目次
概要編(90min.)
実践学習編(90min.)
実践識別モデル編(90min.)
実践生成モデル編(10min.)
サウンド連携編(80min.)
assetsリンク
ダウンロードしておいてください.
assetリンク
概要編
AIとは
昨今では,AIや人工知能という言葉を毎日のように目にしますが,今現在完全なAIというものは存在しません.
ですが,AIには約60年ほどの歴史があり,着実に発展を遂げてきました.まずは,これまでAIがどのような経緯で発展してきたか,その歴史を紐解いてみましょう.
歴史的側面
まず,以下の画像を見てください.AI研究は,時代の流れに伴いブーム期と冬の時代を繰り返して発展してきました.このブーム期は全部で3つあり,それぞれ第1次AIブーム,第2次AIブーム,第3次AIブームと呼ばれています.現在は,第3次AIブームの渦中です.
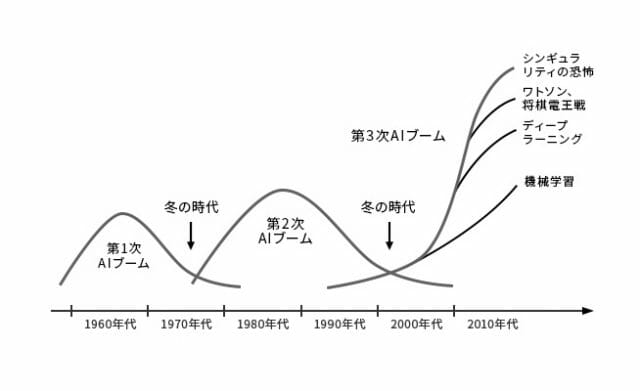
(松尾豊『人工知能は人間を超えるのか ディープラーニングの先にあるもの』KADOKAWA 発行 より引用)
起源
AI研究が本格的に始まったのは,1956年に行われたダートマス会議という会議がきっかけとされています.この会議は,ジョン・マッカーシーという科学者が主催し,他にもマービン・ミンスキーやクロード・シャノンといった科学者等が参加しました.そしてこの会議の提案書において,人類史上初めて人工知能という用語が使われたと言われています.
この会議の提案書では,人間の知的な活動を機械をシミュレートするための研究を進めるといった旨の内容が記載されていました.今は人間にしか解けない問題を機械でも解けるようにする,機械が自ら学習できるようにする,など現在のAIのイメージに近い内容がすでに構想されていました.
そしてこのダートマス会議以降,第1次AIブームが訪れます.第1次ブームでは,推論と探索が中心的に研究されました.ここでの推論とは,人間の思考パターンのことを指します.人間の思考パターンを分解し,問題に対して適切なパターンを探索することで,機械に人間と同じように思考することを目指しました.その成果として,パズルや迷路を人間よりも高速に解くことができるようになりました.しかし,問題もありました.パズルのようなルールが明確な問題に対しては成果を発揮しましたが,それ以外の問題に対しては成果を発揮することができませんでした.その結果,AI研究は一度目の冬の時代へと突入していくことになります.
エキスパートシステム
その後1980年代より,AIは第2次ブームへと突入します.第2次ブームでは,機械に知識を入れるというアプローチで研究が進み,エキスパートシステムというシステムが生まれました.エキスパートシステムではまず,機械に専門家の知識をデータとして入力します.データを入力した後は,第1次ブームで培った推論システムと組み合わせることで,機械は専門家と同じような役割を担うことができるようになります.このエキスパートシステムは医療や金融など様々な分野での応用が期待されました.
しかし第1次ブームの時と同じく,第2次ブームにおいても問題が発生します.知識を機械に入力していくことでエキスパートシステムを構築していきますが,入力されるデータが膨大になりルールの量が増えていくにつれ,ルール同士の一貫性が失われ矛盾が発生してきました.また,私たち人間が普段曖昧に使用している言葉を機械にどのように入力すればいいのか,その難しさが再認識されることとなりました.例えば,「なんとなく気分が重い」という症状の場合,「なんとなく」とはどのような意味なのか,明確にすることは難しいです.このような問題に直面し,AI研究は再び冬の時代へと突入していくことになります.
第3次AIブーム
そしていよいよ,AI研究は第3次AIブームを迎えます.第3次AIブームは現在も続いており,AI研究に大きな発展をもたらしました.その発展を支えるのが,深層学習という技術になります.
第2次AIブームまでは,人間がルールを設定し,機械がそれを計算することにとって問題を解くことが想定されていました.一方で,第3次AIブームで大きく発展した深層学習では,人間がデータを集めて機械に与えることで,機械が自らルールを発見することができます.このことにより,これまでの機械が解けなかった問題を機械が解けるようになりました.
深層学習
古典的プログラムと深層学習の違い
古典的プログラムは人間がある事象を観察したりしてルールを導き出して記述し,そのルールに基づいてコンピュータが演算し結果を出力します.
それに対して,深層学習は人間が用意した素材(データセット)と構成(アーキテクチャ)を元に,コンピュータがルール自体を学び,演算の結果を出力します.
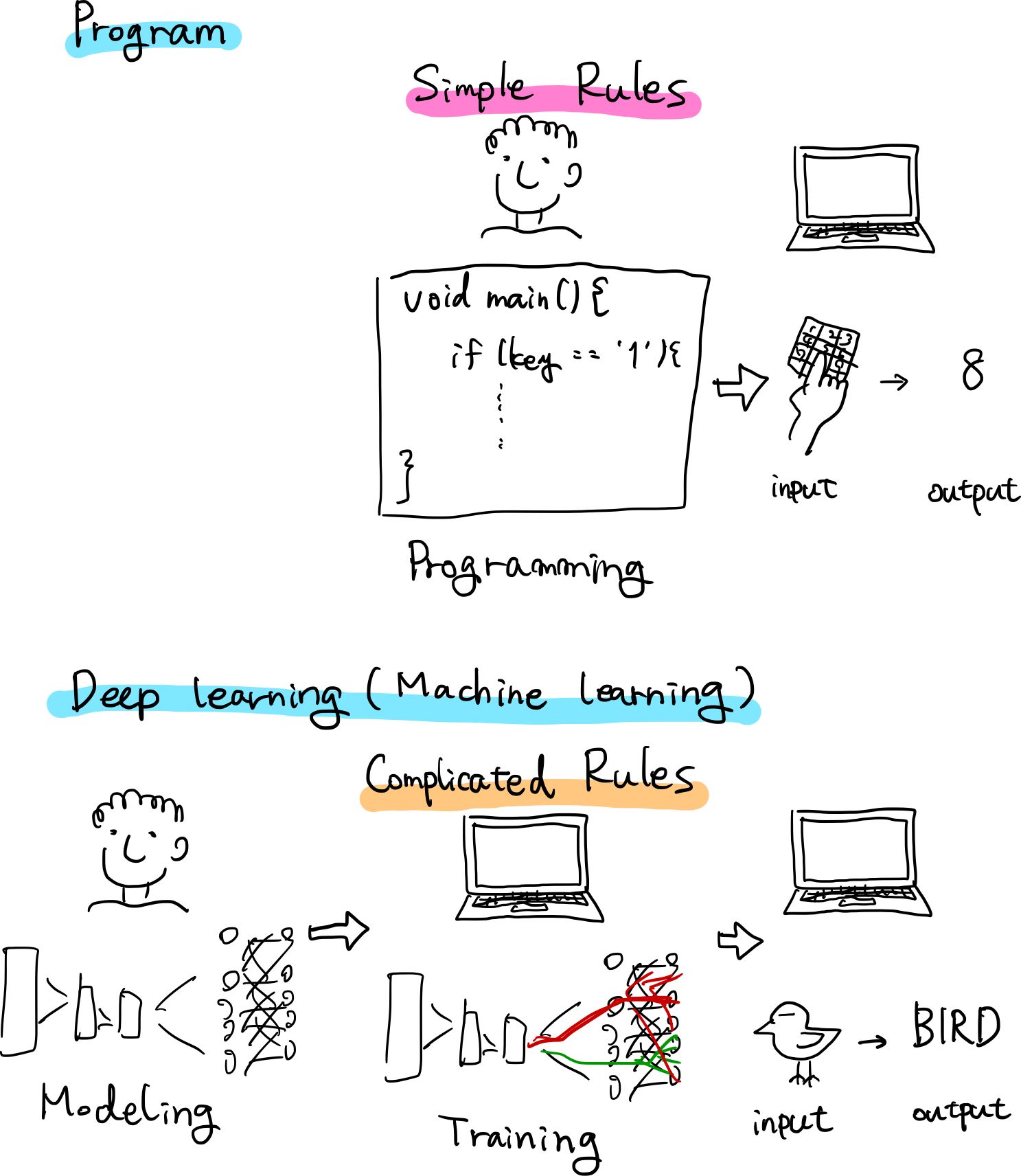
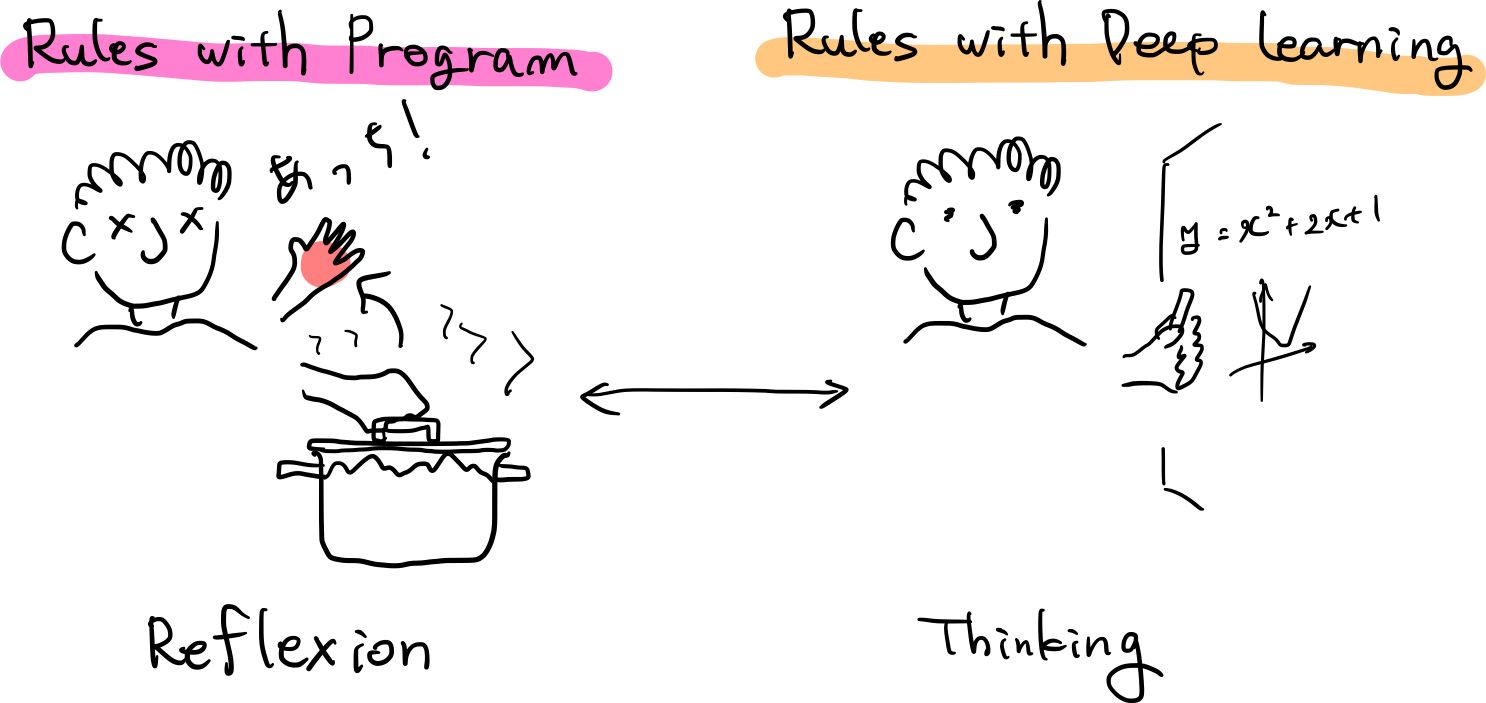
わたしたち人間が普段していることに置き換えると,
- 古典的プログラムは反射
- 深層学習は思考
と言うことができるかもしれません.
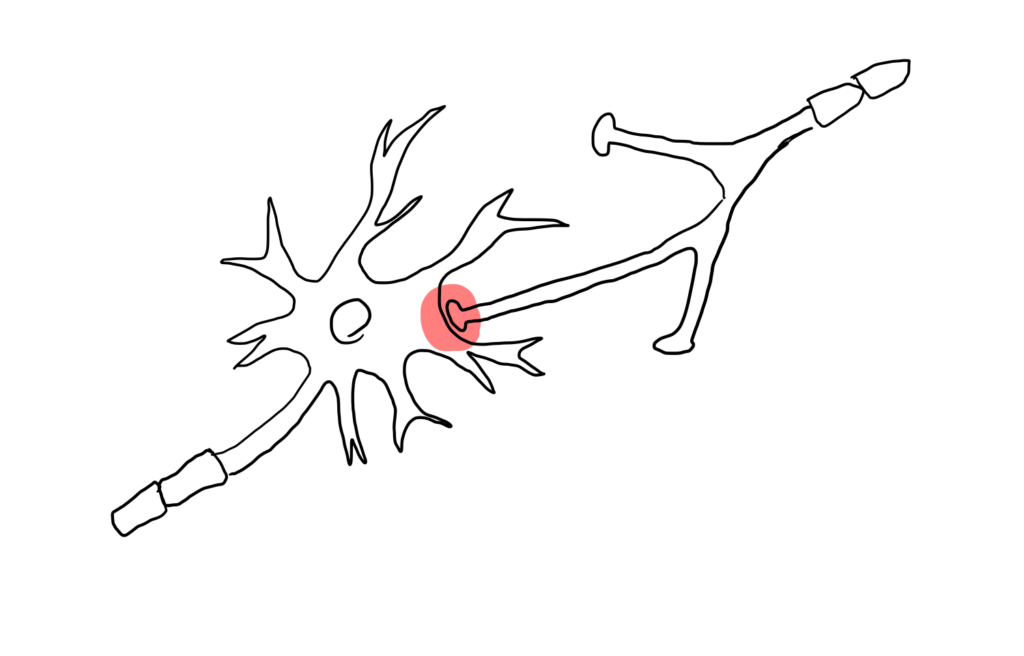
深層学習の仕組み
人間の脳はニューロン上で電気信号が伝わっていくことにより処理が行なわれます.そしてそれらは,シナプス結合の強さによって軸索から次の神経細胞への信号の伝わりやすさが変化します.
一方,人工知能の構造を画像分類を例に説明します.
- 人工的なニューロンをまず場(アーキテクチャ)として作成
- それを乱数でシナプス結合の強さを初期化
- 最終的に0-9の確率を算出
- 学習用のデータである正解ラベルを元に少しずつそれぞれの結合強さを調整(訓練,勾配法)
- 演算結果とラベルとの誤差(loss,損失関数)が少なくなると学習完了
そのモデルと結合強さ(重みW)の情報が学習済みモデルということになります.
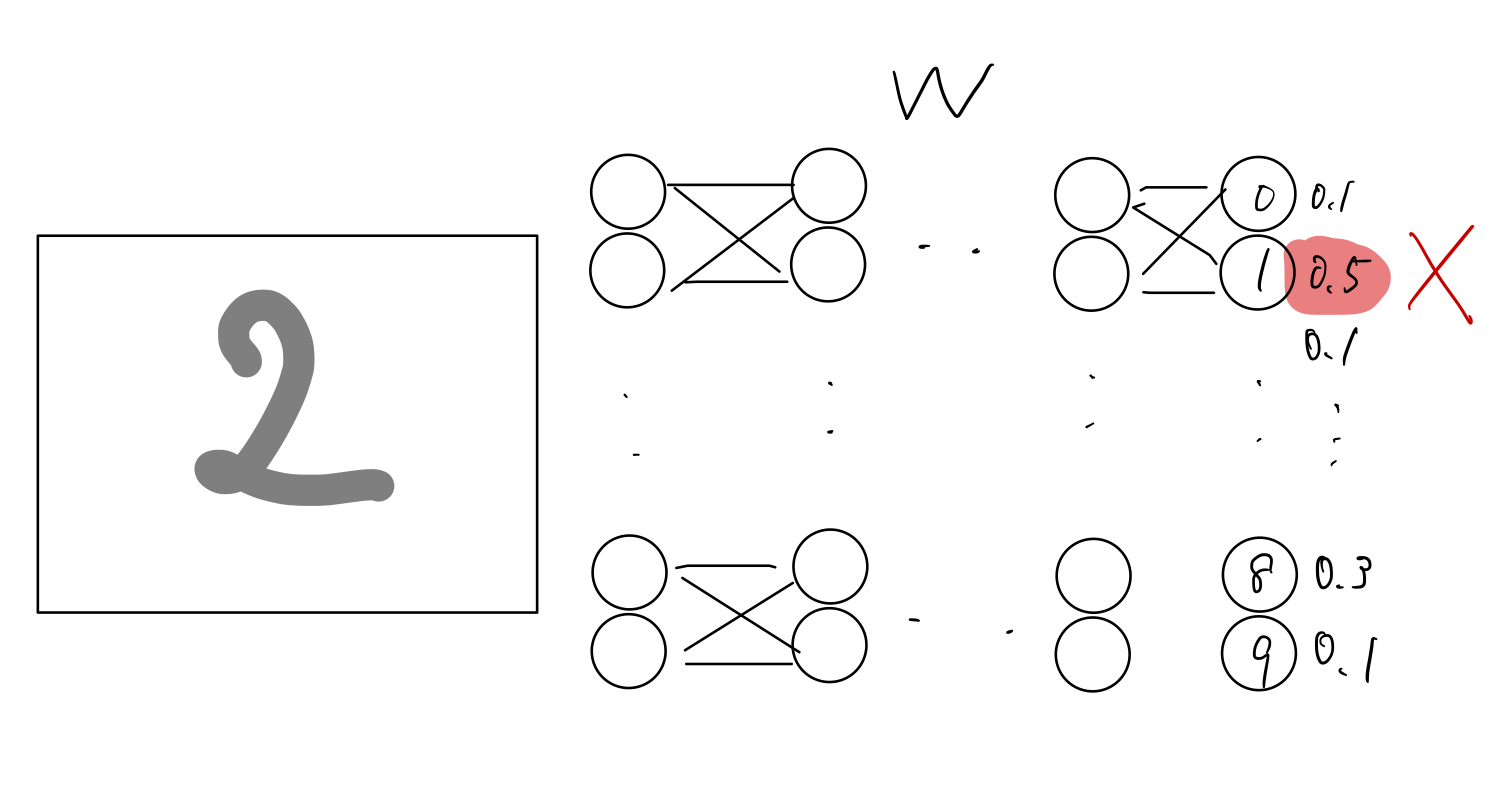
ここの中間層(隠れ層)が複数あるもののことを深層学習と言います.
E(loss): 「目標」と「実際」の出力の誤差 が小さくなるように更新していく方針で,EのWに関する微分をとり,正負からアップデートをかけて調整していきます.
どのようにAIは見るか
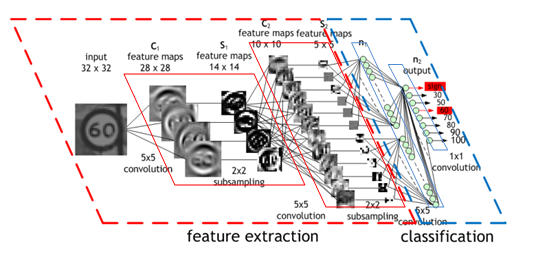
(Convolutional Neural Network (CNN) by NVIDIA より引用)
深層学習を飛躍的に発展させた1つの要素がCNNです.
CNNは単なる深層学習モデルDNNと違い,畳み込み演算(フィルター)を適用することで、画像の時空間的な依存性(隣り合ったピクセルとの関係)をうまく捉えることができます.
畳み込み演算が行われた結果の画像は図のように変化します.
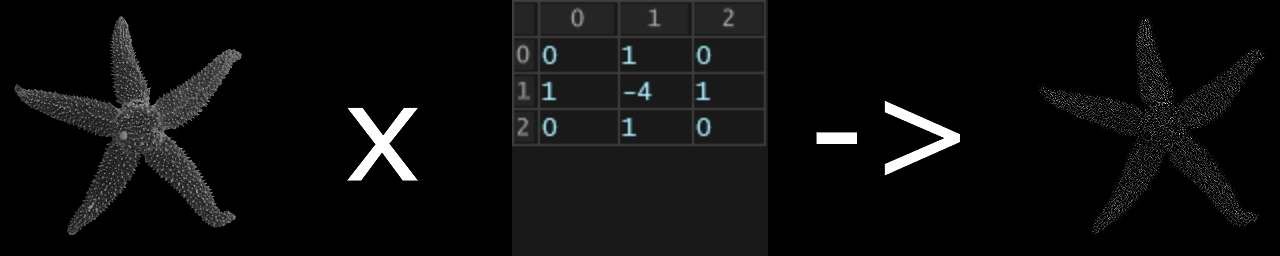
異なるフィルタを複数用いて画像を加工し,層を増やしていくことで
- 第一層: 輪郭
- 第二層: テクスチャ(質感)
- 第三層: パーツ(目,耳など)
.
.
.
などより詳細な特徴マップを得ることができます.
以下の可視化動画の”Convolutional Neural Network”部分がわかりやすいです.
こちらのGoogle Arts & CultureのCurator tableはアートの画像的な特徴を捉えて,2Dにマッピングしています.
日本画と西洋絵画が一部かなり近いことに気付かされたりします.
https://artsexperiments.withgoogle.com/curatortable/
モデル
識別モデル
識別モデルとは,先程何度か出てきた画像分類タスクのように,入力が特定のクラスに属するか判定します.
画像分類以外にも,
- オブジェクトディテクション
- セマンティックセグメンテーション
- 深度推定
- 姿勢推定
など,数多く存在します.

例えばセマンティックセグメンテーションは,画素1つ1つに対してモデル内の何のクラスに属するか分類するため,画像のように厳密に領域を区別できます.
生成モデル
これまで紹介してきた識別モデルとは別に,生成モデルと呼ばれるモデルがあります.
識別モデルでは,例えば画像分類のように,与えられた入力に対してその画像がどのクラスにあたるかを判別することを目的としていました.
一方で生成モデルでは,今あるデータの生成過程をモデル化することを目的としています.生成過程をモデル化することができれば,学習データと似たデータを新しく生成することができるようになります.
This Person Does Not Exist
This Person Does Not Exist
というサイトはGANという生成モデルで作られた実際には存在しない顔を表示するサイトです.
Edmond de Belamy, from La Famille de Belamy (2018) Obvious
2018年に,パリのアーティストグループであるObviousが,AI (GAN) を用いて制作した絵画をオークションに出品しました.そこで,7,000(約79万円)~10,000(約113万円)ドルの予想価格に対して,それを大きく上回る432,500ドル(約4894万円)の値段で落札されました.このオークションは,クリスティーズという世界で最も長い歴史を誇る美術品オークションハウスで行われたものでした.以下が,実際にオークションに出品された作品です.

右下には,アーティストの署名として,とある数式が記載されています.この数式は,この後紹介するGANというアルゴリズムの数式を意味しています.つまりObviousは,この作品の作者がAIであると主張しているのです.
果たしてAIはアートを作ることができるのか,またこのアルゴリズムの出どころで一悶着あったりなど,この作品の是非については意見が分かれると思いますが,何かと話題を呼んでいることは間違いありません.
このように,生成モデルを用いることによって,非常にクオリティの高い画像やアート作品を作り出すことができます.
ここで紹介した事例以外にも,生成モデルを用いることで以下のようなことができます.
- 絵画のデータを学習して,新しく絵画を生成する
- 音楽のデータを学習して,新しい音楽を生成する
- 文章を学習して,新しく文章を生成する
- 俳句のデータを学習して,新しく俳句を生成する
ここまで見てきた生成モデルには様々な種類があり,現在もたくさんの研究が行われています.今回は,その中でも有名なVAEとGANについて扱います.
VAE
生成モデルの一つに,Variational Autoencoder (VAE) と呼ばれるモデルがあります.VAEは生成モデルの一種なので,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.
VAEは,Autoencoderと呼ばれるモデルを発展させたモデルになります.そのため,まずはAutoencoderについて説明します.
Autoencoderとは,訓練データを表現する特徴を学習するためのネットワークです.
訓練データとは,学習したい画像を集めたデータセットになります.ここでは,例としてmnistという有名なデータセットを取り上げます.
mnistは,以下の画像のように手書きの文字を集めたデータセットになります.画像認識や画像生成など,AI研究において頻繁に用いられるデータセットなので,これからも目にする機会は多いでしょう.

Autoencoderとは,ニューラルネットワークのモデルの一つであり,入力画像に近い画像を出力することを目的とするモデルです.Autoencoderは,EncoderとDecoderという二つのネットワークで構成されます.Encoderは入力画像を潜在変数zと呼ばれる低次元の特徴へと変換します.逆に,Decoderは潜在変数zを入力として画像を出力します.これにより,Autoencoderは入力された画像を復元することができます.以下が,Autoencoderのネットワーク図になります.
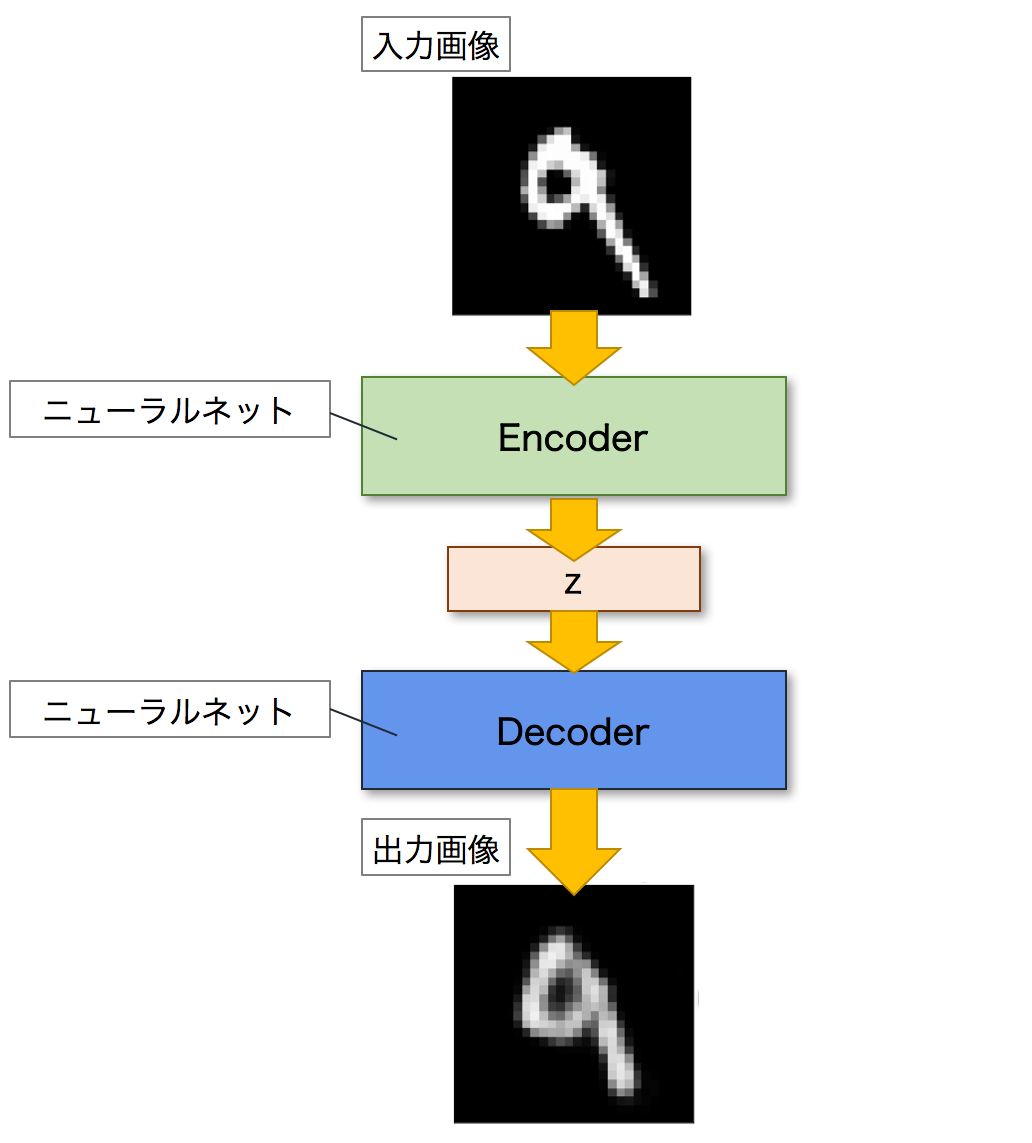
次に,VAEについて見ていきましょう.VAEは,Autoencoderを発展させたモデルになります.以下がVAEのネットワーク図になります.全体的な構造としては,Autoencoderと同じくEncoderとDecoderの二つのネットワークで構成されています.そしてAutoencoderと同じように,Encoderが入力画像を潜在変数zへと変換し,Decoderがこの潜在変数zを元の画像へと復元して出力します.
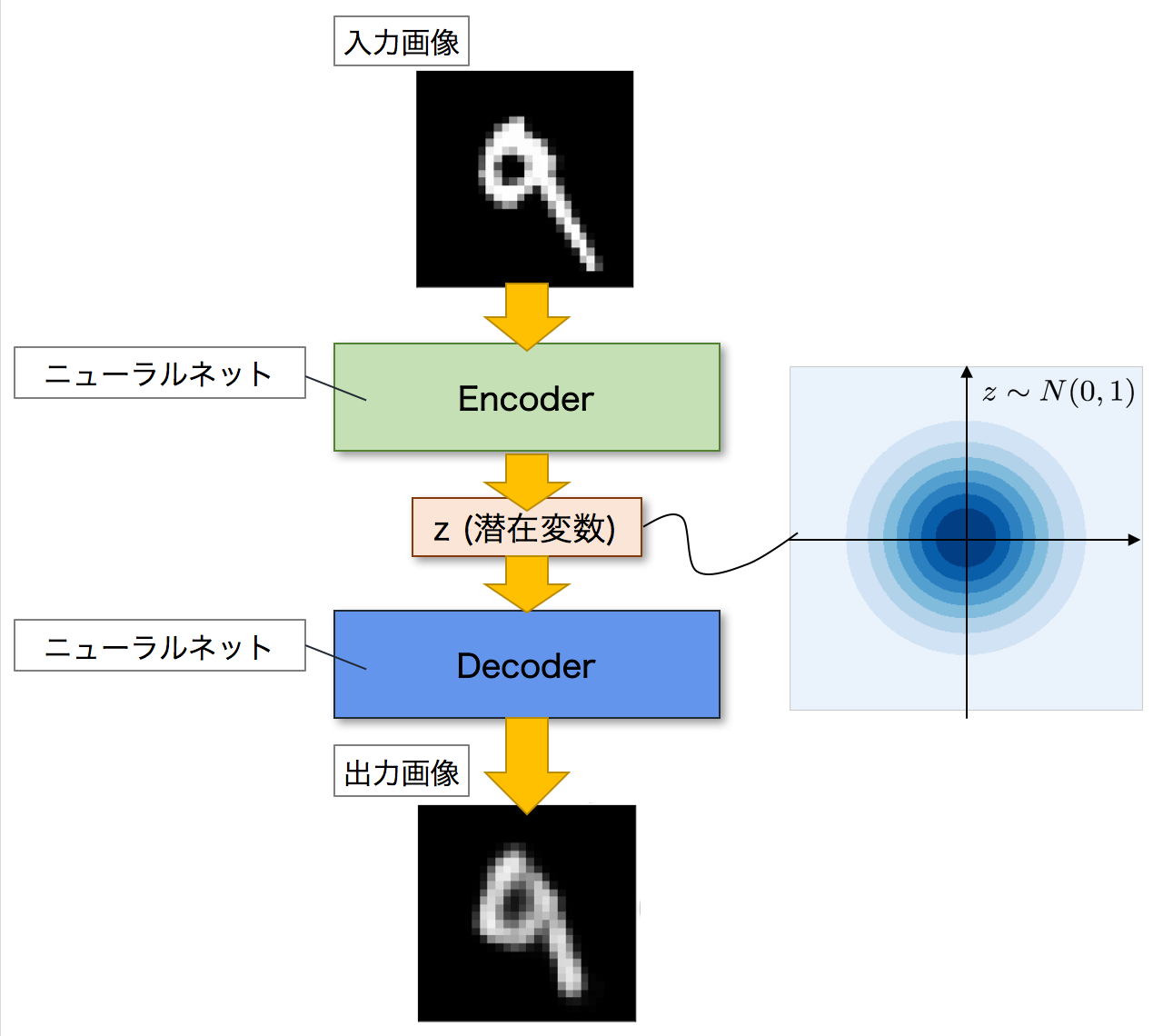
VAEがAutoencoderと異なるのは,潜在変数zの分布です.Autoencoderでは,潜在変数zにデータが押し込められますが,その分布については詳細はわかりません.一方で,VAEの場合には,潜在変数zに同じようにデータを押し込めますが,その分布が特定の確率分布に従うことを仮定しています.つまり,潜在変数zがどのような分布をしているのかが分かるということです.
VAEは生成モデルなので,学習を終えた後は,新しく画像を生成することができます.その際,Decoderに潜在変数zを入力して画像を生成しますが,この時に潜在変数zがどのような分布をしているのかがわかれば,生成する画像を細かくコントロールすることができます.
例えばmnistであれば,そのデータには0~9までの10種類の数字が含まれます.VAEを使ってmnistのデータを学習することで,潜在変数zのうち,ある領域には0,ある領域には1,そして別の領域には他の数字が含まれるようになります.以下の画像は,実際に潜在変数zの分布を可視化した画像です.画像右上の領域には0が,左下の領域には1が含まれていることがわかります.

(https://github.com/ChengBinJin/VAE-Tensorflow より引用)
そのため,もしこのVAEを使って0という数字を生成したければ,0が含まれる領域から潜在変数zを選べばいいことになります.上の画像で言えば,右上の潜在変数zを選べば良いわけです.この時,VAEであれば潜在変数zの分布がわかるので,狙った数字を生成しやすくなるのです.この点が,VAEがAutoencoderよりも優れている点になります.
GAN
GANも生成モデルの一種です.そのためVAEと同じように,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.また,NVIDIA Canvasのように,ある入力を別の入力へと変換することもできます.
GANがVAEと大きく異なる点は,その学習方法にあります.GANは,日本語では敵対的生成ネットワークと訳されますが,その名の通り,GANでは「敵対的」に学習が進んでいきます.「敵対的に」学習が進む,とはいったいどういうことなのでしょうか.
GANの構造を以下の画像に示します.GANは,GeneratorとDiscriminatorという2つのネットワークで構成されます.Generatorは,データを生成するネットワークです.Discriminatorは,Generatorが生成した偽物のデータと本物の学習データに対して,どちらが本物のデータであるかを識別します.この2つのネットワークを交互に学習していくことで,Generatorはより本物に近いデータを生成できるようになり,Discriminatorは本物・偽物をより正確に判断することができるようになっていきます.この時,GeneratorとDiscriminatorがお互い競い合うように学習していくため,「敵対的」と呼ばれているのです.
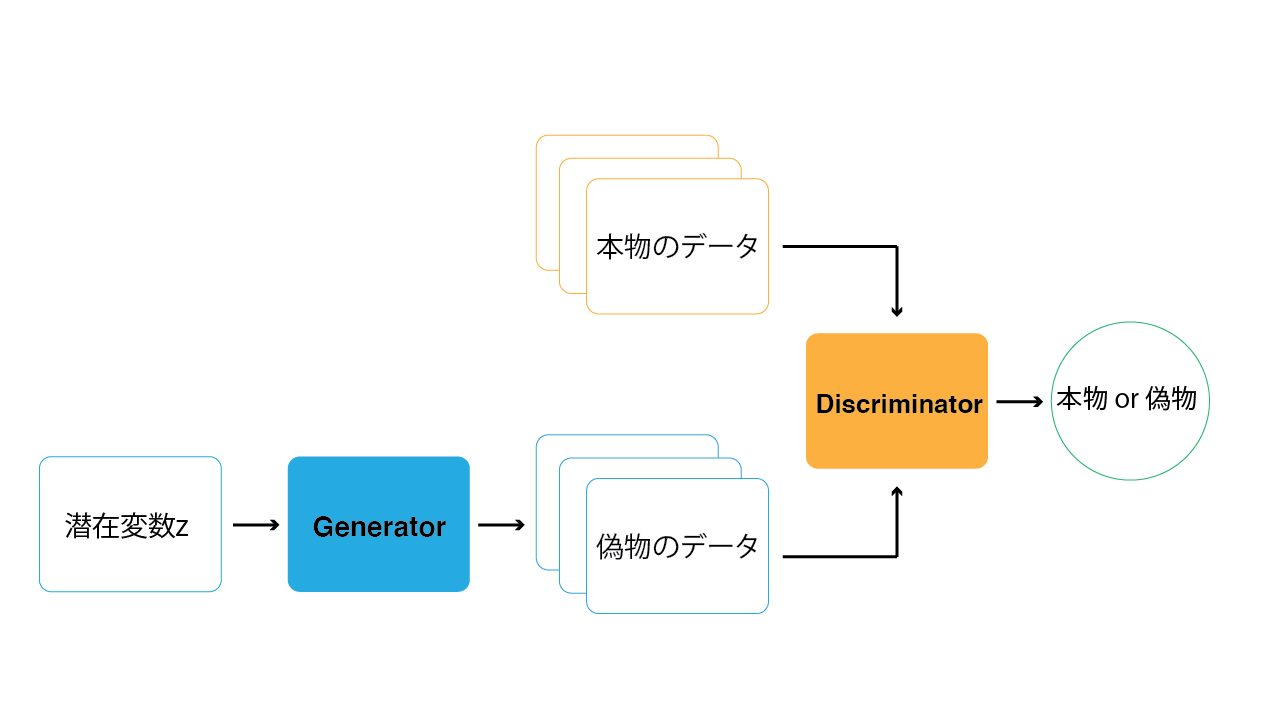
このGeneratorとDiscriminatorの関係は,よく紙幣の偽造に例えられます.偽札の作成者 (Generator) はなるべく本物に近い紙幣を作ろうとし,警察官 (Discriminator) はより正確に偽札を見分けようとします.そしてお互い交互に学習していくことで,最終的に偽札の作成者は本物とほぼ区別のつかない偽札を作れるようになっていきます.
この学習方法のおかげで,GANはVAEと比べてより鮮明な画像を生成することができます.一方で学習が難しいという問題もありますが,それを改善するために様々な研究が行われています.はじめに紹介した「This Person Does Not Exist」や「NVIDIA Canvas」もGANを使用したサービスです.
他にもGANを活用したサービスとして,Artbreederというサイトを紹介します.Artbreederは,AIを用いて様々な画像を生成することができるサービスです.
人物画像やアニメキャラ,風景画やクリーチャーなど,多種多様な画像を生成することができます.
また,Artbreederでは生成した画像に対して,パラメータを操作することで自由に編集を行うことができます.
実践学習編
フレームワーク
深層学習に使用するフレームワークは有名なものでいうと以下のようにリストアップできます.
- TensorFlow
- Keras
- PyTorch
- Caffe
- Microsoft Cognitive Toolkit
- MxNet
- Chainer
TensorFlowはGoogleによって提供されているフレームワークとして有名です.他にもアカデミックなプロジェクトが多いPyTorchなど,ライブラリごとに特有の便利な関数があったりと多少異なりします.
使用する環境

今回はwebで駆動するよう設計されたTensorFlow.jsがベースで駆動していて,かなり簡略化されたライブラリであるml5.jsを用います.
また,ml5.jsはp5.jsの影響を受けて制作されているので,p5.jsを理解していれば,即使うことができます.
p5.jsの実行サービスですが,今回はGlitchを使ってみます.Glitchはウェブブラウザ簡潔のアプリ開発環境で,Nodeなどのバーバーサイドスクリプトなども構築可能です.
まずは,アカウントを作りましょう.
私はGithubのアカウントでサインインしてしまっています.
プロジェクトをRemixする
自身のプロジェクトとしてコードを編集するために必ず下のテンプレートプロジェクトをRemixしてください.その後,プロジェクト名が適当な名前で生成されるため,自身の決めたい名前に変更します.
最低限のコード
p5.jsのロジックを最低限理解するためのコードを添付しておきます.
各自必要であれば復習してみてください.
Teachable Machine
Teachable Machineはこれまで説明してきた画像分類タスクについて,驚くほど簡単に学習ができるようにしたサービスです.
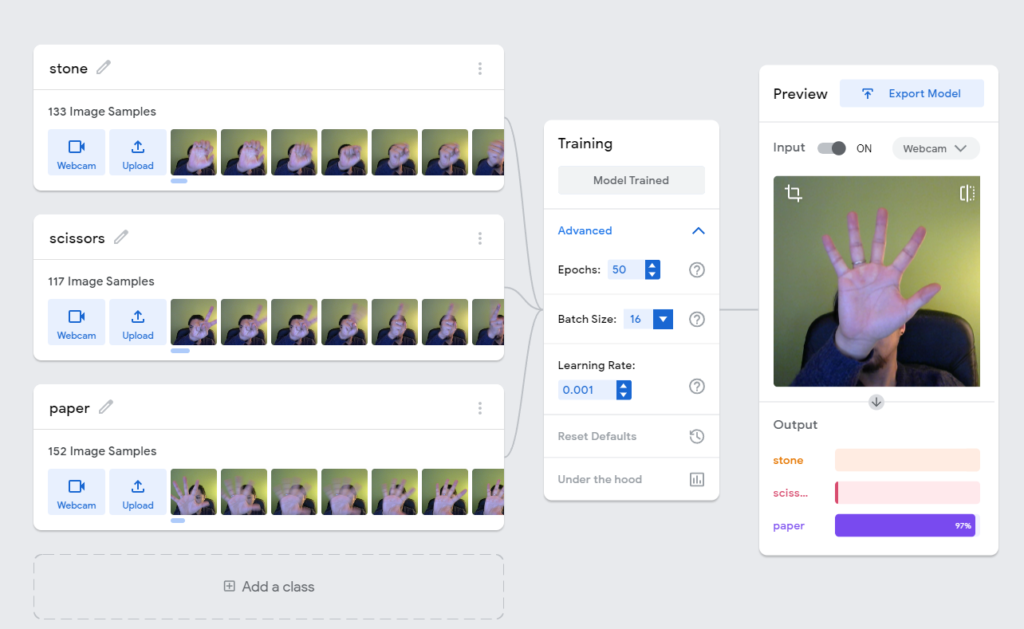
本当に簡単に学習できてしまうので,さっそくアクセスしてみましょう.
https://teachablemachine.withgoogle.com/
データセット
データセットとは深層学習に与えるデータの集合です.識別モデルでは正解ラベルとデータ(画像,文字列など)がセットになっています.
Teachable MachineではClass1と書かれているところがラベルとなり,データセットはウェブカメラでリアルタイムに画像の連番をデータセットとしてストックすることができます.
通常は画像をウェブ上でスクレイピングしたり,ラベルのデータをjson形式で書いたりなどと,何かと準備が大変な深層学習ですが,このようにプロセスを簡易化することで作り出す結果やプロセスの理解に集中できます.
学習時のパラメータ
学習のパラメータは,Training>Advancedをクリックすることで出現します.たいていデフォルトのままで問題ないのですが,説明しておきます.
Epochs
ネットワークに全トレーニングデータを渡す回数です.
Batch Size
各訓練ステップでひとまとまりとして渡す観測数です.
小さいと細かい特徴を捉えられたり精度が上がる反面,局所的な観測に影響を受けてしまうことがあります.
大きいと平均化されますが,局所的な観測の影響は少なくなります.
今回は小さめの16にします.
Learning rate
正解との差分(損失)を無くす方向に調整するときの割合です.
大きすぎると最適な重みを一気に通り過ぎてしまうリスクがあり,小さすぎても局所解に影響を受けて学習が進まなくなる可能性があります.
学習したモデルで推論する
Glitch内,sketch.jsのコードは以下のとおりです.
let conf;
let video;
let label = "Loading...";
let classifier;
let modelURL = 'https://teachablemachine.withgoogle.com/models/JR70YXkBa/';
// imageClassifierオブジェクトを生成,引数はモデル
function preload() {
classifier = ml5.imageClassifier(modelURL + 'model.json');
}
function setup() {
createCanvas(640, 480);
video = createCapture(VIDEO);
video.hide();
// クラス分けする関数を実行
classifyVideo();
}
// クラス分けする関数. 引数は画像,クラス分け完了時に実行されるコールバック
function classifyVideo() {
classifier.classify(video, gotResults);
}
function draw() {
background(0);
image(video, 0, 0);
textSize(64);
textAlign(CENTER, CENTER);
fill(255);
text(label, width / 2, height - 60);
text(conf, width / 2, height - 120);
}
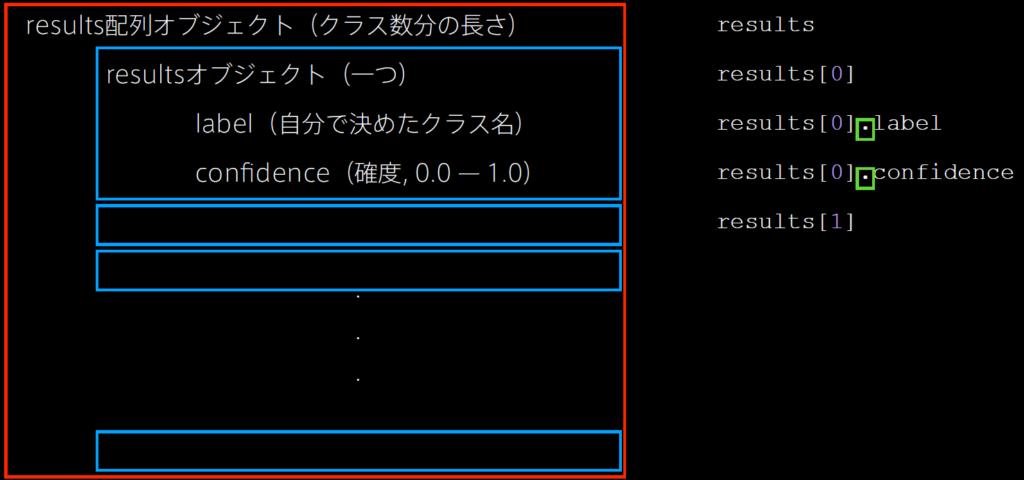
function gotResults(error, results) {
// クラス分けに何らかの理由で失敗したときはerrorメッセージを返す
if (error) {
console.error(error);
return;
}
// resultsオブジェクトのラベルを取得
label = results[0].label;
// resultsオブジェクトの確度を取得
conf = results[0].confidence;
// 小数点を第二位までに変更
conf = nf(conf, 0, 2);
// もう一度クラス分け(これによりクラス分けし続ける)
classifyVideo();
}
図のような構造を意識するとコードを書きやすいでしょう.
実践識別モデル編
様々な識別モデル
PoseNet
PoseNetは画素の情報から姿勢を推定するタスクです.

文字列で関節名を指定して,特定の関節に何か描いたりすることもできます.
対応する文字列は表の通りです.
| 関節名 | 対応文字列 |
|---|---|
| 左耳 | leftEar |
| 右耳 | rightEar |
| 左目 | leftEye |
| 右目 | rightEye |
| 鼻 | nose |
| 左肩 | leftShoulder |
| 右肩 | rightShoulder |
| 左肘 | leftElbow |
| 右肘 | rightElbow |
| 左手首 | leftWrist |
| 右手首 | rightWrist |
| 左尻 | leftHip |
| 右尻 | rightHip |
| 左膝 | leftKnee |
| 右膝 | rightKnee |
| 左かかと | leftAnkle |
| 右かかと | rightAnkle |
パーツの場所の対応は画像の通りです.
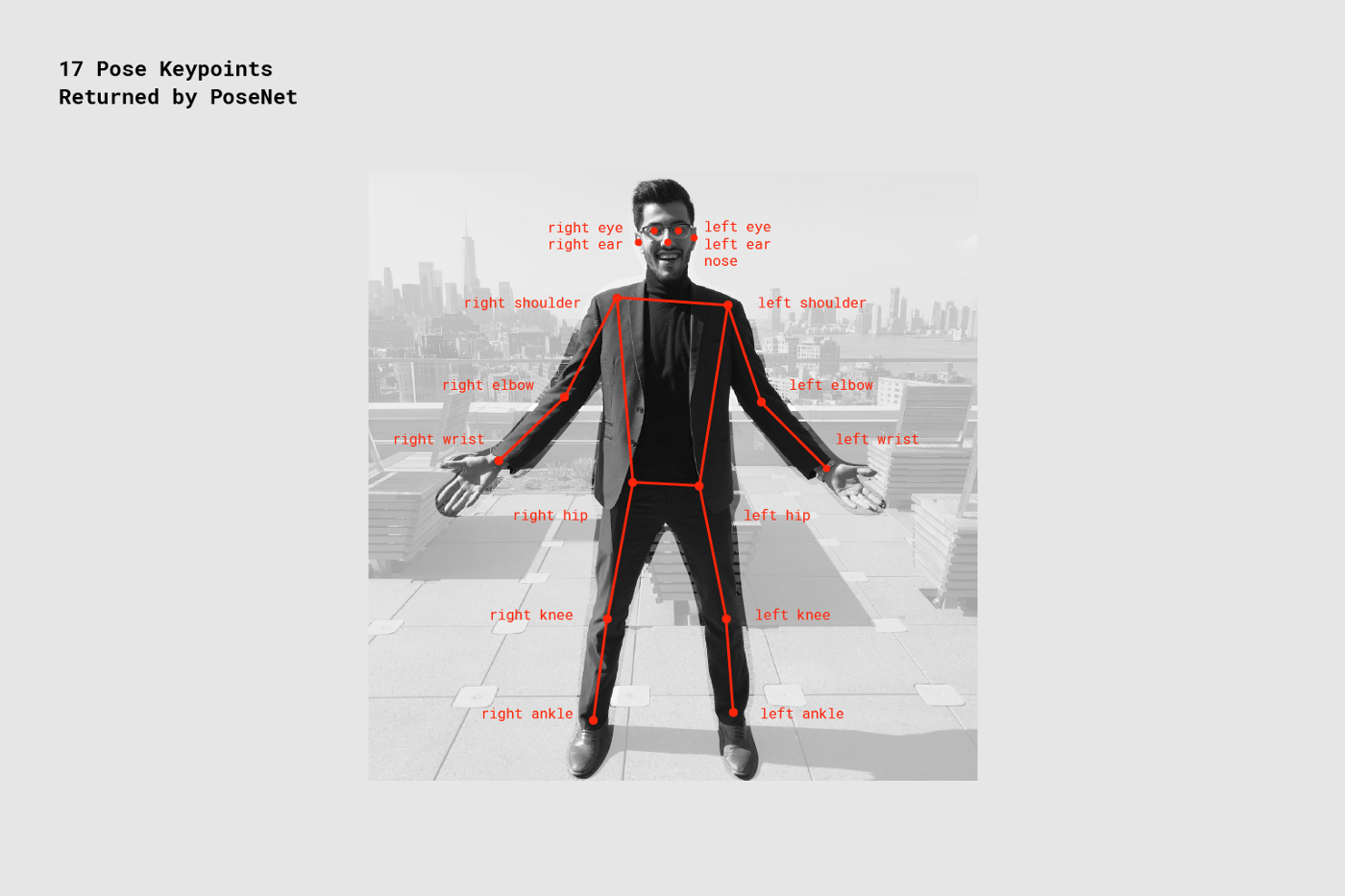
Glitchのsketch.jsのコードは以下のとおりです.
let video;
let poseNet;
let poses = [];
function setup() {
createCanvas(640, 480);
video = createCapture(VIDEO);
video.size(width, height);
// PoseNetオブジェクトを生成する.引数は画像,model読み込み時に実行されるコールバック
poseNet = ml5.poseNet(video, modelReady);
// onメソッドは姿勢検出時に実行. poses配列に解析結果であるresultオブジェクトが渡される
poseNet.on('pose', function(results) {
poses = results;
});
video.hide();
noStroke();
fill(255, 0, 0);
}
function draw() {
background(0);
imageMode(CORNER);
//webcamera映像を描画
image(video, 0, 0, width, height);
for (let i = 0; i < poses.length; i++) {
let pose = poses[i].pose;
for (let j = 0; j < pose.keypoints.length; j++) {
let keypoint = pose.keypoints[j];
//keypoint.position.x, keypoint.position.yがそれぞれのパーツ位置
//keypoint.partはパーツ名
//ellipse(keypoint.position.x, keypoint.position.y, 10, 10);
//text(keypoint.part, keypoint.position.x, keypoint.position.y - 20);
//特定のパーツを文字列で指定する
if (keypoint.part == 'nose') {
imageMode(CENTER);
push();
translate(keypoint.position.x, keypoint.position.y - 40);
scale(0.2);
image(img, 0, 0);
pop();
}
}
// 一人目だけで強制的に脱出
break;
}
}
//select('#id')でidを指定し,.html('xx')で要素を書き換える
function modelReady() {
select('#status').html('Model Loaded');
}
function preload() {
img = loadImage('https://cdn.glitch.me/d3d7a77a-3bac-4645-8b46-2463714dd87b/sandglasses.png?v=1639782319583');
}
また,図のような構造を意識するとコードを書きやすいでしょう.

Handpose
Handposeでは手の関節を取得できます.
sketch.jsのコードは以下のとおりです.
let handpose;
let video;
let predictions = [];
function setup() {
createCanvas(640, 480);
video = createCapture(VIDEO);
video.size(width, height);
// Handposeオブジェクトを生成.
handpose = ml5.handpose(video, modelReady);
// onメソッドは検出時に実行.prediction配列に解析結果であるresultsオブジェクトが返される
handpose.on("predict", results => {
predictions = results;
});
video.hide();
}
function modelReady() {
console.log("Model ready!");
}
function draw() {
image(video, 0, 0, width, height);
drawKeypoints();
}
function drawKeypoints() {
for (let i = 0; i < predictions.length; i += 1) {
const prediction = predictions[i];
for (let j = 0; j < prediction.landmarks.length; j += 1) {
const keypoint = prediction.landmarks[j];
fill(0, 255, 0);
noStroke();
ellipse(keypoint[0], keypoint[1], 10, 10);
}
}
}
BodyPix
BodyPixは人の体のパーツごとにセグメンテーションできます.
sketch.jsのコードは以下のとおりです.
let bodypix;
let video;
let segmentation;
const options = {
outputStride: 8, // 8, 16, or 32, default is 16
segmentationThreshold: 0.3, // 0 - 1, defaults to 0.5
};
function preload() {
bodypix = ml5.bodyPix(options);
}
function setup() {
createCanvas(640, 480);
// load up your video
video = createCapture(VIDEO, videoReady);
video.size(width, height);
video.hide();
}
function videoReady() {
bodypix.segment(video, gotResults);
}
function draw() {
background(0);
if (segmentation) {
image(segmentation.backgroundMask, 0, 0, width, height);
}
}
function gotResults(error, result) {
if (error) {
console.log(error);
return;
}
segmentation = result;
bodypix.segment(video, gotResults);
}
Object Detection
Object Detectionはどのエリア(バンディングボックス)にどのクラスがあるか取得できます.
今回はYOLOを使用します.
sketch.jsのコードは以下のとおりです.
let video;
let yoloModel;
let modelStatus;
let title;
let objects = [];
function setup() {
modelStatus = createElement("h2", "status: loading model");
let c = createCanvas(800, 600);
video = createCapture(VIDEO);
video.size(800, 600);
// YOLOのオブジェクトを生成
yoloModel = ml5.YOLO(video, { classProbThreshold: 0.1 }, modelLoaded);
video.hide();
}
function draw() {
image(video, 0, 0, width, height);
for (let i = 0; i < objects.length; i++) {
const currObj = objects[i];
const posx = currObj.x * video.width;
const posy = currObj.y * video.height;
const boxw = currObj.w * video.width;
const boxh = currObj.h * video.height;
const label = currObj.label;
const confidence = currObj.confidence;
if (confidence > 0.2) {
noStroke();
fill(0, 255, 0);
text(label + " " + nfc(confidence * 100.0, 2) + "%", posx + 5, posy + 15);
noFill();
strokeWeight(4);
stroke(0, 255, 0);
rect(posx, posy, boxw, boxh);
}
}
}
function modelLoaded() {
modelStatus.html("Model loaded!");
detectLoop(); // call detection loop
}
function yoloResults(error, results) {
if (results) {
console.log(results)
objects = results;
detectLoop();
}
}
function detectLoop (){
yoloModel.detect(yoloResults);
}
サウンド連携編
オシレータとして決めた周波数のサイン波などを出すことが可能です.
Sound
Oscillator
let osci = [], freq = [261.626, 293.665, 329.628, 349.228, 391.995, 440.000, 493.883], amp = 1.0;
function setup() {
let cnv = createCanvas(100, 100);
}
function draw() {
background(220)
}
function playOscillator() {
osci.push(new p5.Oscillator('sine'));
osci.slice(-1)[0].freq(freq[int(random(7))], 0.05);
osci.slice(-1)[0].amp(amp, 0.1);
osci.slice(-1)[0].start();
osci.slice(-1)[0].amp(0, 1);
osci.pop();
}
function mouseReleased() {
playOscillator();
}
Sound file
音源をロードして,指定したタイミングで再生することも可能です.
let kick, hihat, snare;
function preload() {
soundFormats('mp3');
kick = loadSound('https://cdn.glitch.me/54f1c815-3ac0-4f3a-a6a6-5a04df6dcf19/kick.mp3?v=1639777740827');
hihat = loadSound('https://cdn.glitch.me/54f1c815-3ac0-4f3a-a6a6-5a04df6dcf19/hihat.mp3?v=1639777740827');
snare = loadSound('https://cdn.glitch.me/54f1c815-3ac0-4f3a-a6a6-5a04df6dcf19/snare.mp3?v=1639777741056');
}
function setup() {
createCanvas(300, 100);
textAlign(CENTER, CENTER);
textSize(20);
}
function draw() {
background(220);
line(width / 3, 0, width / 3, height);
line(2 * width / 3, 0, 2 * width / 3, height);
text('kick', width / 6, height / 2);
text('hihat', width / 2, height / 2);
text('snare', 5 * width / 6, height / 2);
}
function mouseReleased() {
if (mouseX < 100) kick.play();
else if (mouseX >= 100 && mouseX < 200) hihat.play();
else snare.play();
}