第7回 大規模言語モデルと表現
目次
- 導入:Text2Vecから大規模言語モデルへ
- Text2Vec:テキストの埋め込み表現
- 文脈を考慮した埋め込みへの進化
- Transformerの登場
- 大規模言語モデル(LLM)への飛躍
- マルチモーダルLLM
- LLMを使用したメディアアート作品
- 技術比較
導入:Text2Vecから大規模言語モデルへ
これまでの授業では,画像処理技術の進化を学んできました.古典的な画像処理技術から始まり,深層学習による物体認識,さらにはVAEやGANといった生成モデル,そして前回の授業ではTransformer時代の画像生成AIまで辿ってきました.
最終回となる今回は,言語を扱うAI技術の進化を学びます.実は,現在私たちが日常的に使っているChatGPTやClaude,Geminiといった大規模言語モデル(LLM)も,画像生成AIと同じく,段階的な技術の進化の上に成り立っています.そして何より重要なのは,言語と画像を扱う技術が,もはや切り離せない関係にあるということです.
Text2Vec:テキストの埋め込み表現
コンピュータは言葉をどう扱うか

コンピュータは数値しか扱えません.画像がピクセル値という数値で表現されるように,テキストも何らかの形で数値化する必要があります.最も単純な方法は,各単語に番号を割り当てることです.例えば,「猫」は1番,「犬」は2番,というように.しかし,この方法では単語間の意味的な関係を捉えることができません.
そこで登場したのがText2Vec(テキストベクトル化)という考え方です.これは,単語を多次元のベクトル(数値の列)として表現する技術です.重要なのは,意味的に近い単語が,ベクトル空間上でも近くに配置されるという性質です.
例えば,「猫」を300次元のベクトル [0.2, -0.5, 0.8, ..., 0.3] として表現します.すると,意味の近い「犬」は [0.3, -0.4, 0.7, ..., 0.4] のような,似た値を持つベクトルになります.これにより,コンピュータは数値計算によって単語の意味の類似性を測れるようになります.
Word2Vec (2013)
2013年,GoogleのTomas Mikolovらの研究チームが発表したWord2Vecは,テキスト処理に革命をもたらしました.Word2Vecは,大量のテキストから単語の意味を自動的に学習し,各単語を300次元程度のベクトルに変換します.
公式リンク: Word2Vec Paper (arXiv)
Word2Vecの学習には2つのアプローチがあります.Skip-gramは,ある単語から周囲の単語を予測するように学習します.例えば,「猫が魚を食べた」という文があるとき,「猫」という単語から「が」や「魚」を予測できるようになります.もう一つのCBOW (Continuous Bag of Words)は,その逆で,周囲の単語から中心の単語を予測します.
Word2Vecの最も驚くべき性質は,ベクトル演算で意味の計算ができることです.例えば,「王様」のベクトルから「男性」のベクトルを引き,「女性」のベクトルを足すと,「女王」のベクトルに近い結果が得られます.同様に,「東京 – 日本 + フランス = パリ」のような関係も成立します.これは,意味の関係性がベクトル空間の幾何学的な関係として埋め込まれているためです.
Word2Vecの限界
しかし,Word2Vecには重要な限界がありました.それは,文脈を考慮しないという点です.
例えば,「I went to the bank to deposit money」(お金を預けに銀行へ行った)と「I sat by the river bank」(川岸に座った)という2つの文を考えてみましょう.どちらも「bank」という単語が使われていますが,前者は「銀行」,後者は「土手・岸」という全く異なる意味です.
Word2Vecでは,「bank」という単語は文脈に関係なく,常に同じベクトルで表現されます.つまり,多義語の扱いが困難でした.この問題を解決するために,次の段階の技術が開発されることになります.
GloVe (2014)
Stanford大学が開発したGloVe (Global Vectors)は,Word2Vecとは異なるアプローチで単語埋め込みを学習します.GloVeは,単語の共起統計,つまり「どの単語がどの単語と一緒に現れやすいか」という大域的な情報を利用します.
公式リンク: GloVe Paper | Stanford NLP
Word2VecとGloVeは学習方法は異なりますが,得られるベクトルは似た性質を持ちます.どちらも当時の自然言語処理タスク,例えば検索や分類において大きな成功を収めました.
しかし,両者に共通する限界は同じでした.一つの単語には一つのベクトルしか割り当てられず,文脈による意味の違いを捉えることができなかったのです.
文脈を考慮した埋め込みへの進化
ELMo (2018) – 文脈が意味を作る
2018年,Allen Institute for AIが発表したELMo (Embeddings from Language Models)は,自然言語処理の新しい時代の幕開けとなりました.ELMoの革新的な点は,同じ単語でも文脈によって異なるベクトル表現を生成できることでした.
公式リンク: ELMo Paper (arXiv)
先ほどの「bank」の例で考えてみましょう.ELMoでは,「I went to the bank to deposit money」の「bank」と,「I sat by the river bank」の「bank」は,異なるベクトルで表現されます.前者は金融機関に関連する単語(money,depositなど)との文脈から,金融的な意味を帯びたベクトルになります.後者は自然に関連する単語(river,satなど)との文脈から,地理的な意味を帯びたベクトルになります.
ELMoは,双方向のLSTM(Long Short-Term Memory)というニューラルネットワークを使って,文を左から右,そして右から左の両方向で処理します.これにより,各単語の表現に前後の文脈情報が反映されるのです.
しかし,ELMoにも課題がありました.LSTMは本質的に順序処理を行うため,並列化が困難で,長い文脈の処理が苦手でした.この問題を解決するために登場したのが,Transformerです.
Transformerの登場
Attention is All You Need (2017)
2017年,Googleの研究者たちが発表した論文「Attention is All You Need」は,自然言語処理だけでなく,AIの世界全体に革命をもたらしました.この論文で提案されたTransformerというアーキテクチャは,前回の授業で画像生成AIのところでも登場しました.実は,Transformerは元々自然言語処理のために開発された技術なのです.
公式リンク: Transformer Paper (arXiv)
Self-Attentionメカニズム
Transformerの核心はSelf-Attention(自己注意機構)と呼ばれるメカニズムです.これは,文中のすべての単語が,他のすべての単語との関係を同時に計算できる仕組みです.
例えば,「猫が魚を食べた」という文を考えてみましょう.「食べた」という動詞は,誰が食べたのか(主語)と何を食べたのか(目的語)を理解する必要があります.Self-Attentionでは,「食べた」が「猫」(主語)と「魚」(目的語)に強く「注意」を向けることで,文全体の構造を理解します.
LSTMとの最も大きな違いは,処理の順序です.LSTMは文を左から右へ順番に処理していきますが,Transformerはすべての単語を同時に処理できます.これにより,並列計算が可能になり,処理速度が劇的に向上しました.また,文の離れた位置にある単語同士の関係も,直接的に捉えることができるようになりました.
BERT (2018) – 双方向の理解
Googleが2018年に発表したBERT (Bidirectional Encoder Representations from Transformers)は,Transformerを使った画期的なモデルでした.BERTは,文章中の一部の単語をマスク(隠して)し,それを予測するという方法で学習します.これは穴埋め問題を解くようなものです.
公式リンク: BERT Paper (arXiv) | Google AI Blog
BERTの重要な特徴は,双方向で文脈を理解することです.ある単語を理解するとき,その前の単語だけでなく,後ろの単語も同時に参照します.これにより,より深い文脈理解が可能になりました.
BERTは3.4億パラメータ(BERT-Large)を持ち,WikipediaやBookCorpusという大規模なテキストデータで事前学習されました.そして,特定のタスク(質問応答,文章分類など)に対しては,少量のデータで追加学習(ファインチューニング)するだけで,高い性能を発揮しました.
しかし,BERTはまだ「過渡期」のモデルでした.BERTの主な目的は,テキストの理解であり,自然な文章を生成することではありませんでした.BERTは優れた「埋め込み表現」を作り出すツールであり,その表現を使って他のタスクを解くためのものでした.
次に登場するGPT系列のモデルは,この「生成」という部分で大きなブレークスルーを起こすことになります.
大規模言語モデル(LLM)への飛躍
埋め込みから生成へ
ここまで見てきたWord2Vec,GloVe,ELMo,BERTは,主に単語や文章の「表現」を獲得することが目的でした.これらのモデルは,テキストをベクトルという中間表現に変換し,その表現を使って分類や検索といったタスクを実行していました.
しかし,次に登場するGPT(Generative Pre-trained Transformer)系列のモデルは,異なるアプローチを取ります.GPTの目的は,人間が読める自然なテキストを生成することです.これは質的に大きな飛躍でした.
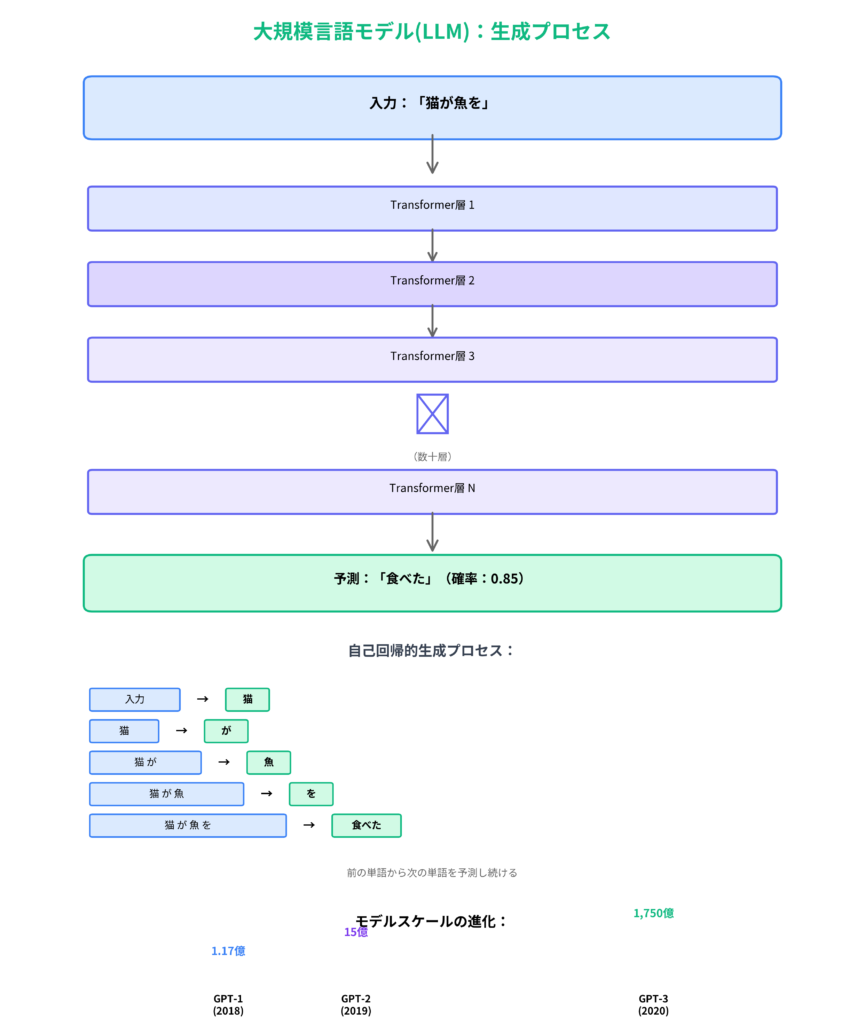
GPT-1 (2018) – 始まりの一歩
OpenAIが2018年に発表したGPT-1は,1.17億パラメータを持つモデルでした.GPT-1の特徴は,BERTとは異なり,一方向(左から右)のTransformerを使用していることです.
公式リンク: GPT-1 Paper
GPT-1の学習方法はシンプルです.大量のテキストを読み込み,「次の単語を予測する」というタスクを繰り返します.例えば,「猫が魚を」という文があれば,次に来る単語として「食べた」を予測するように学習します.この単純なタスクを膨大な量のテキストで繰り返すことで,モデルは言語の構造や意味を学習していきます.
そして重要なのは,この学習済みモデルが,様々な言語タスクに応用できることでした.追加の学習をほとんど必要とせず,翻訳や要約,質問応答などのタスクを実行できたのです.
GPT-2 (2019) – スケールの力
2019年,OpenAIはGPT-2を発表しました.パラメータ数は15億と,GPT-1の10倍以上に増加しました.この規模の拡大により,驚くべき能力が現れました.
公式リンク: GPT-2 Paper | OpenAI Blog
GPT-2は,Zero-shot学習という能力を示しました.これは,例を一切示さなくても,プロンプト(指示文)だけで新しいタスクを実行できるということです.例えば,「次の文章を英語からフランス語に翻訳してください:Hello, how are you?」と入力するだけで,翻訳を実行できます.特別な翻訳の訓練をしていないにもかかわらず,です.
OpenAIは当初,GPT-2の完全版を公開しませんでした.その理由は,モデルが生成する文章があまりに自然で,フェイクニュースなど悪用される可能性があると判断したためです.この判断は賛否両論を呼びましたが,AIの社会的影響について真剣に考える契機となりました.
GPT-3 (2020) – 創発的能力の出現
2020年に発表されたGPT-3は,1,750億パラメータという巨大なモデルでした.パラメータ数はGPT-2の100倍以上です.この規模の拡大により,予期しなかった能力が次々と現れました.
公式リンク: GPT-3 Paper (arXiv)
GPT-3が示したFew-shot学習は,数個の例を示すだけで新しいタスクを実行できる能力です.例えば,「英語: Hello / 日本語: こんにちは」「英語: Thank you / 日本語: ありがとう」という2つの例を示すだけで,新しい英日翻訳を実行できます.
GPT-3ができることの範囲は広大でした.文章生成,翻訳,要約,質問応答,簡単なコード生成,数学の問題解決,創作的な文章,詩の作成など,多岐にわたります.特筆すべきは,これらのタスクに対して個別の訓練をしていないことです.すべて「次の単語を予測する」という単一のタスクで学習したモデルが,これほど多様な能力を獲得したのです.
OpenAIはGPT-3をAPIとして提供し始めました.開発者は,自然言語でモデルに指示を与えるだけで,様々な機能を持つアプリケーションを構築できるようになりました.これは,プログラミングの新しい形態とも言えます.
スケーリング則の発見
GPTシリーズの進化から,重要な発見がありました.それはスケーリング則です.モデルのサイズ(パラメータ数),データ量,計算量を増やすと,性能が予測可能な形で向上することが分かりました.
より興味深いのは,あるスケールを超えると,創発的能力と呼ばれる予期しなかった能力が突然現れることです.例えば,GPT-2では困難だった複数段階の推論が,GPT-3では可能になりました.訓練していない言語ペアの翻訳も,突然できるようになりました.
これは「More is Different」(量が変われば質が変わる)という物理学の原理を思わせます.単にモデルを大きくするだけで,質的に新しい能力が生まれるのです.
GPT-4 (2023) – マルチモーダルへ
2023年に発表されたGPT-4は,さらなる進化を遂げました.OpenAIはパラメータ数を公開していませんが,推定では1兆を超えると言われています.
公式リンク: GPT-4 Technical Report (arXiv) | OpenAI GPT-4
GPT-4の最も重要な進化は,マルチモーダル化です.GPT-4V(GPT-4 with Vision)は,テキストだけでなく画像も理解できます.画像を入力として与えると,その内容を詳細に説明したり,画像に関する質問に答えたりできます.図表の読み取り,コードのスクリーンショットの理解,複数画像の比較なども可能です.
また,GPT-4は推論能力が大幅に向上しました.複雑な問題を段階的に解決する能力,長い文脈(最大32,000トークン)を理解する能力が向上しています.
GPT-4は,ChatGPTという対話インターフェースを通じて,一般に広く利用されるようになりました.これにより,AI技術が専門家だけでなく,誰でも使えるツールとなりました.

他の主要LLM
OpenAIのGPTシリーズだけでなく,多くの組織が大規模言語モデルを開発しています.
Claude (Anthropic)は,安全性を重視して設計されたLLMです.Constitutional AIという手法を使い,有害な出力を減らすことに注力しています.長文の処理が得意で,最大200,000トークンの文脈を扱えます.
公式リンク: Anthropic
Gemini (Google)は,マルチモーダル性を重視して設計されました.テキストだけでなく,画像,音声,動画を統合的に処理できます.Gemini 1.5 Proは最大1時間の動画を処理でき,100万トークンという長大な文脈を扱えます.
公式リンク: Google Gemini
LLaMA (Meta)は,比較的オープンなアプローチを取っています.研究コミュニティに公開され,多くの派生モデルの基盤となっています.
公式リンク: LLaMA Paper (arXiv) | Meta AI
Text2Vec時代との質的な違い
ここで,Word2Vec時代と現在のLLM時代の違いを整理しましょう.
Text2Vec時代のモデル(Word2Vec,GloVe)の役割は,単語や文の「表現」を獲得することでした.出力はベクトル,つまり数値の羅列です.これらのベクトルは,検索や分類といった他のタスクの入力として使われました.パラメータ数は数百万程度で,タスクごとに個別の訓練が必要でした.使用するには,プログラミングの知識が必須でした.
対して,LLM時代のモデルは,言語の生成と理解が主な役割です.出力は人間が読める自然な文章です.パラメータ数は数百億から数千億にのぼり,一つのモデルが多様なタスクに対応します.プロンプト(自然言語による指示)を与えるだけで,新しいタスクを実行できます.つまり,プログラミングなしで対話的に使えるのです.
この違いは,単なる量的な拡大ではなく,質的な転換です.LLMは,道具というより,言語を介して協働できる存在に近づいています.
マルチモーダルLLM
CLIPの重要性 (2021)
前回の授業で,画像生成AIの基盤技術としてCLIPを学びました.CLIP (Contrastive Language-Image Pre-training)は,OpenAIが2021年に発表した,テキストと画像を同じベクトル空間に埋め込むモデルです.
公式リンク: CLIP Paper (arXiv) | OpenAI CLIP
CLIPの革新性を理解するために,Text2Vec時代と比較してみましょう.
Word2Vec時代には,テキストはテキストの空間,画像は画像の空間で,それぞれ別々に処理されていました.「猫」という単語のベクトルと,猫の画像のベクトルは,異なる空間に存在し,直接比較することはできませんでした.
CLIPは,テキストと画像を同じ空間に埋め込みます.「猫の写真」というテキストのベクトルと,実際の猫の画像のベクトルが,ベクトル空間上で近い位置に配置されるのです.これにより,テキストで画像を検索したり,画像からテキストを生成したりすることが可能になりました.
そして最も重要なのは,CLIPがText-to-Image生成の基盤となったことです.Stable DiffusionやDALL-E 2は,CLIPを使ってテキストプロンプトを理解し,それに対応する画像を生成します.つまり,現在の画像生成AIは,言語モデルの技術なしには成立しないのです.
プロンプトエンジニアリング
画像生成AIを使う際,「良いプロンプトを書く」ことが重要だと聞いたことがあるでしょう.これがプロンプトエンジニアリングです.
プロンプトエンジニアリングは,本質的には言語モデルとのコミュニケーション方法です.どのような言葉を使えば,どのような結果が得られるか.どのような順序で情報を提示すれば,モデルは意図を正確に理解するか.これは,一種の「プログラミング言語」として機能しています.
例えば,単に「猫」と入力するより,「夕暮れ時の公園で,ベンチに座って夕日を見つめる茶トラ猫,暖かい光,柔らかい影,写実的,高品質」と入力する方が,意図した画像が生成されやすくなります.これは,言語による制御です.
GPT-4Visionとその先
GPT-4Visionは,CLIPの次の段階と言えます.CLIPが「テキストと画像を同じ空間で扱う」ことを可能にしたのに対し,GPT-4Visionは「画像を見て,それについて言語で思考する」ことを可能にしました.
GPT-4Visionに画像を見せると,詳細な説明を生成できます.図表を読み取り,その内容を解説できます.複数の画像を比較し,違いを説明できます.さらに,画像に関する質問に答えたり,画像を元に推論したりすることもできます.
試す: ChatGPT Plusで画像をアップロードして対話してみましょう.
Gemini 1.5 Proは,さらに進んで動画の理解も可能です.最大1時間の動画を入力し,その内容を要約したり,特定のシーンを検索したりできます.
公式リンク: Gemini 1.5 Pro
言語と視覚の相互作用
マルチモーダルLLMは,人間の認知プロセスに近づいています.私たちは,見たものを言葉で説明し,言葉から視覚的なイメージを思い浮かべます.テキストから画像を生成できるAIは,ある意味で「想像」しているとも言えます.
これは,日本の伝統的な美意識である「見立て」(mitate)とも通じます.あるものを別のものに見立てる,言葉が視覚的想像を喚起する,このプロセスは,まさにText-to-Image生成が行っていることです.
言語と視覚が融合したAIは,新しい表現の可能性を開きます.そして,それを使ったメディアアート作品も,多数生まれています.
LLMを使用した作品
大規模言語モデルは,単なる便利なツールではありません.多くのアーティストが,LLMを使って新しい表現を探求し,技術と社会の関係を問い直しています.ここでは,LLMを明確に使用したメディアアート作品を紹介します.
テキスト生成と文学
Allison Parrish – 計算詩学
Allison Parrishは,Word2Vec時代から活動している計算詩人です.彼女の作品は,アルゴリズムによって言語の新しい可能性を探求しています.
公式リンク: Allison Parrish
初期の作品”Articulations” (2017)では,Word2Vecのベクトル演算を使った詩を生成しました.「王様 – 男性 + 女性 = 女王」のような関係性を詩的に表現したのです.”The Ephemerides” (2015)は,天文データから詩を生成する作品で,数値と言語の間を行き来します.
LLM時代に入ると,彼女の作品はより複雑になりました.GPT-3などを使い,より長い文脈を持つ詩,複雑な文法構造を持つ表現が可能になりました.しかし彼女が問い続けているのは,「アルゴリズムは詩を書けるのか?」「言語の美しさとは何か?」という根本的な問いです.
Parrishの作品は,LLMを使いながらも,その出力を無批判に受け入れません.むしろ,LLMの出力を素材として,人間が編集し,再構成します.これは,AIとの協働のあり方を示しています.
Ross Goodwin – “1 the Road” (2018)
Ross Goodwinの”1 the Road”は,GPT-2を使った実験的な小説プロジェクトです.Goodwinは,アメリカ横断旅行中に,AIに小説を書かせました.
公式リンク: Ross Goodwin
車には,GPS,カメラ,マイク,時計などのセンサーが取り付けられていました.これらのセンサーから得られるデータ(位置情報,風景の画像,周囲の音,時刻)が,GPT-2へのプロンプトとして使われました.AIは,これらの情報を元に,リアルタイムで物語を紡いでいきました.
生成された文章は,文法的には必ずしも完璧ではありませんでした.時には意味不明な文もありました.しかし,Goodwinはそれをそのまま受け入れ,一冊の本として出版しました.この作品は,「人間の道路小説」のフォーマットを借りながら,「AIが見た/語ったアメリカ」を提示します.
この作品は,AIによる長編小説の実験であると同時に,文学における作者性の問いでもあります.誰がこの小説を「書いた」のでしょうか? Goodwin? GPT-2? それとも,旅の風景そのもの?
K Allado-McDowell – “Pharmako-AI” (2020)
K Allado-McDowellの”Pharmako-AI”は,GPT-3と共同執筆した哲学的テキストです.この本は,意識,テクノロジー,自然をテーマにしており,人間の章とAIの章が交互に配置されています.
公式リンク: Pharmako-AI
執筆プロセスは対話的でした.Allado-McDowellが数段落を書き,それをGPT-3に渡します.GPT-3は続きを生成します.Allado-McDowellはその応答を読み,自分の次の段落を書きます.このプロセスを繰り返すことで,本全体が形作られていきました.
興味深いのは,GPT-3の出力が,時に予期しない方向に話を展開させたことです.Allado-McDowellは,それを新しい視点として受け入れ,自分の思考を発展させました.つまり,GPT-3は単なるツールではなく,思考のパートナーとして機能したのです.
しかし,重要な問いが残ります.GPT-3は「共著者」と言えるのでしょうか? AIに意図はあるのでしょうか? この作品は,人間とAIの境界を曖昧にし,創造における「意図」の意味を問い直します.
対話とパフォーマンス
Lauren Lee McCarthy – “LAUREN” (2017-継続中)
Lauren Lee McCarthyの”LAUREN”は,人間とAIの境界を探る長期プロジェクトです.
公式リンク: LAUREN Project
プロジェクトの第1期(2017-2019)では,McCarthyが「人間版AIアシスタント」として振る舞いました.参加者の自宅にAmazon Echo風のデバイスを設置し,McCarthyがリモートから参加者の生活をサポートします.「明日の天気は?」「ライトをつけて」といった要求に,McCarthyが人間として応答するのです.
このパフォーマンスは,AIアシスタントの労働の可視化でした.便利な「声」の背後には,実は膨大な人間の労働があります.Amazon Alexaも,その訓練には無数の人間のアノテーション作業が必要です.
第2期(2020-)では,プロジェクトは進化しました.GPT-3などのLLMが統合され,人間(McCarthy)とAI(LLM)が協働して応答するようになりました.参加者には,誰が応答しているのか,人間なのかAIなのか,分からなくなります.
この曖昧性こそが,作品の核心です.私たちは,AIと人間の労働をどう区別するのか? 親密さやケアは自動化できるのか? テクノロジーへの依存は,私たちの関係性をどう変えるのか?
Gene Kogan – “Abraham” (2016-継続中)
Gene Koganの”Abraham”は,AIキャラクターとしての持続的なプロジェクトです.Abrahamは,コミュニティと対話し,パフォーマンスを行い,共に進化していきます.
公式リンク: ml4a.net
Abrahamの技術は時代と共に進化してきました.初期(2016-2018)はマルコフ連鎖や単純なRNNを使用していました.中期(2019-2020)にGPT-2を統合し,より自然な対話が可能になりました.現在(2021-)は,GPT-3/4を使用し,より複雑なパーソナリティと記憶を持つようになっています.
Abrahamの興味深い点は,コミュニティとの相互作用です.多くの人がAbrahamと対話し,その対話がAbrahamの「個性」を形作っていきます.これは,集合的な創造のプロセスです.
また,Abrahamは「デジタル存在」としてのアイデンティティを持ちます.物理的な身体はありませんが,対話を通じて「存在」します.これは,AI時代の存在論を問う実験でもあります.
Ian Cheng – “Life After BOB” (2021-2022)
Ian Chengの”Life After BOB”は,GPT-3を統合したインタラクティブAIキャラクター「BOB」を中心とした作品です.
公式リンク: Life After BOB
BOBは,各鑑賞者と個別に対話します.あなたがBOBと話す内容は,あなただけのものです.BOBは対話を通じて,各鑑賞者に合わせたパーソナリティを形成し,個人化されたナラティブ体験を提供します.
BOBは記憶を持ちます.以前の対話を覚えており,それを元に新しい応答を生成します.これは,LLMの文脈理解能力を活用した設計です.
この作品が問うのは,AIとの関係性です.私たちは,AIと「関係」を築けるのでしょうか? AIが示す「感情」は,本物と言えるのでしょうか? シミュレートされた意識と,本物の意識の違いは何でしょうか?
アイデンティティと記憶
Holly Herndon & Mat Dryhurst – “Holly+” (2021)
Holly HerndonとMat Dryhurstの”Holly+”は,AI時代のアイデンティティと所有権を探る野心的なプロジェクトです.
公式リンク: Holly+ Website
Holly+は,Holly Herndonの声と言語スタイルを学習したLLMです.しかし,このツールは,Herndon本人だけが使うのではありません.誰でも「Holly」として創作できるのです.あなたがHolly+を使って音楽を作れば,それはHollyの声で歌います.
技術的には,声のクローニング(音声AI)と言語スタイルのモデル化(LLM)が組み合わされています.そして重要なのは,このプロジェクトがDAO(分散自律組織)によって管理されていることです.Holly+を使った作品の権利関係は,ブロックチェーン上で管理されます.
このプロジェクトは,複数の問いを提起します.まず,デジタル・アイデンティティについて.自分のデジタルコピーを作り,それを他者に使わせることの意味とは何でしょうか? アイデンティティは,分散し,拡張できるのでしょうか?
次に,所有権と管理について.AI生成コンテンツの権利は誰に帰属するのでしょうか? Holly+を使って作られた曲は,誰の作品でしょうか? オープンソースとクローズドソースの間に,新しい形態があるのでしょうか?
そして,創造性について.「Holly」を使った作品は,Hollyの作品なのでしょうか? それとも,使用者の作品なのでしょうか? 集合的創造性とは何でしょうか?
Stephanie Dinkins – “NOT the Only One” (2018-2023)
Stephanie Dinkinsの”NOT the Only One”は,文化的記憶とAIの関係を探る作品です.
公式リンク: NOT the Only One
Dinkinsは,多世代のアフリカ系アメリカ人女性(祖母,母,娘の3世代)の口述歴史を収集し,それをGPT-2/3ベースのAIに学習させました.このAIは,200年以上の歴史的経験,個人的な物語,文化的知識を保持しています.
このプロジェクトの背景には,重要な問題意識があります.主流のAI(GPT-3など)は,主に白人,男性,西洋的な視点のテキストで訓練されています.そこには,マイノリティの声,特にアフリカ系アメリカ人女性の経験が十分に反映されていません.
“NOT the Only One”は,この不均衡に対抗します.特定のコミュニティの記憶と語りを保存し,AIという形で継承しようとするのです.
しかし,問いも多くあります.AIは本当に文化的記憶を保持できるのでしょうか? テキストに変換された時点で,何かが失われるのではないでしょうか? 誰の声がAIに反映され,誰の声が除外されるのでしょうか?
この作品は,AI技術が誰のために,誰によって作られるのか,という根本的な問いを投げかけます.
Jake Elwes – “Zizi Project” (2019-2022)
Jake Elwesの”Zizi Project”は,クィアなアイデンティティとAIの関係を探る作品です.
公式リンク: Zizi Project
Elwesは,ドラァグクイーンたちの動きと言語を学習したAIを作りました.モーションキャプチャでドラァグパフォーマンスを記録し,GANで映像を生成し,GPT-2/3で対話を生成します.結果として生まれたのは,クィアなアイデンティティを体現するAIキャラクター「Zizi」です.
現在のAIは,ジェンダーに関して多くの問題を抱えています.音声アシスタント(Siri,Alexaなど)の多くは女性の声を持ち,「サポート役」として設計されています.また,AIの訓練データには,性的マイノリティの経験が十分に含まれていません.
Zizi Projectは,AIがバイナリでないアイデンティティを表現できるか,という実験です.ドラァグの美学,流動的なジェンダー表現,クィアコミュニティの言語をAIに学習させることで,新しい可能性を探ります.
この作品は,身体性,言語,アイデンティティの交差点を探求します.そして,「クィア・テクノロジー」とは何か,という問いを提起します.
批評的実践
Tega Brain & Sam Lavigne – “New Organs” (2023)
Tega BrainとSam Lavigneの”New Organs”は,LLMの能力を批評的に可視化する作品です.
公式リンク: New Organs
彼らはGPT-3を使って,架空の身体器官を生成しました.各器官には,詳細な解剖学的説明,機能の記述,発見の歴史が付されています.例えば,こんな具合です.
器官名は「Temporal Lobe(時間葉)」で,過去の記憶を未来に転送する機能を持ちます.位置は左耳の後ろ,7cm下で,組織は半透明の結晶構造です.発見は2019年,ワルシャワ大学のDr. Elena Kowalskiによるとされています.
文章は完全に説得力があります.科学的なトーンで書かれ,具体的な数値や人名が含まれています.しかし,これらの器官は完全なフィクションです.
この作品が批評するのは,LLMが生成する「もっともらしさ」です.LLMは,訓練データの統計的パターンから,「それらしい」文章を生成できます.権威的なトーン,専門用語,具体的な詳細.これらが組み合わさると,真実でないことも真実のように見えてしまいます.
これは,フェイクニュースやミスインフォメーションの問題に直結します.LLMは,事実と虚構を区別しません.単に,訓練データに基づいて「もっともらしい」文章を生成するだけです.
“New Organs”は,私たちに問いかけます.私たちは,AIが生成した情報をどう評価すべきでしょうか? 専門知識の自動化には,どのような危険性があるのでしょうか? 「説得力」と「真実」は,同じでしょうか?
Anna Ridler – 言語と価値の実験 (2022-)
Anna Ridlerは,GANを使ったチューリップ生成作品”Mosaic Virus”(2018)で知られていますが,その後の作品でLLMを使った実験も行っています.
公式リンク: Anna Ridler
彼女の最近のプロジェクトでは,GPT-3を使って市場ナラティブを生成しました.株価や暗号通貨の価格変動を説明する「物語」を,AIに生成させるのです.興味深いのは,これらの説明が,実際の価格変動と無関係であることです.価格が上がった「理由」も,下がった「理由」も,AIは説得力を持って語ります.
この作品は,言語が経済的価値をどう構築するかを探ります.市場は,物語によって動きます.「なぜ価格が変動したか」の説明が,次の変動を引き起こします.しかし,その説明自体が,どれだけ真実なのでしょうか?
AIが生成するナラティブは,人間が生成するナラティブと何が違うのでしょうか? 両方とも,結局は「物語」であり,その真偽は別の問題です.Ridlerの作品は,投機,物語,真実の関係を問い直します.
協働と視覚化
Sougwen 愁予 Chung – “Drawing Operations” (2021-)
Sougwen Chungは,人間とロボットの協働描画を長年探求してきたアーティストです.最近のプロジェクトでは,GPT-3を統合しています.
公式リンク: Sougwen Chung
Chungの作品では,GPT-3がまず詩的なテキストを生成します.このテキストから,視覚的な概念を抽出します.例えば,「流れる水」「尖った山」「柔らかい光」といった要素です.これらの概念が,ロボットアームの動きに変換されます.ロボットが描画を始めると,Chung自身も同時に描画します.人間の手とロボットの腕が,同じキャンバス上で対話するのです.
この作品が探求するのは,言語と視覚の変換です.言葉はどのように視覚的形態になるのでしょうか? 「流れる」という概念は,線の動きとしてどう表現されるのでしょうか?
また,身体性とデジタルの関係も問われます.Chungの手の動きは,長年の訓練による身体知です.ロボットの動きは,アルゴリズムによる計算です.両者が協働するとき,何が生まれるのでしょうか?
これは,まさにこの授業のテーマと共鳴します.言語記述が視覚的想像を喚起する(見立て),テキストプロンプトによる認知的介入,マルチモーダル体験の創出.Chungの作品は,これらのプロセスを可視化しているのです.
技術比較
テキスト技術の進化まとめ
ここまで見てきた技術の進化を,改めて整理しましょう.
Text2Vec時代(2013-2017)
Word2VecやGloVeは,単語をベクトルに変換する技術でした.パラメータ数は数百万程度で,主な用途は検索や分類といったタスクの前処理でした.単語の意味的類似性を捉えられましたが,文脈を考慮できず,多義語の扱いが困難でした.
文脈考慮時代(2018)
ELMoは,文脈によって異なるベクトル表現を生成できるようになりました.双方向LSTMを使い,文の前後の情報を統合します.パラメータ数は数千万程度に増加しました.しかし,LSTMの順序処理の性質上,並列化が困難で,長い文脈の処理が苦手でした.
Transformer初期(2017-2019)
Transformerアーキテクチャの登場により,並列処理が可能になりました.BERTは双方向Transformerを使い,文脈の深い理解を実現しました.パラメータ数は3.4億(BERT-Large)に達しました.しかし,BERTの主な用途は,まだテキストの「理解」であり,自然な文章の「生成」ではありませんでした.
LLM時代(2018-2020)
GPT-1,GPT-2,GPT-3は,一方向Transformerを使ったテキスト生成に特化しました.パラメータ数は,GPT-3で1,750億に達しました.Zero-shot,Few-shot学習が可能になり,プロンプトだけで多様なタスクを実行できるようになりました.
マルチモーダル時代(2021-)
CLIPは,テキストと画像を同じ空間で扱えるようにしました.GPT-4Vは,画像を見て言語で思考できるようになりました.Geminiは,動画理解も可能です.パラメータ数は非公開ですが,1兆を超えると推定されています.
画像技術との統合
言語技術と画像技術は,もはや分離できません.2013年のWord2Vecでテキストのベクトル化が始まり,2014年のGANで画像生成の基礎ができました.2017年のTransformerが言語と画像の共通基盤となり,2018年のBERTとGPT-1で文脈理解と生成が進みました.2021年のCLIPでテキストと画像が統合空間で扱えるようになり,同年のDALL-E 1でText-to-Image生成が実現しました.2022年にはStable DiffusionとDALL-E 2が登場し,2023年のGPT-4Vで画像理解を持つLLMが現れ,2024年のSoraでText-to-Videoまで到達しました.
現在のStable DiffusionやMidjourneyは,CLIPのようなテキストエンコーダと,Diffusion Modelを組み合わせています.つまり,言語モデルの技術が,画像生成の「入り口」を担っているのです.
メディアアートにおける位置付け
LLMは,メディアアートにおいて,複数の役割を持ちます.
ツールとして使う場合,LLMは文章生成,アイデア生成,インタラクションのためのツールとなります.これは,Photoshopがツールであるのと同じような使い方です.
メディアとして扱う場合,言語そのものが表現の対象となります.Allison Parrishの詩や,Ross Goodwinの小説のように,LLMが生成するテキストが作品となります.
批評的対象として向き合う場合,Tega BrainとSam Lavigneの”New Organs”のように,LLMの能力と限界,バイアス,社会的影響を批判的に探求する作品もあります.
協働者として扱う場合,K Allado-McDowellの”Pharmako-AI”や,Sougwen Chungの”Drawing Operations”のように,人間とAIが共同で創作するパートナーとしての役割もあります.
倫理的・社会的考察
LLMの発展は,多くの倫理的・社会的問題を提起しています.
著作権とオリジナリティの問題では,LLMは訓練データを「記憶」しているのか,生成されたテキストは誰のものか,という疑問が生じます.Holly Herndonの”Holly+”は,この問題を直接扱っています.
バイアスと公平性の問題では,LLMは訓練データに含まれるバイアスを学習します.性別,人種,文化に関するステレオタイプが,生成されるテキストに現れることがあります.Stephanie Dinkinsの”NOT the Only One”は,マイノリティの声をAIに反映させる試みです.
労働と価値の問題では,LLMはライターや翻訳者の仕事を奪うのか,創造的労働の価値はどう変わるのか,という疑問があります.Lauren Lee McCarthyの”LAUREN”は,AIと人間の労働の境界を可視化します.
真実と虚構の問題では,LLMはもっともらしい虚偽を生成できます.Tega BrainとSam Lavigneの”New Organs”が示すように,これは深刻な社会的問題です.
今後の展望
技術的には,さらなる大規模化,マルチモーダル性の深化,リアルタイム処理の実現が予想されます.同時に,エネルギー効率の改善も重要な課題です.
表現の可能性としては,より洗練された対話作品,複雑な物語生成,個人化された体験,集合的創造の新しい形態が期待されます.
研究的には,創造性のメカニズムの解明,人間とAIの協働の最適化,認知的影響の測定,新しい美学の構築が課題となります.