第6回 生成AIと表現1:Transformer時代の画像生成
目次
- 導入:生成モデルから生成AIへ
- Transformer革命
- Autoregressive Models(自己回帰モデル)
- Masked Generative Models
- Diffusion Models
- Flow Matching
- 技術的比較
- 実践:生成AIツールを使ってみる
- 作品
導入:生成モデルから生成AIへ
前回の講義では,VAEやGANといった生成モデルについて学びました.これらのモデルは画像生成において大きな進歩をもたらしましたが,いくつかの課題も抱えていました.
従来の生成モデルの課題
GANの課題
- 学習の不安定性(モード崩壊など)
- 生成の多様性の欠如
- 細かい制御が困難
VAEの課題
- 生成画像がぼやける傾向
- 高解像度画像の生成が困難
- 詳細なディテールの再現性が低い
Generative AIとは
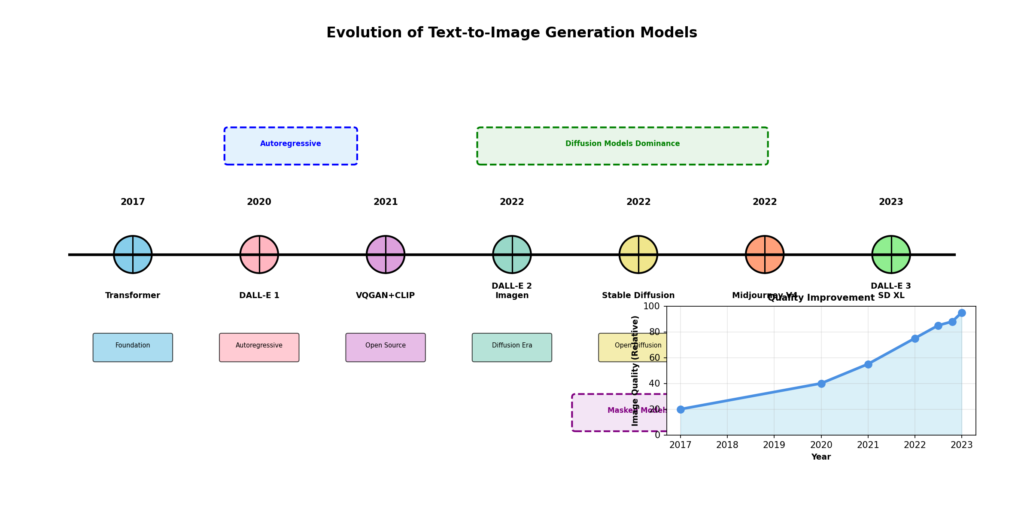
2017年のTransformerの登場以降,画像生成技術は劇的に進化しました.この時代の画像生成AIを「Generative AI」と呼びます.
Generative AIの特徴
- 大規模なデータセットでの学習
- Transformerアーキテクチャの活用
- テキストからの画像生成(Text-to-Image)
- 高品質で多様な出力
- ユーザーの意図に沿った細かい制御
現在,私たちが日常的に使用している画像生成AIサービス(Midjourney,DALL-E,Stable Diffusionなど)は,すべてこのGenerative AIの範疇に入ります.
Transformer革命
Transformerとは
Transformer は2017年にGoogle の研究者によって提案されたニューラルネットワークアーキテクチャです.元々は自然言語処理(NLP)のために開発されましたが,その後,画像処理を含むあらゆる領域に適用されるようになりました.
論文: “Attention is All You Need” (2017)
Attentionメカニズム
Transformerの核心は「Attention(注意機構)」と呼ばれるメカニズムです.
Attentionの仕組み
1. 入力データの各要素が,他のすべての要素との関連性を計算
2. 重要な要素により多くの「注意」を払う
3. 文脈を考慮した表現を獲得
例えば,テキスト「猫が魚を食べた」において:
- 「食べた」という動詞は「猫」(主語)と「魚」(目的語)に注意を向ける
- 文全体の意味を理解するために,単語間の関係性を捉える
Vision Transformer (ViT)
Transformerを画像に適用したのがVision Transformer(ViT)です.
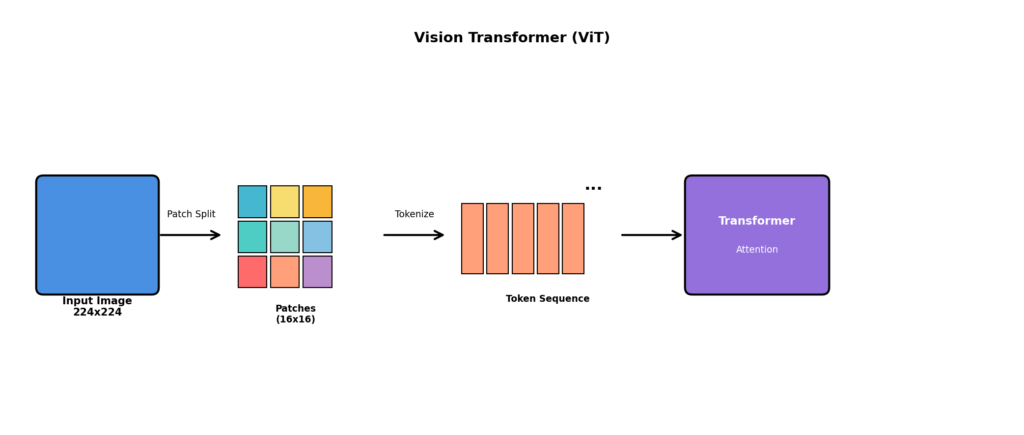
ViTの処理手順
1. 画像を小さなパッチ(例:16×16ピクセル)に分割
2. 各パッチを1次元のベクトル(トークン)に変換
3. TransformerでパッチID間の関係性を学習
4. 画像全体の特徴を獲得
これにより,画像生成AIは以下が可能になりました:
- 長距離依存関係の学習(画像の離れた部分の関連性)
- スケーラビリティ(大規模モデルの訓練)
- マルチモーダル学習(テキストと画像の統合)
Transformerが画像生成にもたらした変革
- Text-to-Imageの実現: CLIPなどのマルチモーダルモデルにより,テキストと画像を同じ空間で扱えるように
- 高品質な生成: Attentionにより細部まで一貫性のある画像生成
- スケーラビリティ: パラメータ数を増やすことで性能向上
- 柔軟な制御: プロンプトによる詳細な指示が可能
Autoregressive Models(自己回帰モデル)
概要
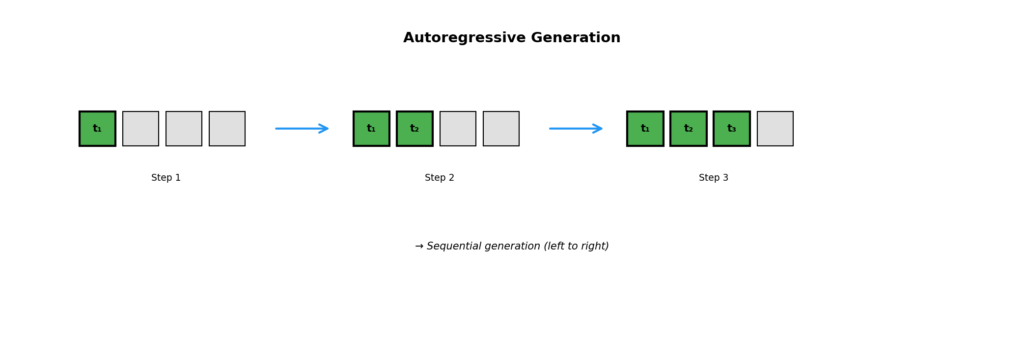
Autoregressive Models(自己回帰モデル)は,画像をトークンの系列として扱い,1トークンずつ順番に生成していくアプローチです.
基本的な考え方
- テキスト生成のGPTモデルと同じ原理
- 画像を離散的なトークン列に変換
- 前のトークンから次のトークンを予測
画像のトークン化
画像を自己回帰的に生成するには,まず画像をトークン列に変換する必要があります.
処理の流れ
1. トークン化: VQ-VAEなどを使用して画像を離散的なトークン列に変換
– 例:256×256の画像 → 32×32=1024個のトークン
2. 系列として扱う: トークンを左上から右下へ順番に並べる
3. 自己回帰生成: 前のトークンから次のトークンを予測
トークン列: [t1, t2, t3, ..., t1024]
生成: P(t1) → P(t2|t1) → P(t3|t1,t2) → ...
代表的なモデル
DALL-E 1 (OpenAI, 2021)
OpenAIが開発した最初の大規模Text-to-Image生成AI.
公式リンク: DALL-E Paper (arXiv) | OpenAI Blog
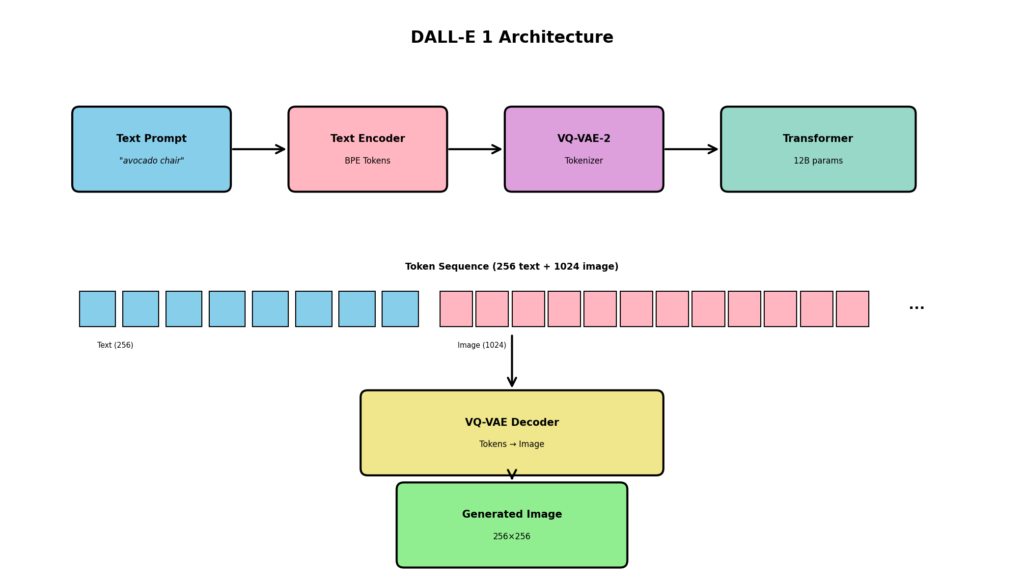
特徴
- VQ-VAE-2でテキストと画像を統合的にトークン化
- GPT-3と同様のTransformerアーキテクチャ
- 120億パラメータ
- テキストプロンプトから画像を生成
生成例を見る: DALL-E 公式ページの多数の例 では,「アボカドの形をした椅子」「ハープで作られたカタツムリ」など,創造的な組み合わせの画像が生成されています.
仕組み
1. テキストを256トークンに変換
2. 画像を1024トークンに変換
3. 合計1280トークンの系列を自己回帰的に生成
4. 生成されたトークンをデコードして画像化
例
プロンプト: “アボカドの形をした椅子”
→ DALL-E 1は,実際にアボカドの質感を持つ椅子の画像を生成
Parti (Google, 2022)
Googleが開発した高品質なText-to-Image生成AI.
公式リンク: Parti Paper (arXiv) | Google AI Blog
特徴
- ViT-VQGANによる高品質なトークン化
- Encoder-Decoder Transformerアーキテクチャ
- 200億パラメータ
- 複雑なプロンプトの理解に優れる
他のモデルとの比較
- DALL-E 2(Diffusion)よりも複雑な構図の理解が得意
- 「Aの隣にB,その上にC」といった空間的関係の表現が正確
生成例を見る: Parti Project Pageでは,「ロボットが博物館で恐竜の絵を描いている」といった複雑な関係性を含むプロンプトからの正確な画像生成例が掲載されています.
CogView シリーズ (清華大学)
中国の清華大学が開発した大規模マルチモーダルモデル.
公式リンク: CogView Paper (arXiv) | CogView2 Paper | GitHub
特徴
- 中国語と英語の両方に対応
- CogView2,CogView3と進化
- テキストと画像の統合的な理解と生成
Autoregressive Modelsの特徴
長所
- 生成過程が解釈しやすい(どのトークンを次に生成するか)
- テキスト生成の技術をそのまま活用可能
- 複雑な条件付け(conditioning)が容易
短所
- 生成速度が遅い(1024トークンを順番に生成)
- 計算コストが高い(O(n²)の計算量)
- 初期のトークンのエラーが後続に伝播
Masked Generative Models
概要
Masked Generative Modelsは,画像の一部をマスク(隠す)し,それを予測することで画像を生成するアプローチです.
基本的な考え方
- BERTなどのマスク言語モデルと同じ原理
- 複数のトークンを並列に生成可能
- 反復的に精緻化していく
MaskGIT (Google, 2022)
公式リンク: MaskGIT Paper (arXiv) | Project Page
特徴
- 双方向Transformer(Bidirectional Transformer)を使用
- 並列デコーディング
- 反復的な生成プロセス
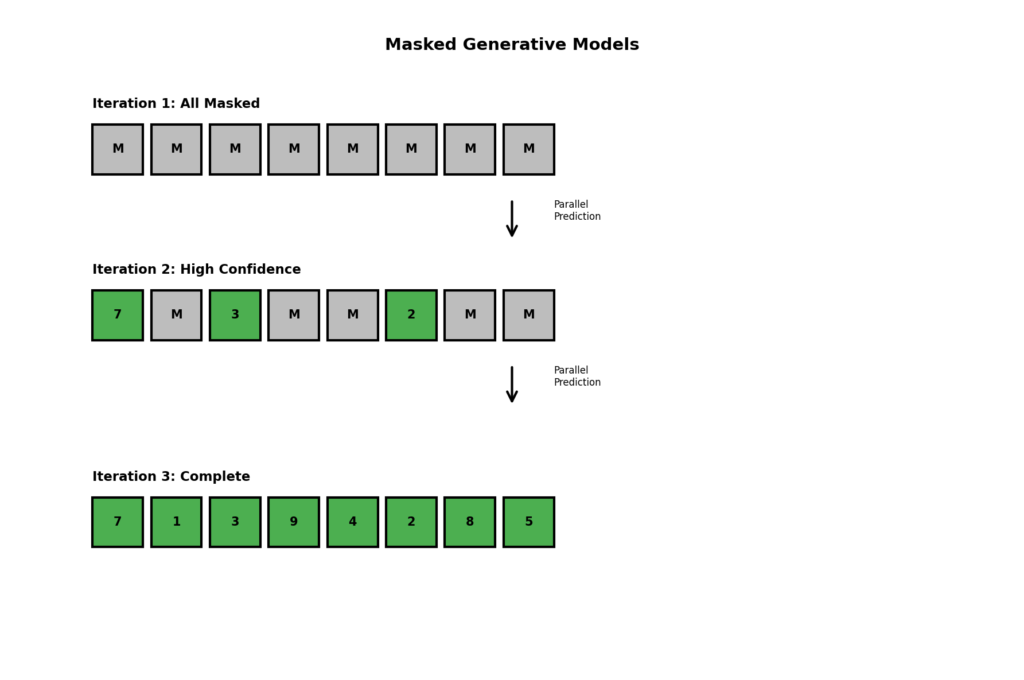
生成プロセス
1. 初期化: すべてのトークンをマスク [MASK] で初期化
2. 並列予測: マスクされたトークンをすべて同時に予測
3. 確信度フィルタリング: 予測の確信度が低いトークンは再度マスク
4. 反復: 2-3を繰り返し,徐々に画像を完成
反復1: [M, M, M, M, M, M, M, M] → [7, M, 3, M, M, 2, M, M]
反復2: [7, M, 3, M, M, 2, M, M] → [7, 1, 3, 9, M, 2, M, 5]
反復3: [7, 1, 3, 9, M, 2, M, 5] → [7, 1, 3, 9, 4, 2, 8, 5]
利点
- 生成速度がAutoregressive Modelsより高速
- 画像の大域的な一貫性が保たれやすい
Muse (Google, 2023)
Googleが開発した高速Text-to-Image生成AI.
公式リンク: Muse Paper (arXiv) | Project Page
特徴
- Masked Transformer
- 並列デコーディングによる高速生成
- 512×512画像を0.5秒で生成(当時)
アーキテクチャ
1. テキストエンコーダ: T5を使用してテキストを埋め込み
2. ベーストランスフォーマー: 低解像度の画像トークンを生成
3. スーパーレゾリューション: 高解像度化
Diffusion Modelsとの比較
- 生成速度: Museの方が約10倍高速
- 品質: Diffusion Modelsと同等
- 編集: マスクベースのため部分編集が容易
生成例を見る: Muse Project Pageでは,高速生成でありながらDiffusionモデルと同等の品質を持つ画像例が多数掲載されています.特に編集タスク(インペインティング,アウトペインティング)での優位性が示されています.
実験してみよう
Museのデモ(利用可能な場合)で,同じプロンプトでStable Diffusionと比較してみましょう.生成速度の違いを体感できます.
Masked Generative Modelsの特徴
長所
- 高速な生成(並列処理)
- 部分編集が容易(マスクを使った編集)
- 大域的な一貫性
短所
- 訓練が複雑(マスク戦略の設計)
- Diffusion Modelsほどの品質には及ばない場合がある
Diffusion Models
概要
Diffusion Models(拡散モデル)は,現在の画像生成AIの主流となっているアプローチです.ノイズから徐々に画像を生成していく手法です.
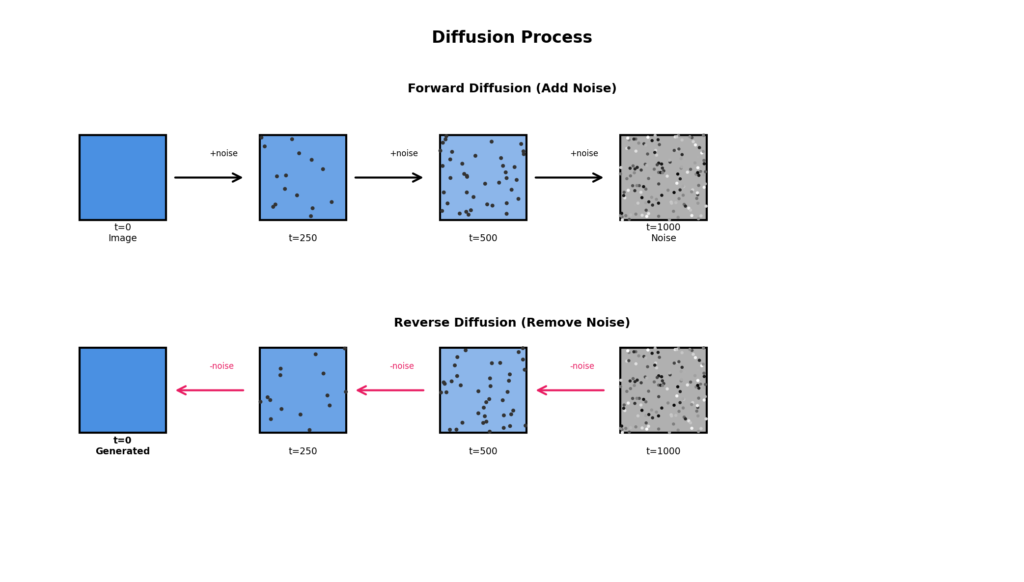
拡散プロセスの考え方
前向き拡散(Forward Diffusion)
- きれいな画像に少しずつノイズを加える
- 最終的に完全なノイズになる
- このプロセスは数学的に定義可能
逆向き拡散(Reverse Diffusion)
- ノイズから少しずつノイズを除去
- 最終的にきれいな画像になる
- ニューラルネットワークでこのプロセスを学習
U-Net アーキテクチャ
Diffusion Modelsの多くは,U-Netと呼ばれるアーキテクチャを使用します.
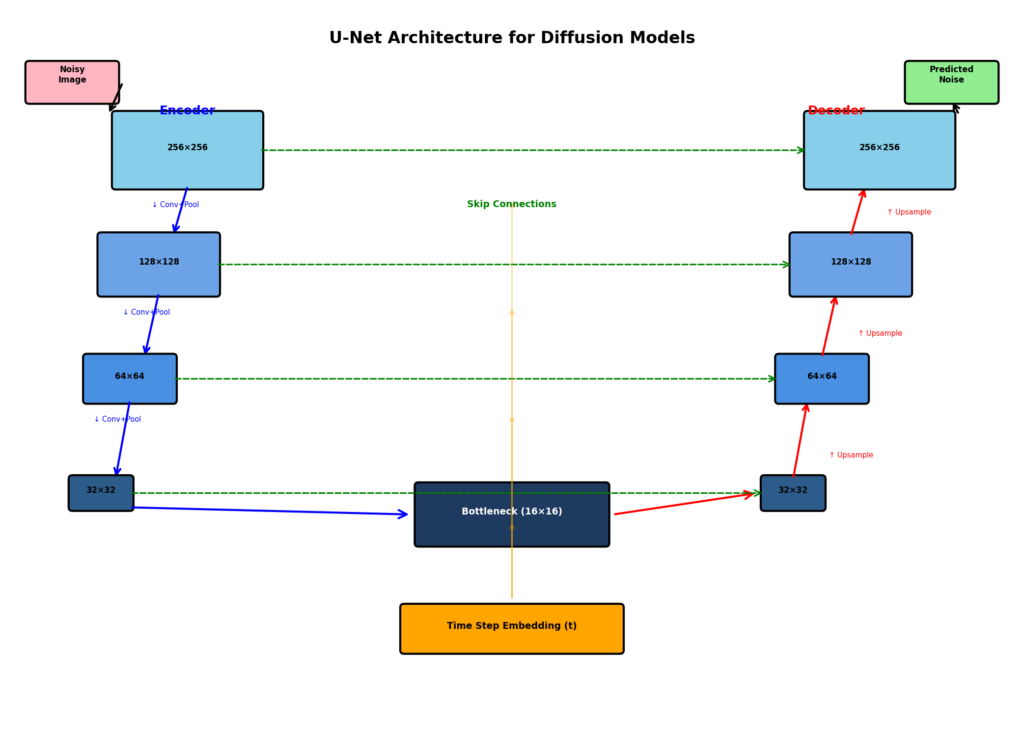
U-Netの特徴
- エンコーダ: 画像を段階的に縮小し特徴抽出
- デコーダ: 特徴から画像を段階的に復元
- スキップ接続: エンコーダとデコーダを直接接続
この構造により,細部の情報を保持しながら画像を生成できます.
DDPM (Denoising Diffusion Probabilistic Models)
特徴
- 拡散過程を確率的にモデル化
- ノイズ予測ネットワークを学習
- 1000ステップ程度の逆拡散で高品質画像を生成
生成プロセス
t=1000 (完全ノイズ) → t=999 → t=998 → ... → t=1 → t=0 (画像)
各ステップでノイズを少しずつ除去
Latent Diffusion Models (LDM)
背景
通常のDiffusion Modelsは,ピクセル空間で直接拡散を行うため,計算コストが高いという問題がありました.
Latent Diffusion の考え方
1. オートエンコーダで圧縮: 画像を低次元の潜在空間に圧縮
2. 潜在空間で拡散: 圧縮された表現に対して拡散を実行
3. デコードして画像化: 生成された潜在表現を画像に復元
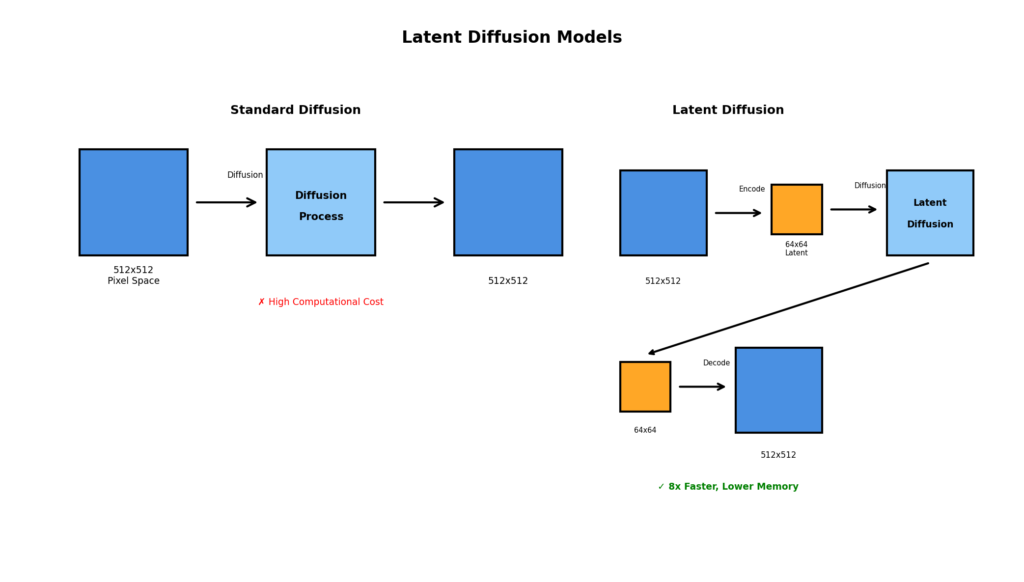
利点
- 計算コストの削減(8倍程度の高速化)
- メモリ使用量の削減
- 高解像度画像の生成が実用的に
Stable Diffusion
Latent Diffusion Modelsをベースにした,オープンソースの画像生成AI.
公式リンク: Stable Diffusion Paper (arXiv) | Stability AI | GitHub
構成要素
1. テキストエンコーダ: CLIPを使用
2. U-Net: ノイズ予測ネットワーク(潜在空間で動作)
3. VAEエンコーダ: 画像を潜在空間に変換
4. VAEデコーダ: 潜在表現を画像に変換
バージョンの進化
- Stable Diffusion 1.x: 512×512ピクセル
- Stable Diffusion 2.x: 768×768ピクセル,改良されたCLIPエンコーダ
- Stable Diffusion XL: 1024×1024ピクセル,2つのテキストエンコーダ
- Stable Diffusion 3: Rectified Flow(後述)
生成例を見る: Stability AI BlogやCivitaiでは,コミュニティが生成した多様なスタイルの画像が数百万点以上公開されています.写実的なポートレートからアニメ風イラスト,3Dレンダリング風まで,幅広い表現が可能です.
試す:
- Hugging Face Stable Diffusion Demo – 無料でブラウザ上で試せます(アカウント不要)
- Stable Diffusion 3.5 Demo – 最新版を試せます
DALL-E 2 (OpenAI, 2022)
DALL-E 1からの大きな進化.自己回帰モデルからDiffusion Modelへ.
公式リンク: DALL-E 2 Paper (arXiv) | OpenAI DALL-E 2
アーキテクチャ
1. CLIP: テキストと画像を同じ埋め込み空間にマップ
2. Prior: テキスト埋め込みから画像埋め込みを生成
3. Decoder: Diffusion Modelで画像を生成
特徴
- Inpainting(画像の一部を編集)
- Outpainting(画像の外側を拡張)
- バリエーション生成
生成例を見る: DALL-E 2公式ページでは,4倍高解像度でよりリアルな画像生成例が多数掲載されています.
DALL-E 3 (OpenAI, 2023)
DALL-E 2からの改良版.
公式リンク: DALL-E 3 Paper (arXiv) | OpenAI DALL-E 3 | ChatGPT Plus
主な改善点
1. キャプション改善: より詳細で正確な画像説明を生成
2. プロンプト理解: 複雑な指示の理解が向上
3. 安全性: 有害コンテンツの生成を防ぐ機能強化
試す: Bing Image Creatorで無料でDALL-E 3を体験できます(週15回の高速生成が無料,Microsoftアカウントが必要).
Imagen (Google, 2022)
Googleが開発した高品質Text-to-Image生成AI.
公式リンク: Imagen Paper (arXiv) | Project Page
特徴
- Diffusion Modelベース
- 大規模言語モデル(T5)をテキストエンコーダとして使用
- カスケード型スーパーレゾリューション
アーキテクチャ
1. 64×64の画像を生成
2. 256×256に拡大
3. 1024×1024に拡大
Photorealismへのこだわり
Imagenは,特に写実性(photorealism)の評価が高く,人間の評価でしばしばDALL-E 2を上回る結果を示しました.
生成例を見る: Imagen Project Pageでは,「青いジェイの鳥と大きな紫色のアンスリウムの花」など,複雑なプロンプトからの高品質な写実的画像が多数掲載されています.
試す: Google AI Test KitchenのImageFXで最新のImagen 3を無料で試すことができます(Googleアカウントが必要,100カ国以上で利用可能).
Midjourney
公式リンク: Midjourney Website | Discord Server | Documentation
特徴
- 詳細なアーキテクチャは非公開
- Diffusion Modelsベースと推測
- 芸術的で美しい画像生成に特化
- Discordベースのインターフェース
バージョンの進化
- V1-V4: 徐々に品質向上
- V5: リアリズムの大幅向上
- V6: プロンプト理解の改善
- Niji: アニメスタイル特化版
生成例を見る: Midjourney Showcaseでは,ユーザーが生成した芸術的で高品質な画像が多数展示されています.特にファンタジーアート,コンセプトアート,ポートレートなどの分野で高い評価を得ています.
試す: Discord経由で利用可能(有料プラン:Basic $10/月,Standard $30/月,Pro $60/月).無料トライアルは現在提供されていません.
Diffusion Modelsの特徴
長所
- 非常に高品質な画像生成
- 訓練が安定(GANと比較して)
- 多様な画像生成
- 細かい条件付けが可能
短所
- 生成速度が遅い(多数のステップが必要)
- 計算コストが高い
- メモリ消費が大きい
Flow Matching
概要
Flow Matching(フローマッチング)は,Diffusion Modelsの改良版として登場した新しいアプローチです.
Rectified Flow
基本的な考え方
- ノイズから画像への変換を「フロー」として捉える
- 直線的(rectified)な経路を学習
- より効率的な生成が可能
Diffusion Modelsとの違い
| 特徴 | Diffusion Models | Rectified Flow |
|---|---|---|
| 経路 | 確率的(stochastic) | 決定論的(deterministic) |
| ステップ数 | 多い(50-1000) | 少ない(1-10) |
| 生成速度 | 遅い | 速い |
| 訓練 | 複雑 | シンプル |
Stable Diffusion 3
2024年にリリースされたStable Diffusion 3は,Rectified Flowをベースにしています.
公式リンク: SD3 Paper (arXiv) | Stability AI Announcement | Hugging Face
特徴
1. Multimodal Diffusion Transformer (MMDiT)
– テキストと画像を統合的に処理
– Transformerベースのアーキテクチャ
- Rectified Flow
- 少ないステップでの高品質生成
- 生成速度の向上
- 改良されたテキスト理解
- 3つのテキストエンコーダ(CLIP,OpenCLIP,T5)
- 複雑なプロンプトの正確な理解
実験してみよう
Stable Diffusion 3とStable Diffusion XLで同じプロンプトを試し,テキスト理解の精度と生成速度を比較してみましょう.
Flow Matchingの将来性
Flow Matchingは,Diffusion Modelsの次世代として注目されており,以下の利点があります:
- 効率性: 少ないステップでの生成
- 品質: Diffusionと同等以上の品質
- 柔軟性: 様々な応用が可能
技術的比較
アーキテクチャ別比較表
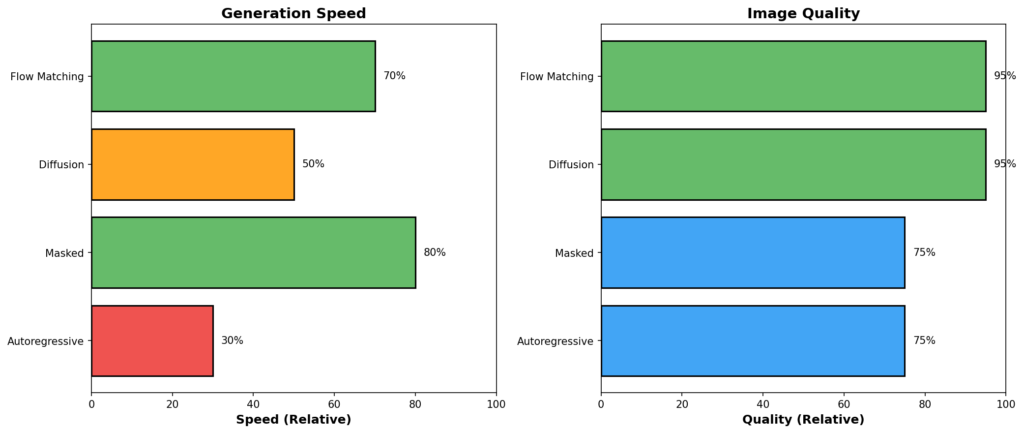
| アーキテクチャ | 生成速度 | 画質 | 訓練の安定性 | 制御性 | 代表例 |
|---|---|---|---|---|---|
| Autoregressive | 遅い | 良好 | 高い | 高い | DALL-E 1, Parti |
| Masked | 速い | 良好 | 中程度 | 高い | Muse, MaskGIT |
| Diffusion | 遅い | 優秀 | 高い | 高い | SD, DALL-E 2/3, Imagen |
| Flow Matching | 中~速い | 優秀 | 高い | 高い | SD3 |