像の通りです.
生成モデル
これまで紹介してきた識別モデルとは別に,生成モデルと呼ばれるモデルがあります.
識別モデルでは,例えば画像分類のように,与えられた入力に対してその画像がどのクラスにあたるかを判別することを目的としていました.
一方で生成モデルでは,今あるデータの生成過程をモデル化することを目的としています.生成過程をモデル化することができれば,学習データと似たデータを新しく生成することができるようになります.
This Person Does Not Exist
This Person Does Not Exist
というサイトはGANという生成モデルで作られた実際には存在しない顔を表示するサイトです.
Edmond de Belamy, from La Famille de Belamy (2018) Obvious
2018年に,パリのアーティストグループであるObviousが,AI (GAN) を用いて制作した絵画をオークションに出品しました.そこで,7,000(約79万円)~10,000(約113万円)ドルの予想価格に対して,それを大きく上回る432,500ドル(約4894万円)の値段で落札されました.このオークションは,クリスティーズという世界で最も長い歴史を誇る美術品オークションハウスで行われたものでした.以下が,実際にオークションに出品された作品です.

右下には,アーティストの署名として,とある数式が記載されています.この数式は,この後紹介するGANというアルゴリズムの数式を意味しています.つまりObviousは,この作品の作者がAIであると主張しているのです.
果たしてAIはアートを作ることができるのか,またこのアルゴリズムの出どころで一悶着あったりなど,この作品の是非については意見が分かれると思いますが,何かと話題を呼んでいることは間違いありません.
他にも,生成モデルを用いることで音楽,映像,文章や詩など様々なものを作り出すことができます.
学習編
使用する環境
Keras
KerasはTensorFlow(Googleが開発したオープンソースの機械学習用フレームワーク)が提供するニューラルネットワーク作成用の高レベルなライブラリです.簡単なコードで素早く実装可能であるため,深層学習初学者に適したフレームワークと言えます.
今回は深層学習の入門編であるため,Kerasを用います.
ライブラリ自体は
- TensorFlow
- Keras
- PyTorch
- Caffe
- Microsoft Cognitive Toolkit
- MxNet
- Chainer
など,多種多様ですが詳細にわたる説明は割愛します.
Google Colaboratory
Googleが提供するサービスで,環境構築なしにノートブック形式のPythonで行なう深層学習を始めることができます.
使用するにはGoogleアカウントが必要になります.
Google Driveと連携可能であるため,
- 学習に必要なデータセットを準備
- 学習の結果得られたモデルの保存
- 推論の結果得られた画像の保存
などのあらゆることをGoogle Drive上で行なうことができます.
プランが3つありますが,ヘビーな使い方をしなければ基本的に無料で使えます.
| プラン | 料金 | 特徴 |
|---|---|---|
| Colab Free | 無料 | 高速なGPUが割り当てられない,ランタイムが最長12時間,RAMに制限 |
| Colab Pro | 月額1,072円 | 高速なGPU割り当て,ランタイムが最長24時間,大きなRAM |
| Colab Pro+ | 月額5,243円 | より高速なGPU割り当て,ブラウザを閉じても実行を継続,,より長いランタイム,より大きなRAM |
最近のモデルではネットワークもデータセットも膨大であることが多く,自身で用意したデータセットで学習させようと思うとRAM関係でエラーが出たりすることが多くなってきます.
Colabを使ってみる
Google Colaboratoryのページを開きます.
https://colab.research.google.com/?utm_source=scs-index
次に,File>New Notebookを選択して新しいNotebookを作ります.

Googleアカウントにサインインしていない場合はサインインを促されるため,ログインします.
このような画面になれば開始できます.
ここからは,こちらのリンクのColaboratoryのページから穴埋め的にハンズオンしていきます.
https://colab.research.google.com/drive/1c5mlL3dLJ5oRNRaeg_cCP4DjtrxaGCPD?usp=sharing
推論編
ONNX
ONNX(オニキス)はOpen Neural Network Exchangeの略称で,推論で広く使用されている機械学習モデルフォーマットです.PytorchやKerasなどの機械学習フレームワークからエクスポートすることができ,主にONNX Runtimeなどの推論に特化したSDKで推論ができるようになります.
メリット
PytorchやKerasなどは学習に最適化されているため,推論速度はあまり速くありませんが,ONNXに変換されたモデルをONNX Runtimeなどの推論に特化したSDK推論することで高速化できます.
また,PytorchやKerasなどよりONNXはファイルフォーマットが厳密に規定されているため,バージョン間の互換性がとても高いです.
注意点
注意点は共通フォーマットにありがちですが,すべてのフレームワークに対して互換があるわけではないことです.今回の場合はKerasで学習した一般的なCNN画像分類モデルをONNXに変換後,ONNX Runtimeで推論するだけなので問題になりません.
このことから,ONNXに変換できるモデルはしておいたほうが良いかもしれません.
ColabでONNXに変換する
Colab参照
TouchDesignerでONNXを読み込む
今回はこの動画のような状況を実現します.
※厳密には動画は昨年度Kerasを直接TDで読み込んだものですが,Windowsで動かなかったりしました.今回はONNXでどちらのOSでも動くようになりました.
データの準備
今回TouchDesignerで扱うのは,ONNX RuntimeのPythonライブラリです.
今回はワークショップのため,ダウンロードした外部ライブラリのパスを直接読みに行くスタイルにしますが,後日ご自身で
$pip install onnxruntime
or
$pip install onnxruntime-gpu
でカスタムライブラリの中に入れ込んでいただいてもOKです.
それではデータをダウンロードいただき,以下の手順を踏みます.
- 空のプロジェクトにGithubからクローンしたレポジトリのtox/python_loader.tox を配置します.
- プロジェクトファイルを任意の場所に保存します.
- プロジェクトファイルを閉じます.
- assets_shared内のご自身のOSや演算方法に合ったフォルダの中からassetフォルダを先ほどのTouchDesignerのプロジェクトファイルと同じ階層に配置します.
- プロジェクトファイルを開きます.
- Textportにて,
import onnxruntimeが通るか確認します.
スクリプト
今回はScript TOPを使って(CHOPでも問題ないですが,次回のことを考えてTOP)解析対象が何の画像であるか確認します.
import cv2
import numpy as np
import onnxruntime
# 推論のセッションのインスタンス
session = onnxruntime.InferenceSession(`assets/DLModel/ImageClassifier.onnx')
# クラスをnumpy配列で宣言
CLASSES = np.array(['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'],dtype=object)
def onCook(scriptOp):
# フレームの情報をnumpy配列として取得
frame = op('SRC_ANALYZE').numpyArray()
# Script TOPに書き込み(今回はそうする意味は特にありません)
scriptOp.copyNumpyArray(frame)
# モデルの入力次元と合わせるためにRGBA->RGBに変換
rgb = cv2.cvtColor(frame, cv2.COLOR_RGBA2RGB)
# モデルの入力次元と合わせるために次元を追加する
tex = rgb[np.newaxis, :, :, :]
# 入力と出力のクエリを実行する
input_texture = session.get_inputs()[0].name
output_texture = session.get_outputs()[0].name
# 推論する.返してほしい出力の一覧と入力値のマップを引数として層の名前で渡す.
# それぞれのクラスの確度が取得できる
outputs = session.run([output_texture], {input_texture: tex})
# 最大値のインデックスを取得して,CLASSESからクラス名を取得する
preds = CLASSES[np.argmax(outputs, axis = -1)]
op('text1').par.text = preds[0][0]
return
尚,GPUが使える場合(WindowsでCUDA11.2のパスが通っている場合)
# GPU IDを選択したり,GPUメモリに制限をかけることも可能
session = onnxruntime.InferenceSession(
"assets/DLModel/ImageClassifier.onnx",
providers=["CUDAExecutionProvider"],
provider_options=[{"device_id": 0,
# "gpu_mem_limit": 1 * 1024 * 1024 * 1024
}]
)
“`