目次
概要編(20min.)
学習編(70min.)
推論編(60min.)
概要編
VAE
生成モデルの一つに,Variational Autoencoder (VAE) と呼ばれるモデルがあります.VAEは生成モデルの一種なので,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.
VAEは,Autoencoderと呼ばれるモデルを発展させたモデルになので,まずはAutoencoderについて説明します.
Autoencoderとは
Autoencoderとは,訓練データを表現する特徴を学習するためのネットワークです.
訓練データとは,例えば手書き文字を集めたMNISTという有名なデータセットだったりします.
mnistは,以下の画像のように手書きの文字を集めたデータセットになります.画像認識や画像生成など,AI研究において頻繁に用いられるデータセットなので,これからも目にする機会は多いでしょう.

ちなみにKerasには前回登場したCIFAR10,今回扱うMNIST以外にも,CIFAR100,Fashion MNISTなどいくつかデータセットはあるので見てみると良いかもしれません.
https://keras.io/api/datasets/
Autoencoderとは,ニューラルネットワークのモデルの一つであり,入力画像に近い画像を出力することを目的とするモデルです.Autoencoderは,EncoderとDecoderという二つのネットワークで構成されます.Encoderは入力画像を潜在変数zと呼ばれる低次元の特徴へと変換します.逆に,Decoderは潜在変数zを入力として画像を出力します.これにより,Autoencoderは入力された画像を復元することができます.以下が,Autoencoderのネットワーク図になります.
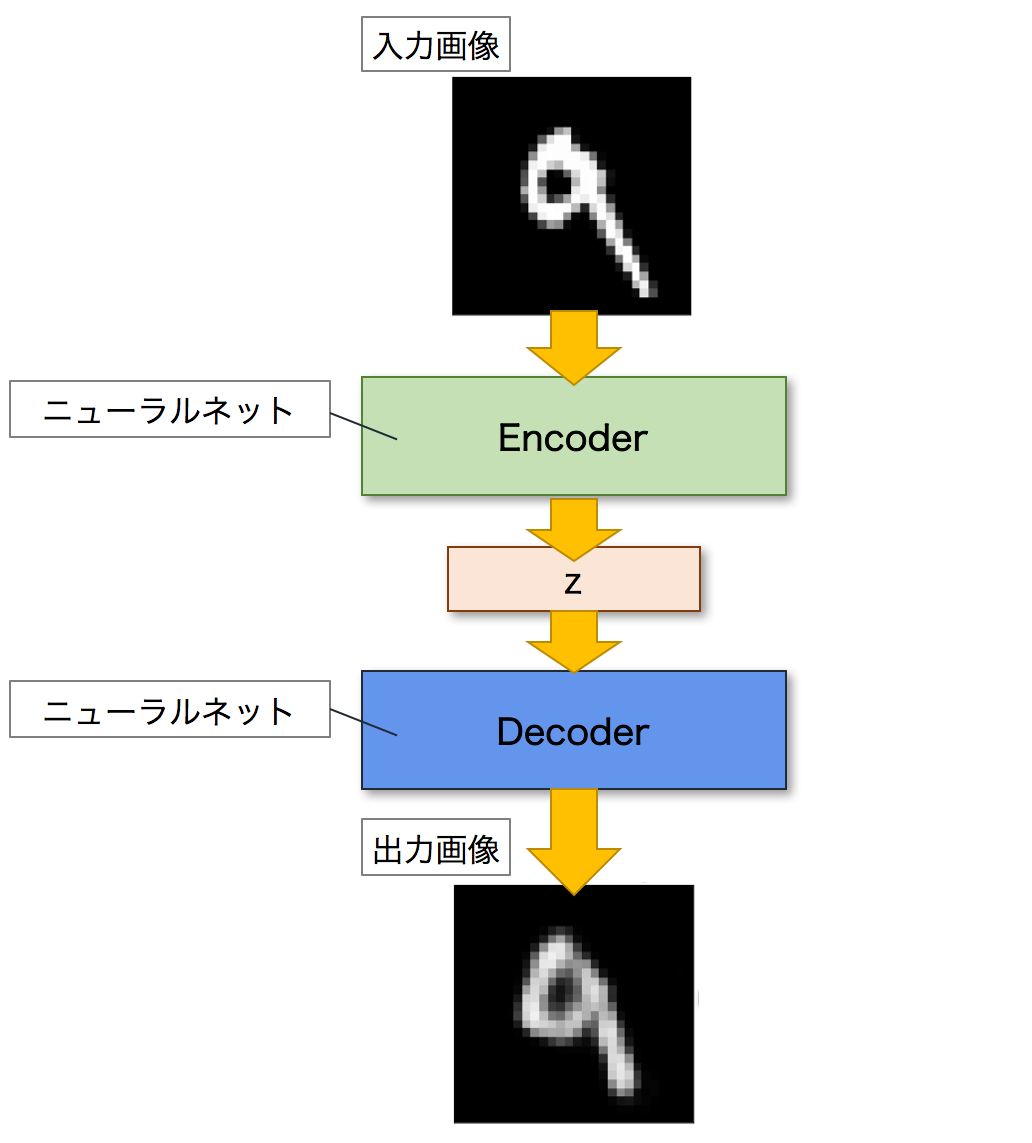
VAEとは
VAEは,Autoencoderを発展させたモデルです.全体的な構造としては,Autoencoderと同じくEncoderとDecoderの二つのネットワークで構成されています.そしてAutoencoderと同じように,Encoderが入力画像を潜在変数zへと変換し,Decoderがこの潜在変数zを元の画像へと復元して出力します.
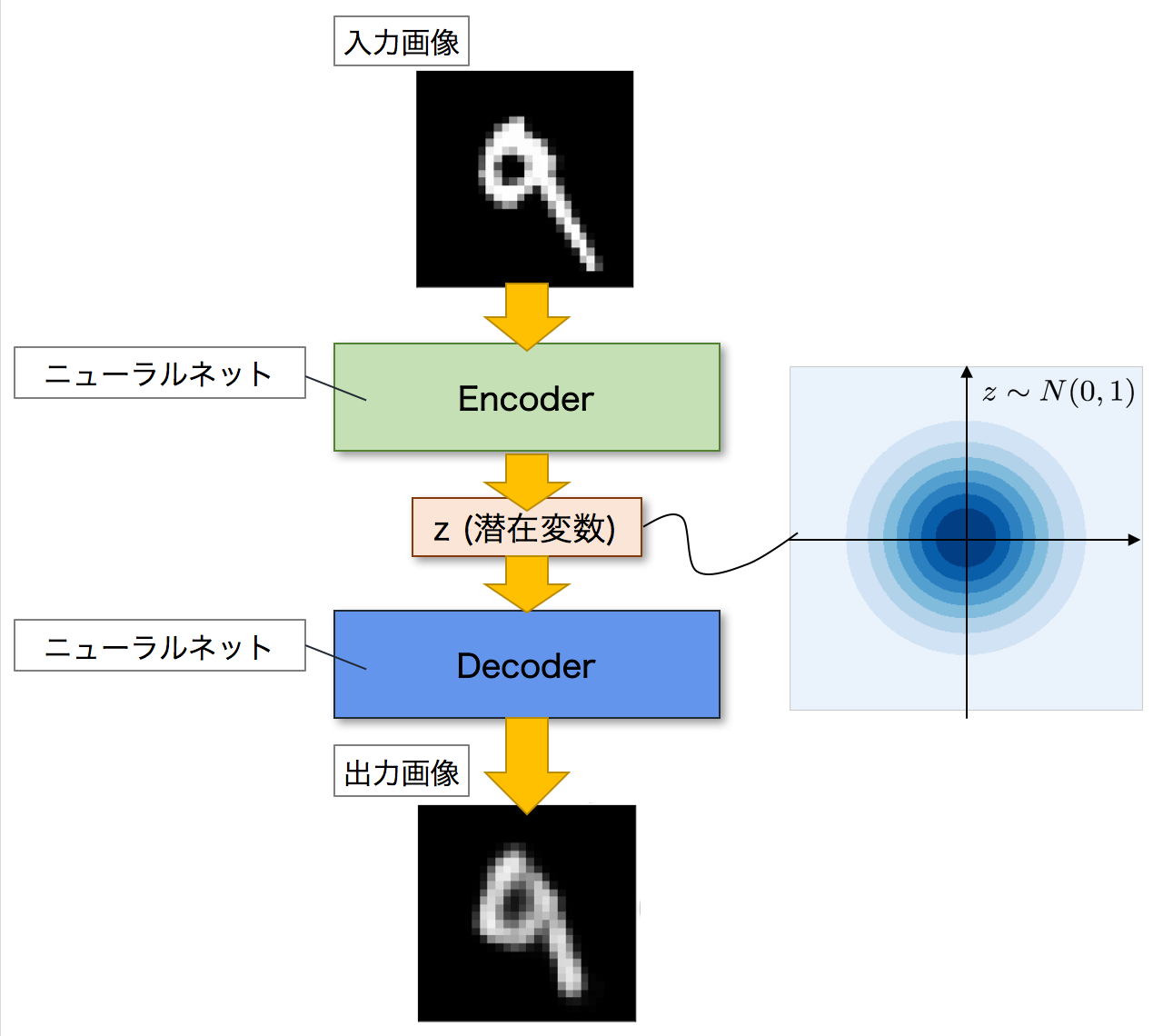
VAEがAutoencoderと異なるのは,潜在変数zの分布です.Autoencoderでは,潜在変数zにデータが押し込められますが,その分布については詳細はわかりません.一方で,VAEの場合には,潜在変数zに同じようにデータを押し込めますが,その分布が特定の確率分布に従うことを仮定しています.つまり,潜在変数zがどのような分布をしているのかが分かるということです.
VAEは生成モデルなので,学習を終えた後は,新しく画像を生成することができます.その際,Decoderに潜在変数zを入力して画像を生成しますが,この時に潜在変数zがどのような分布をしているのかがわかれば,生成する画像を細かくコントロールすることができます.
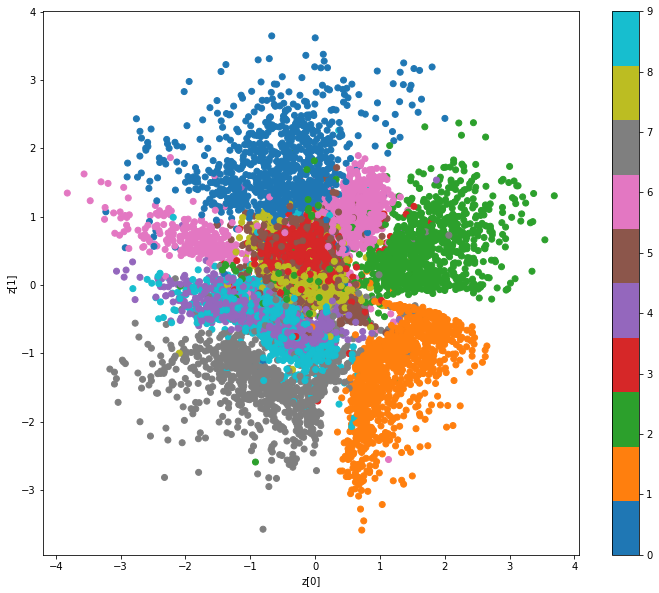
例えばMNISTであれば,そのデータには0~9までの10種類の数字が含まれます.VAEを使ってMNISTのデータを学習することで,潜在変数zのうち,ある領域には0,ある領域には1,そして別の領域には他の数字が含まれるようになります.以下の画像は,実際に潜在変数zの分布を可視化した画像です.画像右上の領域には0が,左下の領域には1が含まれていることがわかります.

GANとは
GANも生成モデルの一種です.そのためVAEと同じように,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.また,ある入力を別の入力へと変換することもできます.
GANがVAEと大きく異なる点は,その学習方法にあります.GANは,日本語では敵対的生成ネットワークと訳されますが,その名の通り,GANでは「敵対的」に学習が進んでいきます.
GANの構造を以下の画像に示します.GANは,GeneratorとDiscriminatorという2つのネットワークで構成されます.Generatorは,データを生成するネットワークです.Discriminatorは,Generatorが生成した偽物のデータと本物の学習データに対して,どちらが本物のデータであるかを識別します.この2つのネットワークを交互に学習していくことで,Generatorはより本物に近いデータを生成できるようになり,Discriminatorは本物・偽物をより正確に判断することができるようになっていきます.この時,GeneratorとDiscriminatorがお互い競い合うように学習していくため,「敵対的」と呼ばれているのです.
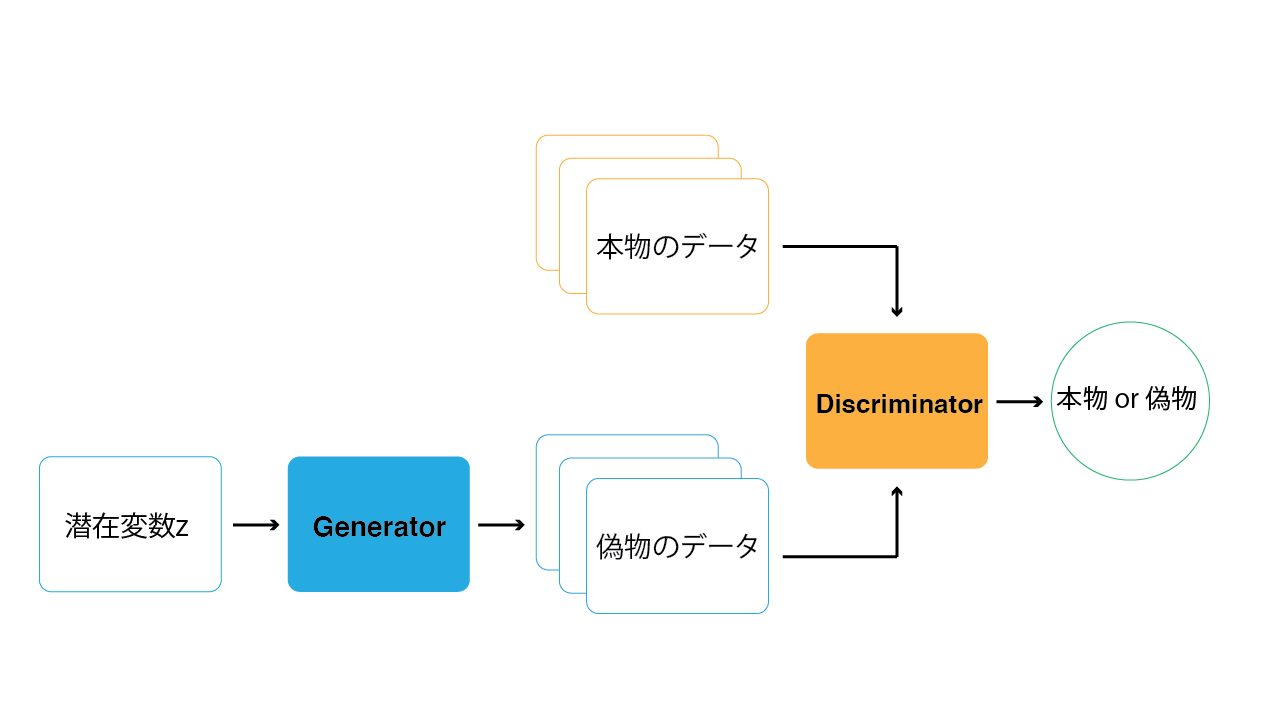
このGeneratorとDiscriminatorの関係は,よく紙幣の偽造に例えられます.偽札の作成者 (Generator) はなるべく本物に近い紙幣を作ろうとし,警察官 (Discriminator) はより正確に偽札を見分けようとします.そしてお互い交互に学習していくことで,最終的に偽札の作成者は本物とほぼ区別のつかない偽札を作れるようになっていきます.
学習編
ColabでAutoEncoderを実装して学習する
ここからは,こちらのリンクのColaboratoryのページから穴埋め的にハンズオンしていきます.
https://colab.research.google.com/drive/1jbXgOkybnm0sHyR2xyEeorC–OcwBeIs?usp=sharing
推論編
ColabでONNXに変換する
Colab参照
TouchDesignerでONNXを読み込む
今回はこの動画のような状況を実現します.
※厳密には動画は昨年度Kerasを直接TDで読み込んだものですが,Windowsで動かなかったりしました.今回はONNXでどちらのOSでも動くようになりました.
データの準備
今回TouchDesignerで扱うのは,ONNX RuntimeのPythonライブラリです.
今回はワークショップのため,ダウンロードした外部ライブラリのパスを直接読みに行くスタイルにしますが,後日ご自身で
$pip install onnxruntime
or
$pip install onnxruntime-gpu
でカスタムライブラリの中に入れ込んでいただいてもOKです.
それではデータをダウンロードいただき,以下の手順を踏みます.
- 空のプロジェクトにGithubからクローンしたレポジトリのtox/python_loader.tox を配置します.
- プロジェクトファイルを任意の場所に保存します.
- プロジェクトファイルを閉じます.
- assets_shared内のご自身のOSや演算方法に合ったフォルダの中からassetフォルダを先ほどのTouchDesignerのプロジェクトファイルと同じ階層に配置します.
- プロジェクトファイルを開きます.
- Textportにて,
import onnxruntimeが通るか確認します.
画像を入力して推論する
今回はScript TOPを使って解析対象の画像と似た画像を作り出します.
import cv2
import numpy as np
import onnxruntime
# 推論のセッションのインスタンス
session = onnxruntime.InferenceSession('assets/DLModel/AE.onnx')
def onCook(scriptOp):
# フレームの情報をnumpy配列として取得
frame = op('SRC_ANALYZE').numpyArray()
# # Script TOPに書き込み(何もなければ,そのままframeがアウトプットになる)
scriptOp.copyNumpyArray(frame)
# モデルの入力に合わせてRGBAからGRAYSCALEへ
gray = cv2.cvtColor(frame, cv2.COLOR_RGBA2GRAY)
# モデルの入力に合わせて平滑化
gray = gray.flatten()
# モデルの入力に合わせて軸を追加
tex = gray[np.newaxis, :]
# 入力と出力のクエリを実行する
input_texture = session.get_inputs()[0].name
output_texture = session.get_outputs()[0].name
# 推論する.返してほしい出力の一覧と入力値のマップを引数として層の名前で渡す.
# 平滑化されたグレースケールの画像が取得できる
outputs = session.run([output_texture], {input_texture: tex})
# 軸をなくす
outputs = outputs[0].squeeze(axis=0)
# 784->28x28に戻す
outputs = np.reshape(outputs, (-1, 28))
# numpyとTouchDesigner環境の並びを合わせるために上下反転する
outputs = np.flipud(outputs)
# TOPに出力して他のフレームとミックスするため,RGBAに戻す
outputs = cv2.cvtColor(outputs, cv2.COLOR_GRAY2RGBA)
# Script TOPのコピー
scriptOp.copyNumpyArray(outputs)
return
尚,GPUが使える場合(WindowsでCUDA11.2のパスが通っている場合)
# GPU IDを選択したり,GPUメモリに制限をかけることも可能
session = onnxruntime.InferenceSession(
"assets/DLModel/ImageClassifier.onnx",
providers=["CUDAExecutionProvider"],
provider_options=[{"device_id": 0,
# "gpu_mem_limit": 1 * 1024 * 1024 * 1024
}]
)
2次元座標を入力して推論する
今回はDecoderに直接,TouchDesignerで作った値を入力することで推論してみます.
これができると画像のモーフィングなどがリアルタイムに用意にできるようになります.
また,データセットの座標系のビジュアライゼーションもしてみます.
import cv2
import numpy as np
import onnxruntime
# Encoderの推論のセッションのインスタンス
session = onnxruntime.InferenceSession('assets/DLModel/AE_encoder.onnx')
# Decoderの推論のセッションのインスタンス
session_de = onnxruntime.InferenceSession('assets/DLModel/AE_decoder.onnx')
# MNISTデータセットのnumpy配列を読み込む
mnist = np.load('assets/numpy/mnist_x_train.npy')
# 入力と出力のクエリを実行する
input_texture = session.get_inputs()[0].name
encoded = session.get_outputs()[0].name
# 推論する.返してほしい出力の一覧と入力値のマップを引数として層の名前で渡す.
# 潜在変数zの分布が取得できる
encoder_outputs = session.run([encoded], {input_texture: mnist})
# MNISTデータセットのラベル(0-9)を読み込む
num_label = np.load('assets/numpy/mnist_y_train.npy')
def onCook(scriptOp):
# ボタンを押したら分布をScript CHOPに反映
if op('LOAD_DATA')[0]:
# 表示数
n_to_show = 5000
scr = op("script2")
# CHOPのデータをクリア
scr.clear()
# チャンネルを追加
tx = scr.appendChan("tx")
ty = scr.appendChan("ty")
tl = scr.appendChan("tl")
# サンプル数を設定
scr.numSamples = n_to_show
# 得られた分布とラベルをサンプルに追加
for i in range(n_to_show):
tx[i] = encoder_outputs[0][i][0]
ty[i] = encoder_outputs[0][i][1]
tl[i] = num_label[i]
# 空のnumpyを生成
z_p = np.empty(2)
# TouchDesigner上で生成した値を格納
z_p[0] = op("POS")["tx"]
z_p[1] = op("POS")["ty"]
# Decoderの入力に合わせて軸を追加
z_p = z_p[np.newaxis, :]
# Decoderの入力に合わせて32bit floatに変更
z_p = z_p.astype('float32')
# 入力と出力のクエリを実行する
decoder_input = session_de.get_inputs()[0].name
decoded_texture = session_de.get_outputs()[0].name
# 推論する.返してほしい出力の一覧と入力値のマップを引数として層の名前で渡す.
# 入力した値から生成された画像が得られる
decoder_outputs = session_de.run([decoded_texture], {decoder_input: z_p})
# 軸をなくす
outputs = outputs[0].squeeze(axis=0)
# 784->28x28に戻す
outputs = np.reshape(outputs, (-1, 28))
# numpyとTouchDesigner環境の並びを合わせるために上下反転する
outputs = np.flipud(outputs)
# TOPに出力して他のフレームとミックスするため,RGBAに戻す
outputs = cv2.cvtColor(outputs, cv2.COLOR_GRAY2RGBA)
# Script TOPのコピー
scriptOp.copyNumpyArray(outputs)
return