目次
生成モデル
これまで紹介してきた識別モデルとは別に,生成モデルと呼ばれるモデルがあります.
識別モデルでは,例えば画像分類のように,与えられた入力に対してその画像がどのクラスにあたるかを判別することを目的としていました.
一方で生成モデルでは,今あるデータの生成過程をモデル化することを目的としています.生成過程をモデル化することができれば,学習データと似たデータを新しく生成することができるようになります.学習データと似たデータを新しく生成できると,どのようなことができるのでしょうか?
まず一例として,画像の生成があります.以下の画像の中にAIが生成した画像が含まれているのですが,どの画像がAIが生成した画像なのか,わかりますか?




実は,これらの画像は全てAIが生成した画像です.実際に存在する人物は一人もいません.
実際に存在する人物の写真と言われても,全く違和感ないレベルの画像が生成できていると思います.
生成モデルの研究当初は,もっと解像度が低くクオリティの低い画像しか生成することができませんでしたが,現在はここまで高いクオリティの画像が生成できるようになってきました.
これらの画像は,This Person Does Not Existというサイトにアクセスすることで誰でも実際に見ることができるので,ぜひ皆さんもアクセスしてみてください.
次に,生成モデルを応用した事例について紹介します.
皆さんは絵を描くことは好きですか?もしも自分が描いたスケッチが,AIによってとてもリアルな絶景へと変換されたらどのように感じるでしょうか?
NVIDIAによって開発されたNVIDIA Canvasは,生成モデルを使い,ラフなスケッチをリアルな風景画像へと変換してくれるツールです.ユーザーはブラシを使ってラフなスケッチを描くことで,様々な風景画像を自由に生成することができます.
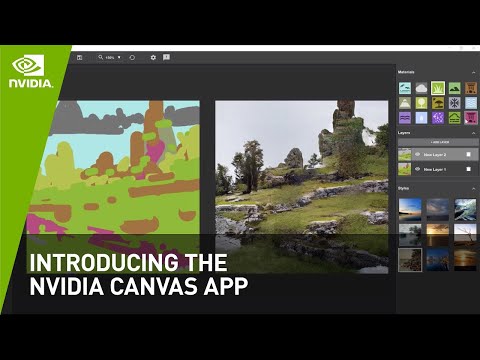
このNVIDIA Canvasは,GauGANという技術をベースとしています.このGauGANでも,以下のようにブラシを使ってスケッチを描くことで,それを元にリアルな風景を生成することができます.
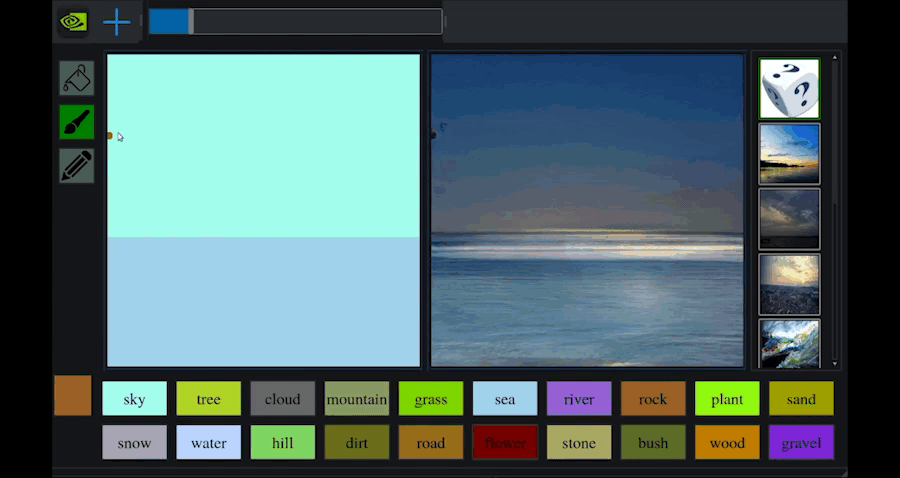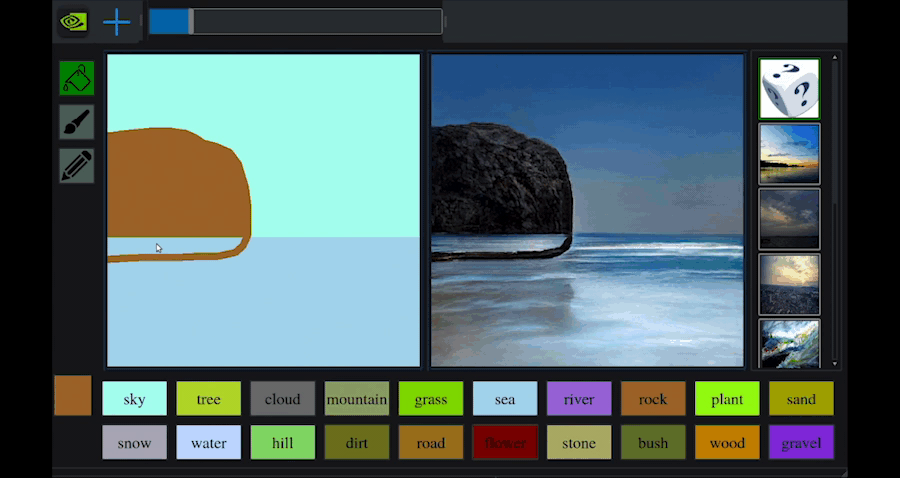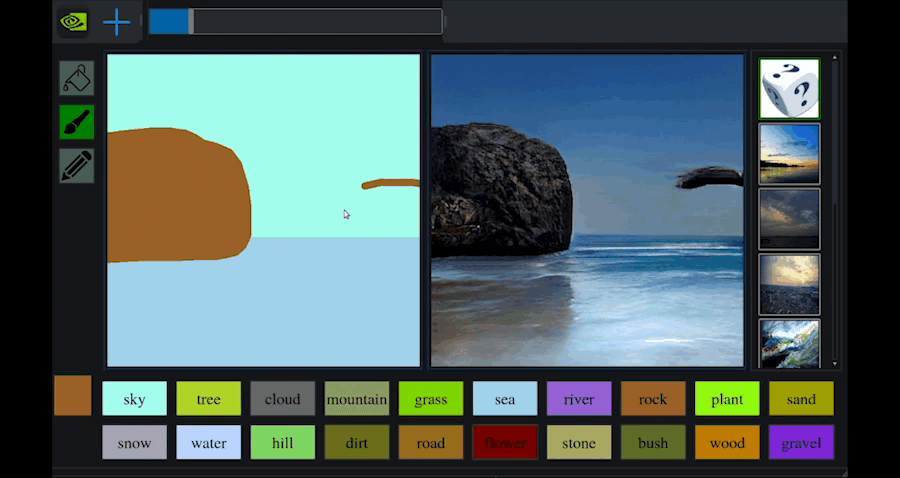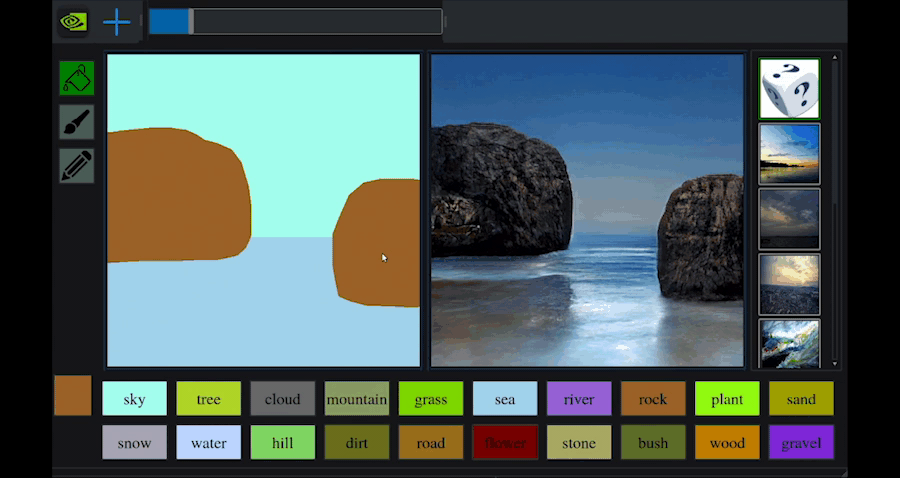
以下のWebサイトで実際に遊んでみることができるので,実際にやってみましょう.
nvidia-research-mingyuliu.com/gaugan
AIを用いて新しく絵画や音楽を生成することができるようになったことで,私たちは今までに見たことのない絵画や聞いたことのない音楽を作り出すことができるようになりました.これは非常に可能性に満ちており,新しい芸術の形が将来的に生まれてくるかもしれません.
実際に,AIを用いて新しく絵画を生成するという事例は多くあります.今回は,その中でも文化的な意義を持つ事例について紹介します.
2018年に,パリのアーティストグループであるObviousが,AI (GAN) を用いて制作した絵画をオークションに出品しました.そこで,7,000(約79万円)~10,000(約113万円)ドルの予想価格に対して,それを大きく上回る432,500ドル(約4894万円)の値段で落札されました.このオークションは,クリスティーズという世界で最も長い歴史を誇る美術品オークションハウスで行われたものでした.以下が,実際にオークションに出品された作品です.

右下には,アーティストの署名として,とある数式が記載されています.この数式は,この後紹介するGANというアルゴリズムの数式を意味しています.つまりObviousは,この作品の作者がAIであると主張しているのです.
この一件は,AIとアートの関係について,大きな影響を与えることになりました.たくさんのデータを用意してAIを訓練させた後,そのAIを使って作り出した作品は,いったい誰の作品となるのでしょうか?
このように,生成モデルを用いることによって,非常にクオリティの高い画像やアート作品を作り出すことができます.
ここで紹介した事例以外にも,生成モデルを用いることで以下のようなことができます.
- 絵画のデータを学習して,新しく絵画を生成する
- 音楽のデータを学習して,新しい音楽を生成する
- 文章を学習して,新しく文章を生成する
- 俳句のデータを学習して,新しく俳句を生成する
ここまで見てきた生成モデルには様々な種類があり,現在もたくさんの研究が行われています.今回は,その中でも有名なVAEとGANについて扱います.
VAE
生成モデルの一つに,Variational Autoencoder (VAE) と呼ばれるモデルがあります.VAEは生成モデルの一種なので,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.
VAEは,Autoencoderと呼ばれるモデルを発展させたモデルになります.そのため,まずはAutoencoderについて説明します.
Autoencoderとは,訓練データを表現する特徴を学習するためのネットワークです.
訓練データとは,学習したい画像を集めたデータセットになります.ここでは,例としてmnistという有名なデータセットを取り上げます.
mnistは,以下の画像のように手書きの文字を集めたデータセットになります.画像認識や画像生成など,AI研究において頻繁に用いられるデータセットなので,これからも目にする機会は多いでしょう.

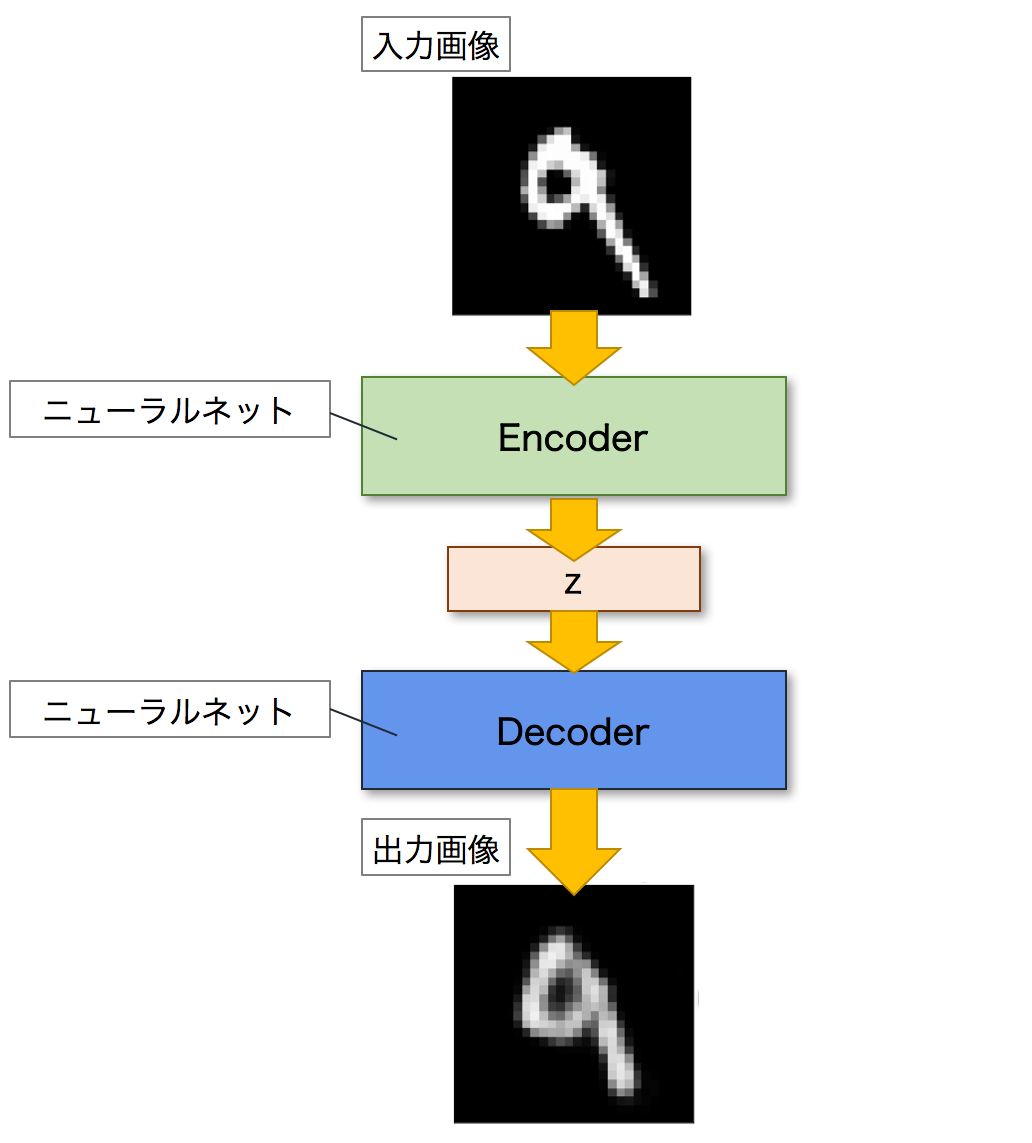
Autoencoderとは,ニューラルネットワークのモデルの一つであり,入力画像に近い画像を出力することを目的とするモデルです.Autoencoderは,EncoderとDecoderという二つのネットワークで構成されます.Encoderは入力画像を潜在変数zと呼ばれる低次元の特徴へと変換します.逆に,Decoderは潜在変数zを入力として画像を出力します.これにより,Autoencoderは入力された画像を復元することができます.以下が,Autoencoderのネットワーク図になります.
次に,VAEについて見ていきましょう.VAEは,Autoencoderを発展させたモデルになります.以下がVAEのネットワーク図になります.全体的な構造としては,Autoencoderと同じくEncoderとDecoderの二つのネットワークで構成されています.そしてAutoencoderと同じように,Encoderが入力画像を潜在変数zへと変換し,Decoderがこの潜在変数zを元の画像へと復元して出力します.
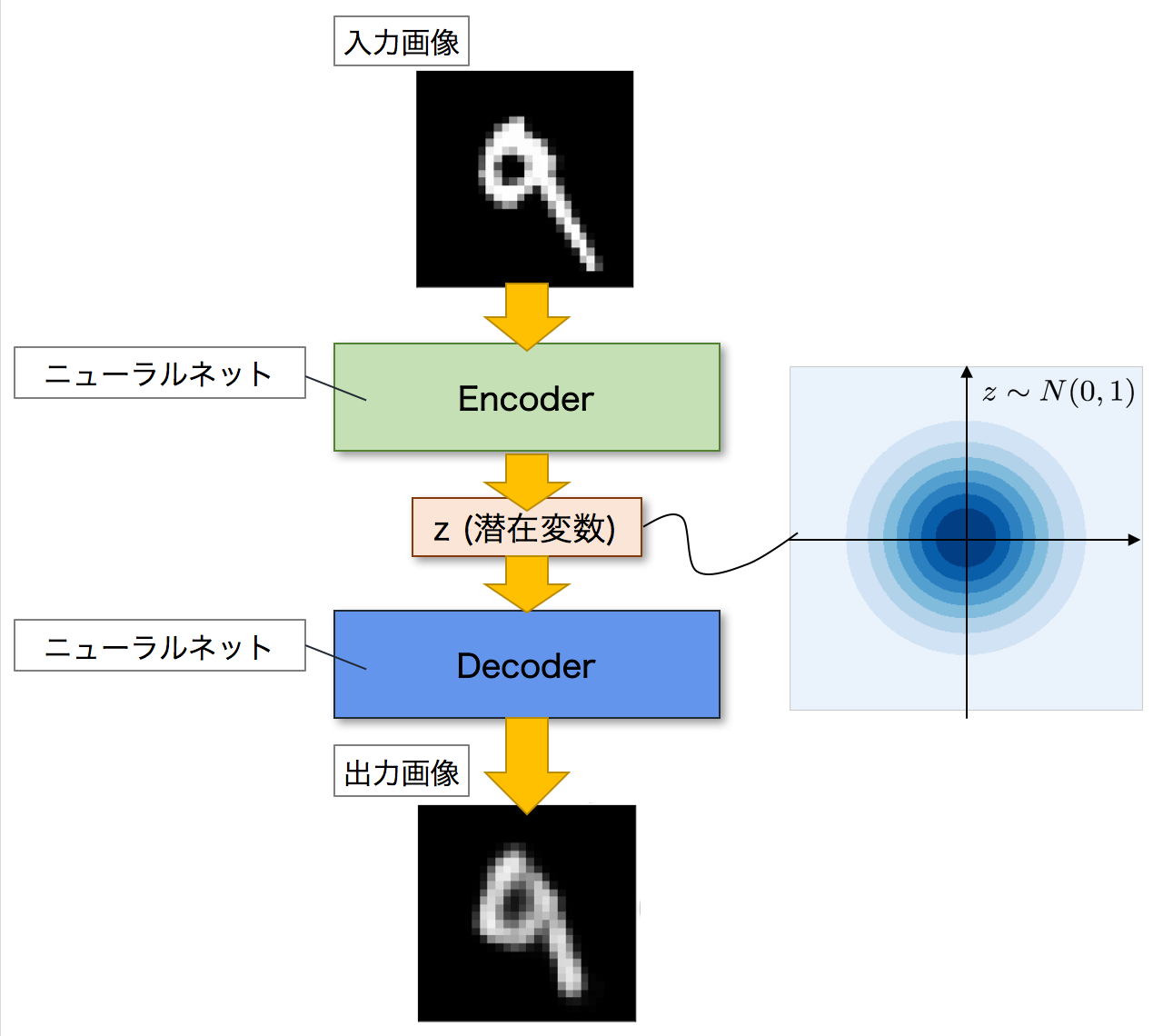
VAEがAutoencoderと異なるのは,潜在変数zの分布です.Autoencoderでは,潜在変数zにデータが押し込められますが,その分布については詳細はわかりません.一方で,VAEの場合には,潜在変数zに同じようにデータを押し込めますが,その分布が特定の確率分布に従うことを仮定しています.つまり,潜在変数zがどのような分布をしているのかが分かるということです.
VAEは生成モデルなので,学習を終えた後は,新しく画像を生成することができます.その際,Decoderに潜在変数zを入力して画像を生成しますが,この時に潜在変数zがどのような分布をしているのかがわかれば,生成する画像を細かくコントロールすることができます.
例えばmnistであれば,そのデータには0~9までの10種類の数字が含まれます.VAEを使ってmnistのデータを学習することで,潜在変数zのうち,ある領域には0,ある領域には1,そして別の領域には他の数字が含まれるようになります.以下の画像は,実際に潜在変数zの分布を可視化した画像です.画像右上の領域には0が,左下の領域には1が含まれていることがわかります.

(https://github.com/ChengBinJin/VAE-Tensorflow より引用)
そのため,もしこのVAEを使って0という数字を生成したければ,0が含まれる領域から潜在変数zを選べばいいことになります.上の画像で言えば,右上の潜在変数zを選べば良いわけです.この時,VAEであれば潜在変数zの分布がわかるので,狙った数字を生成しやすくなるのです.この点が,VAEがAutoencoderよりも優れている点になります.
GAN
GANも生成モデルの一種です.そのためVAEと同じように,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.また,NVIDIA Canvasのように,ある入力を別の入力へと変換することもできます.
GANがVAEと大きく異なる点は,その学習方法にあります.GANは,日本語では敵対的生成ネットワークと訳されますが,その名の通り,GANでは「敵対的」に学習が進んでいきます.「敵対的に」学習が進む,とはいったいどういうことなのでしょうか.
GANの構造を以下の画像に示します.GANは,GeneratorとDiscriminatorという2つのネットワークで構成されます.Generatorは,データを生成するネットワークです.Discriminatorは,Generatorが生成した偽物のデータと本物の学習データに対して,どちらが本物のデータであるかを識別します.この2つのネットワークを交互に学習していくことで,Generatorはより本物に近いデータを生成できるようになり,Discriminatorは本物・偽物をより正確に判断することができるようになっていきます.この時,GeneratorとDiscriminatorがお互い競い合うように学習していくため,「敵対的」と呼ばれているのです.
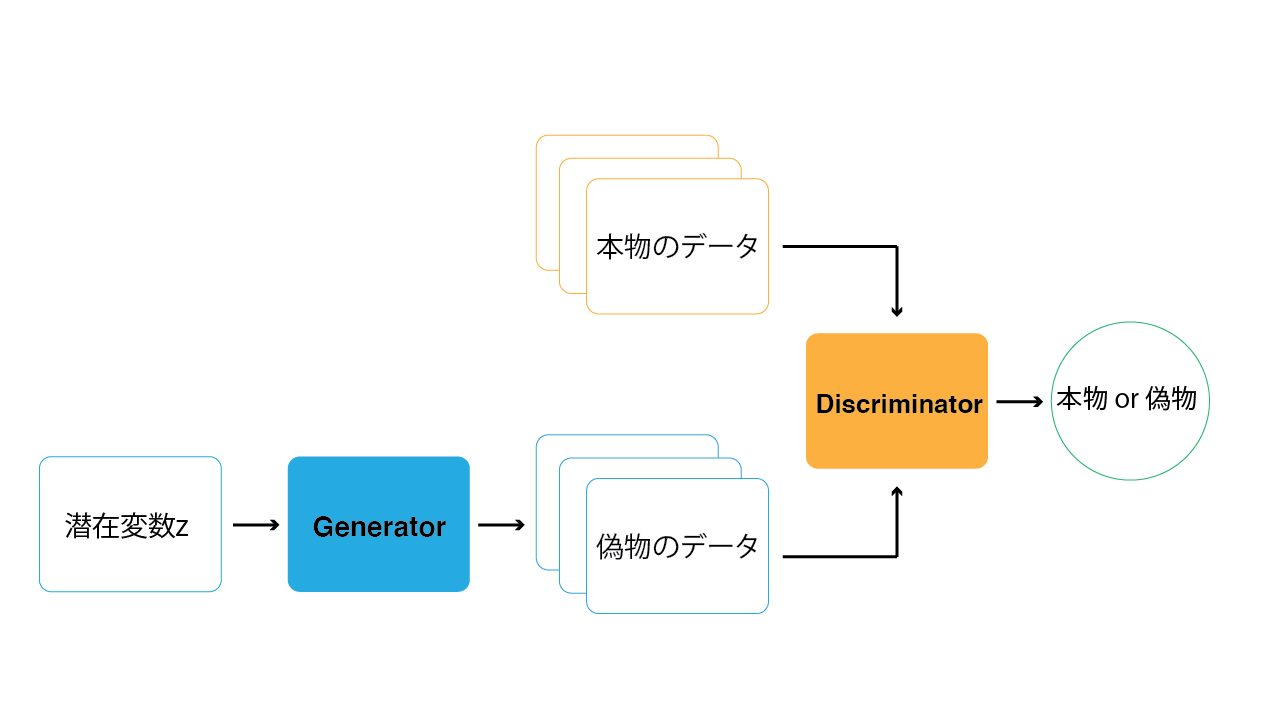
このGeneratorとDiscriminatorの関係は,よく紙幣の偽造に例えられます.偽札の作成者 (Generator) はなるべく本物に近い紙幣を作ろうとし,警察官 (Discriminator) はより正確に偽札を見分けようとします.そしてお互い交互に学習していくことで,最終的に偽札の作成者は本物とほぼ区別のつかない偽札を作れるようになっていきます.
この学習方法のおかげで,GANはVAEと比べてより鮮明な画像を生成することができます.一方で学習が難しいという問題もありますが,それを改善するために様々な研究が行われています.はじめに紹介した「This Person Does Not Exist」や「NVIDIA Canvas」もGANを使用したサービスです.
他にもGANを活用したサービスとして,Artbreederというサイトを紹介します.Artbreederは,AIを用いて様々な画像を生成することができるサービスです.
人物画像やアニメキャラ,風景画やクリーチャーなど,多種多様な画像を生成することができます.
また,Artbreederでは生成した画像に対して,パラメータを操作することで自由に編集を行うことができます.
例として,以下の画像を見てみましょう.
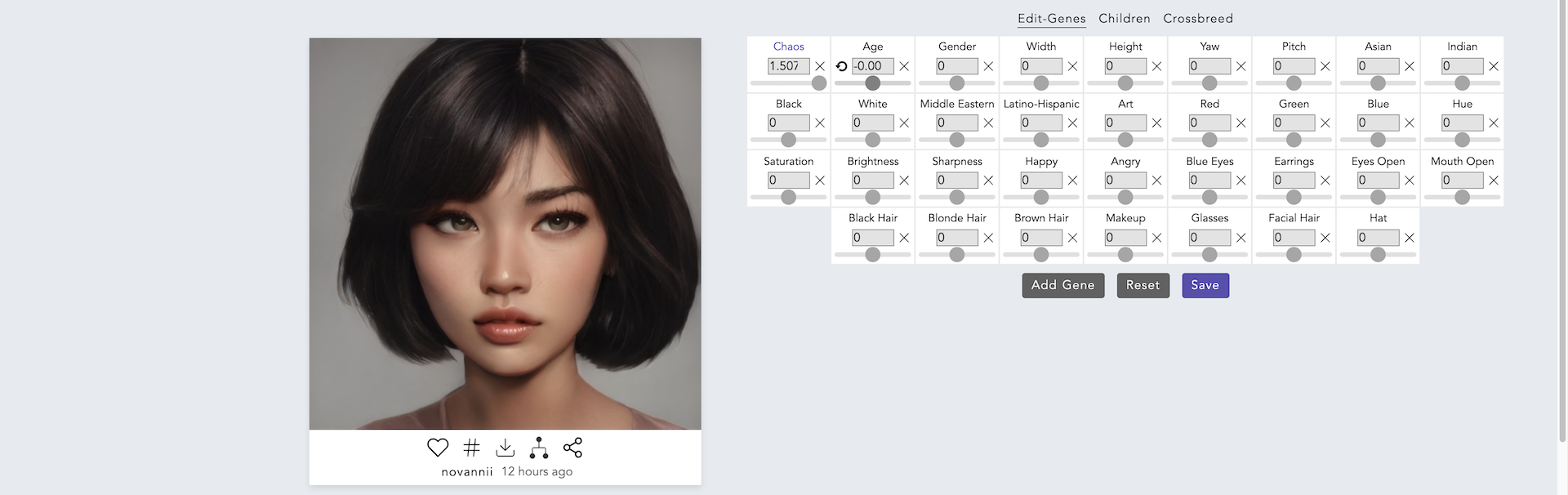
この画像は,Artbreederで実際に生成した架空の女性の顔画像です.画像の右側にたくさんのパラメータが用意されているのがわかります.このパラメータの値を調整することで,この画像を編集することができます.それでは,試しにAgeのパラメータの値を変更してみます.
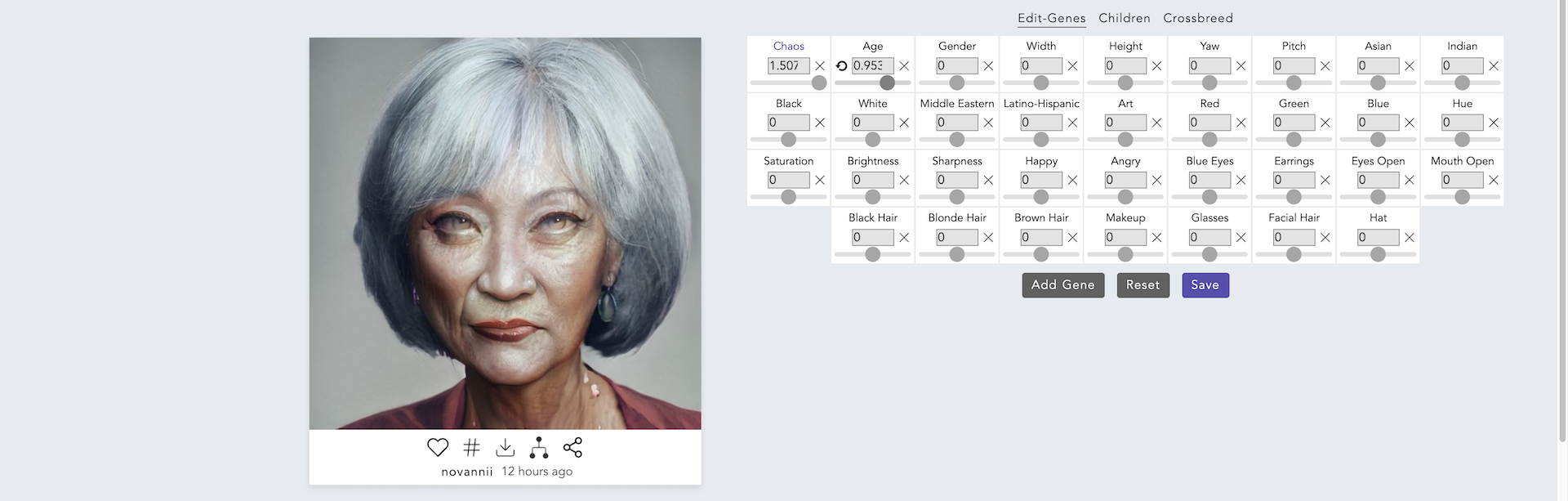
いかがでしょうか?Ageのパラメータを変更することで,若い女性の顔が老人の顔に変わりました.元の女性の雰囲気を残しつつ,年齢だけうまく変更できていますね.次に,Ageの値を元に戻してGlassesの値を変更してみます.
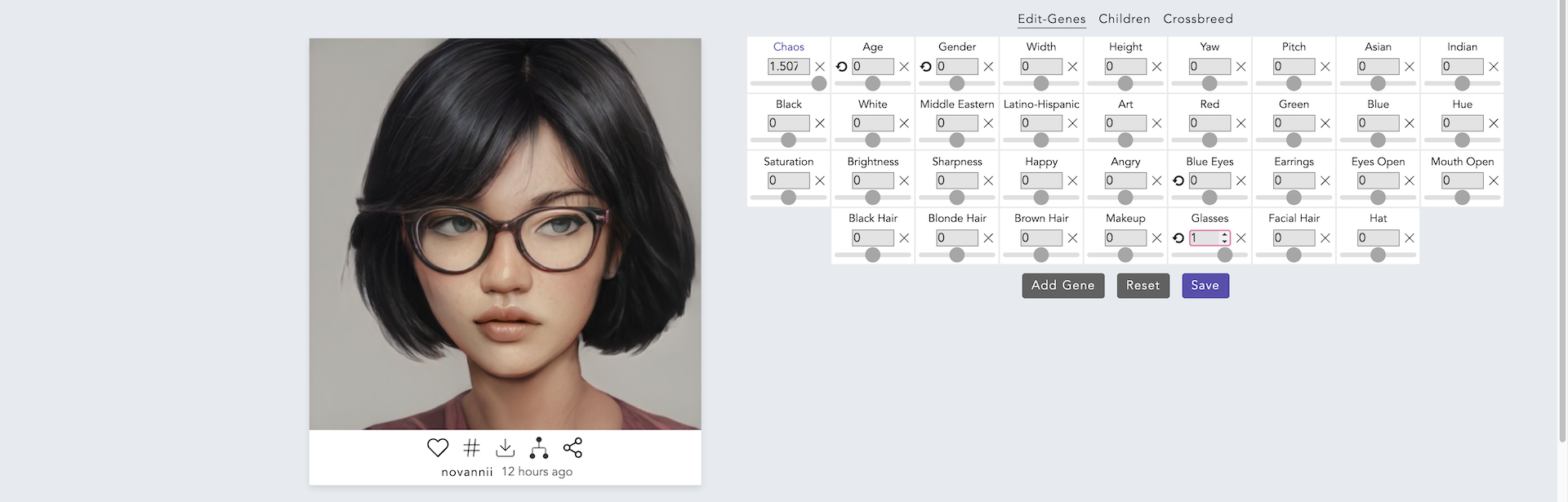
今度は女性の顔に眼鏡が追加されました.それでは最後に,Genderの値を変更してみましょう.
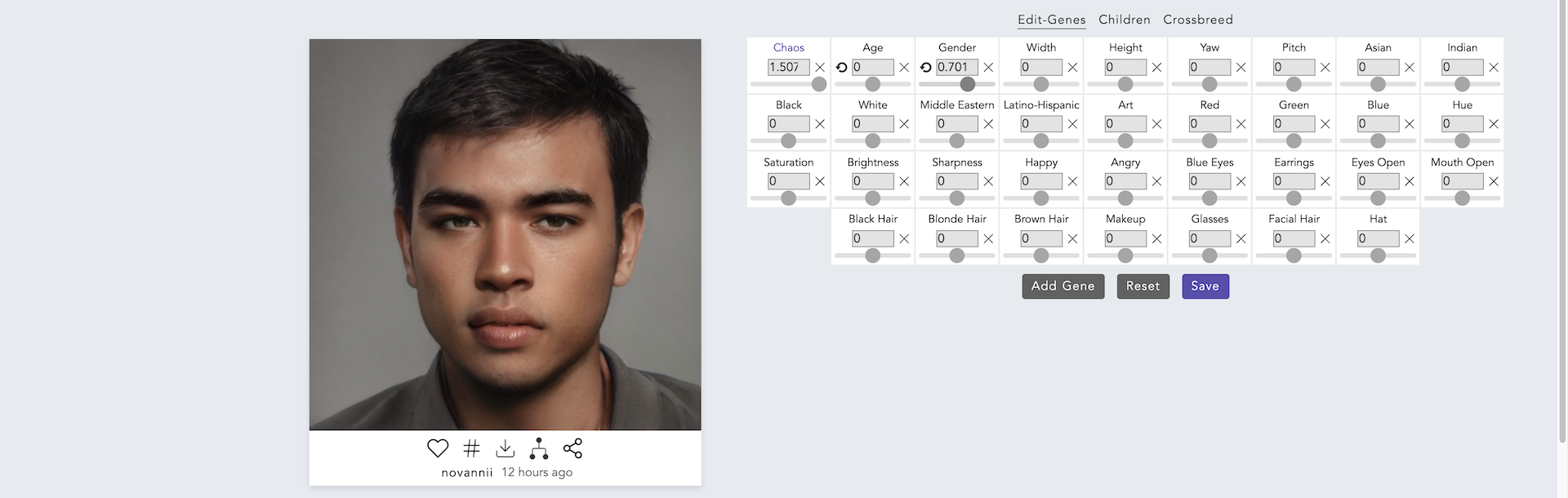
女性の顔が男性の顔に変わりました.それでも,元の女性の雰囲気がどことなく感じられるように思います.
このように,GANを使うことで非常に高いクオリティの画像を生成することができます.さらに,Artbreederのように,自分が望む画像を細かくコントロールして生成することもできます.
ここでは主に画像の生成について紹介してきましたが,他にもGANを使った音楽や文章の生成など,その応用例は様々です.
生成モデルを用いた作品
生成モデルを用いた代表的なアート作品を紹介します.
Learning to see: Gloomy Sunday (2017) Memo Akten
機械学習アルゴリズムを用いて、AIが世界をどのように「見る」かを探求した作品。人工ニューラルネットワークが、カメラを通して見た物体を、学習済みの4つのデータセット(海、雲、火、花)のフィルターを通して解釈し、変換する。
Flocking Camouflage (2021) Hiroki Kamba
時には周囲の環境に身を隠すが、別の時には静止していれば隠れられるはずのテクスチャを持ちながら動いて現れる。出現と消失の繰り返しが、新しい形式の群舞を生み出す作品。
identity disperser -afforestation- (2021)
Scott Allen, Asuka Ishii, Santa Naruse, Takayuki Yamaguchi, Nao Tokui
StyleGAN2を使用して、ユーザーに似た偽の顔画像を生成し投稿できるTwitterクライアントアプリ。インターネット上にユーザーに似た偽の顔を氾濫させることで、本物の顔を特定することを困難にし、写真と外見に関連するアイデンティティの意味を問い直す。
参考リンク
NeurIPS ML4CD
NeurIPSは機械学習とニューラルネットワークに関する世界最大級の国際会議です。ML4CD(Machine Learning for Creativity and Design)ワークショップでは、機械学習を創造性やデザインに応用した研究や作品が発表されています。
NeurIPS 2021 ML4CD
2021年のML4CDワークショップでは、機械学習を用いた創造的な作品やデザインツールが数多く紹介されました。
NeurIPS 2022 ML4CD
2022年のML4CDワークショップでは、生成AIやコンピュータビジョンを活用した新しい表現手法が発表されました。