目次
AIとは
昨今では,AIや人工知能という言葉を毎日のように目にしますが,今現在完全なAIというものは存在しません.
ですが,AIには約60年ほどの歴史があり,着実に発展を遂げてきました.まずは,これまでAIがどのような経緯で発展してきたか,その歴史を紐解いてみましょう.
歴史的側面
まず,以下の画像を見てください.AI研究は,時代の流れに伴いブーム期と冬の時代を繰り返して発展してきました.このブーム期は全部で3つあり,それぞれ第1次AIブーム,第2次AIブーム,第3次AIブームと呼ばれています.現在は,第3次AIブームの渦中です.
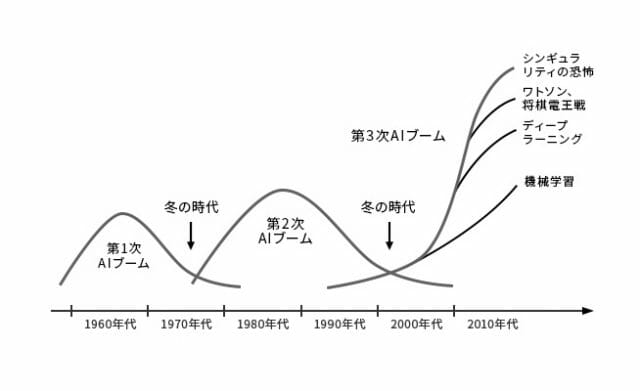
(松尾豊『人工知能は人間を超えるのか ディープラーニングの先にあるもの』KADOKAWA 発行 より引用)
起源
AI研究が本格的に始まったのは,1956年に行われたダートマス会議という会議がきっかけとされています.この会議は,ジョン・マッカーシーという科学者が主催し,他にもマービン・ミンスキーやクロード・シャノンといった科学者等が参加しました.そしてこの会議の提案書において,人類史上初めて人工知能という用語が使われたと言われています.
この会議の提案書では,人間の知的な活動を機械をシミュレートするための研究を進めるといった旨の内容が記載されていました.今は人間にしか解けない問題を機械でも解けるようにする,機械が自ら学習できるようにする,など現在のAIのイメージに近い内容がすでに構想されていました.
そしてこのダートマス会議以降,第1次AIブームが訪れます.第1次ブームでは,推論と探索が中心的に研究されました.ここでの推論とは,人間の思考パターンのことを指します.人間の思考パターンを分解し,問題に対して適切なパターンを探索することで,機械に人間と同じように思考することを目指しました.その成果として,パズルや迷路を人間よりも高速に解くことができるようになりました.しかし,問題もありました.パズルのようなルールが明確な問題に対しては成果を発揮しましたが,それ以外の問題に対しては成果を発揮することができませんでした.その結果,AI研究は一度目の冬の時代へと突入していくことになります.
エキスパートシステム
その後1980年代より,AIは第2次ブームへと突入します.第2次ブームでは,機械に知識を入れるというアプローチで研究が進み,エキスパートシステムというシステムが生まれました.エキスパートシステムではまず,機械に専門家の知識をデータとして入力します.データを入力した後は,第1次ブームで培った推論システムと組み合わせることで,機械は専門家と同じような役割を担うことができるようになります.このエキスパートシステムは医療や金融など様々な分野での応用が期待されました.
しかし第1次ブームの時と同じく,第2次ブームにおいても問題が発生します.知識を機械に入力していくことでエキスパートシステムを構築していきますが,入力されるデータが膨大になりルールの量が増えていくにつれ,ルール同士の一貫性が失われ矛盾が発生してきました.また,私たち人間が普段曖昧に使用している言葉を機械にどのように入力すればいいのか,その難しさが再認識されることとなりました.例えば,「なんとなく気分が重い」という症状の場合,「なんとなく」とはどのような意味なのか,明確にすることは難しいです.このような問題に直面し,AI研究は再び冬の時代へと突入していくことになります.
第3次AIブーム
そしていよいよ,AI研究は第3次AIブームを迎えます.第3次AIブームは現在も続いており,AI研究に大きな発展をもたらしました.その発展を支えるのが,深層学習という技術になります.
第2次AIブームまでは,人間がルールを設定し,機械がそれを計算することにとって問題を解くことが想定されていました.一方で,第3次AIブームで大きく発展した深層学習では,人間がデータを集めて機械に与えることで,機械が自らルールを発見することができます.このことにより,これまでの機械が解けなかった問題を機械が解けるようになりました.
深層学習
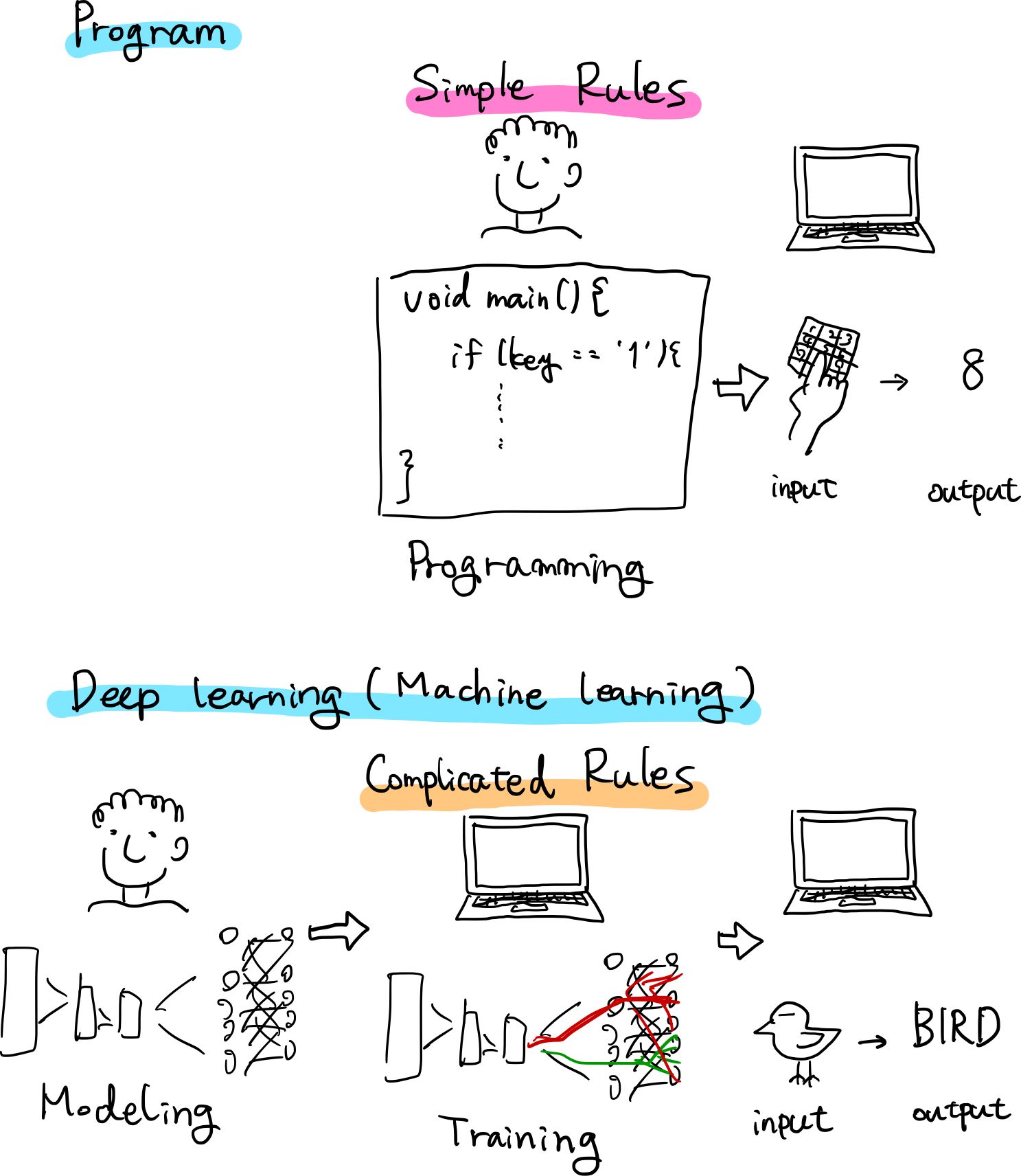
古典的プログラムと深層学習の違い
古典的プログラムは人間がある事象を観察したりしてルールを導き出して記述し,そのルールに基づいてコンピュータが演算し結果を出力します.
それに対して,深層学習は人間が用意した素材(データセット)と構成(アーキテクチャ)を元に,コンピュータがルール自体を学び,演算の結果を出力します.
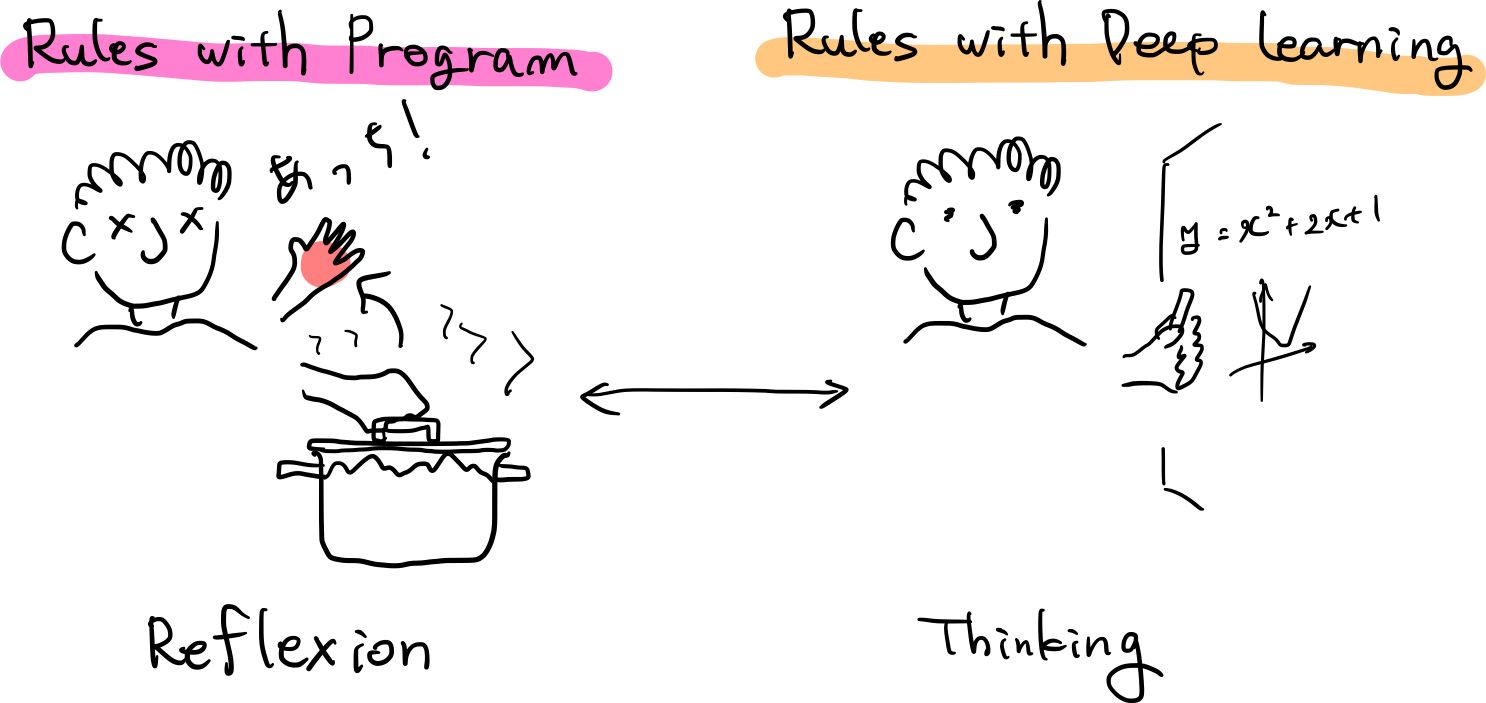
わたしたち人間が普段していることに置き換えると,
- 古典的プログラムは反射
- 深層学習は思考
と言うことができるかもしれません.
深層学習の仕組み
人間の脳はニューロン上で電気信号が伝わっていくことにより処理が行なわれます.そしてそれらは,シナプス結合の強さによって軸索から次の神経細胞への信号の伝わりやすさが変化します.
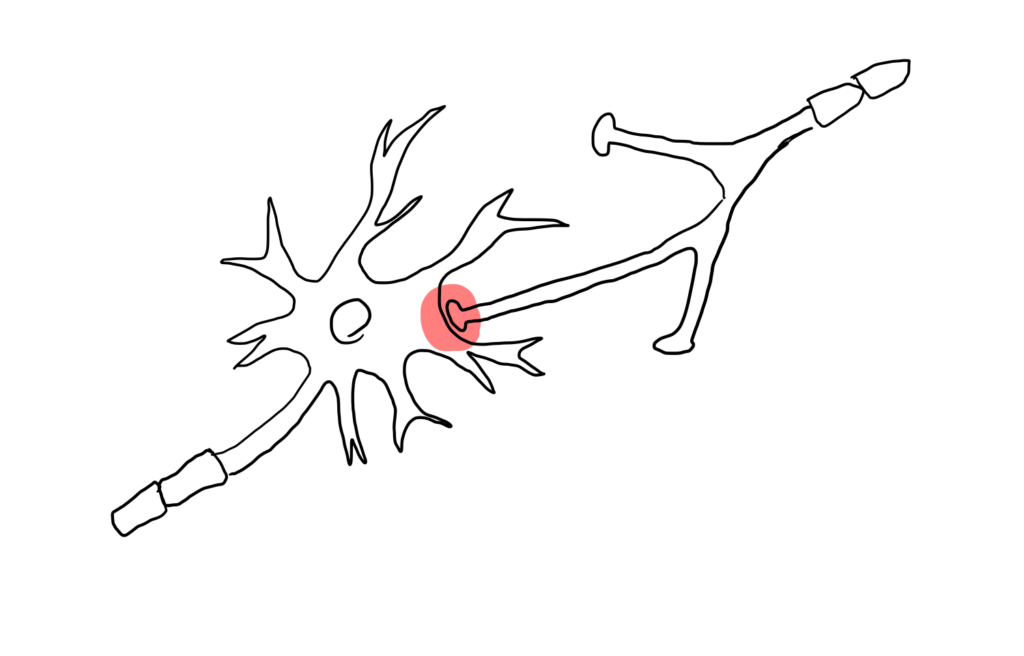
一方,人工知能の構造を画像分類を例に説明します.
- 人工的なニューロンをまず場(アーキテクチャ)として作成
- それを乱数でシナプス結合の強さを初期化
- 最終的に0-9の確率を算出
- 学習用のデータである正解ラベルを元に少しずつそれぞれの結合強さを調整(訓練,勾配法)
- 演算結果とラベルとの誤差(loss,損失関数)が少なくなると学習完了
そのモデルと結合強さ(重みW)の情報が学習済みモデルということになります.
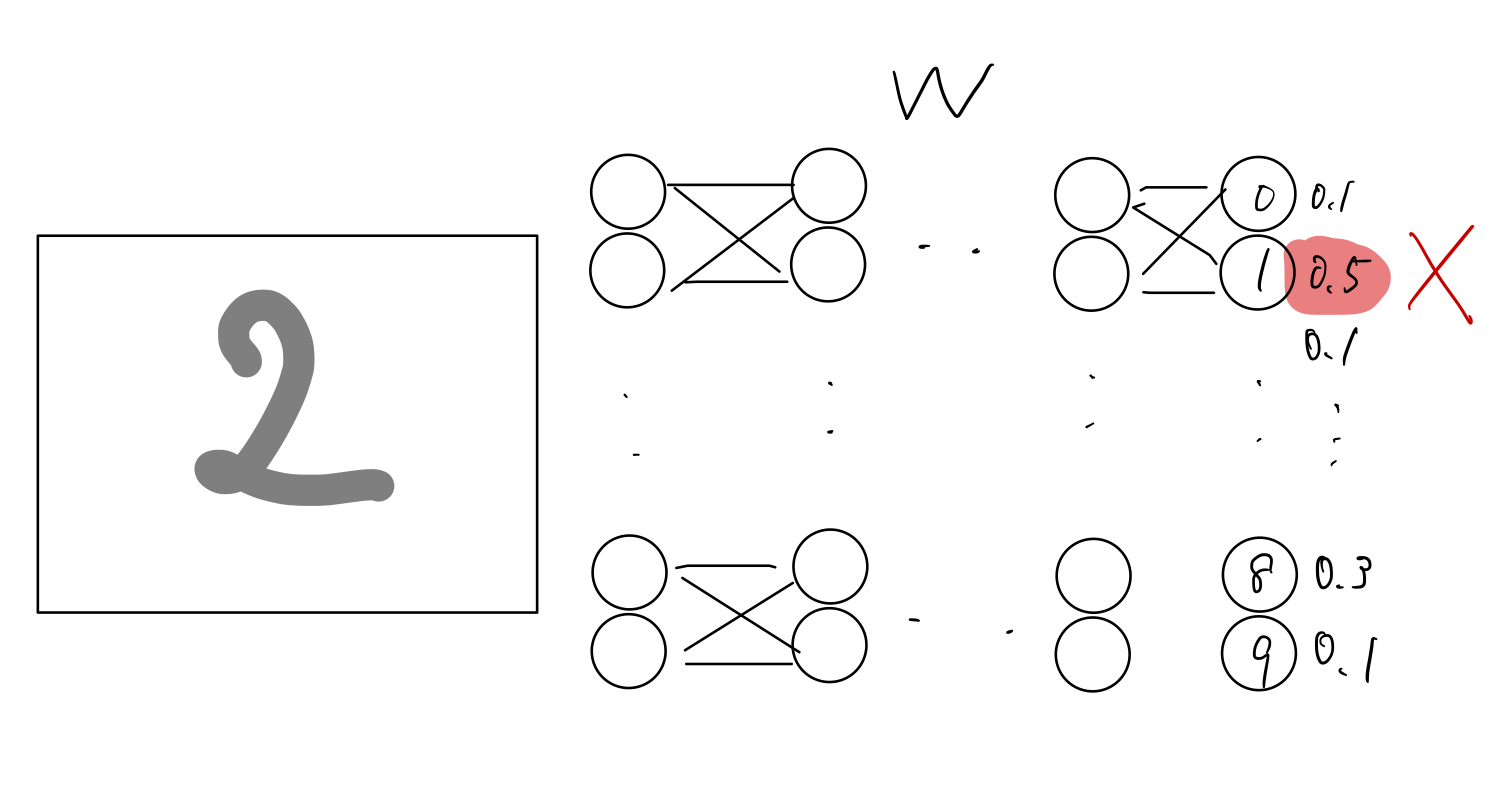
ここの中間層(隠れ層)が複数あるもののことを深層学習と言います.
E(loss): 「目標」と「実際」の出力の誤差 が小さくなるように更新していく方針で,EのWに関する微分をとり,正負からアップデートをかけて調整していきます.

どのようにAIは見るか
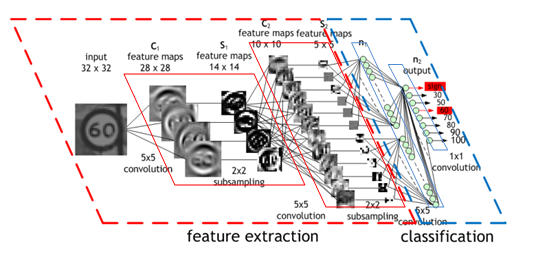
(Convolutional Neural Network (CNN) by NVIDIA より引用)
深層学習を飛躍的に発展させた1つの要素がCNNです.
CNNは単なる深層学習モデルDNNと違い,畳み込み演算(フィルター)を適用することで、画像の時空間的な依存性(隣り合ったピクセルとの関係)をうまく捉えることができます.
畳み込み演算が行われた結果の画像は図のように変化します.
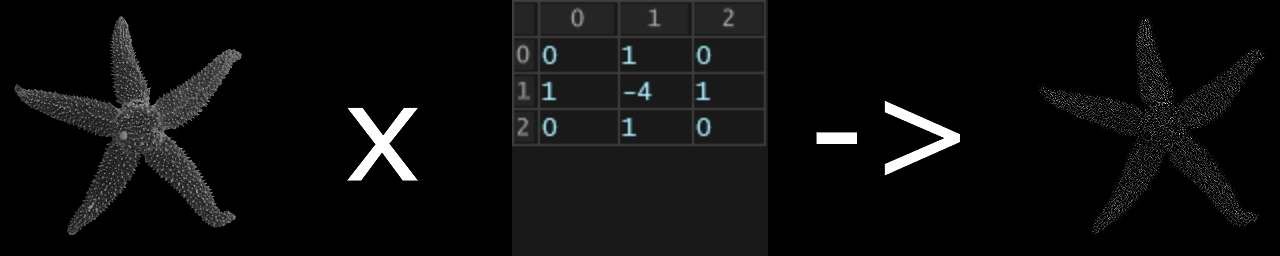
異なるフィルタを複数用いて画像を加工し,層を増やしていくことで
- 第一層: 輪郭
- 第二層: テクスチャ(質感)
- 第三層: パーツ(目,耳など)
.
.
.
などより詳細な特徴マップを得ることができます.
TouchDesignerにもConvolve TOPがあり,畳み込み演算は試すことができます.
以下の可視化動画の”Convolutional Neural Network”部分がわかりやすいです.
モデル
識別モデル
識別モデルとは,先程何度か出てきた画像分類タスクのように,入力が特定のクラスに属するか判定します.
画像分類以外にも,
- オブジェクトディテクション
- セマンティックセグメンテーション
- 深度推定
- 姿勢推定
など,数多く存在します.
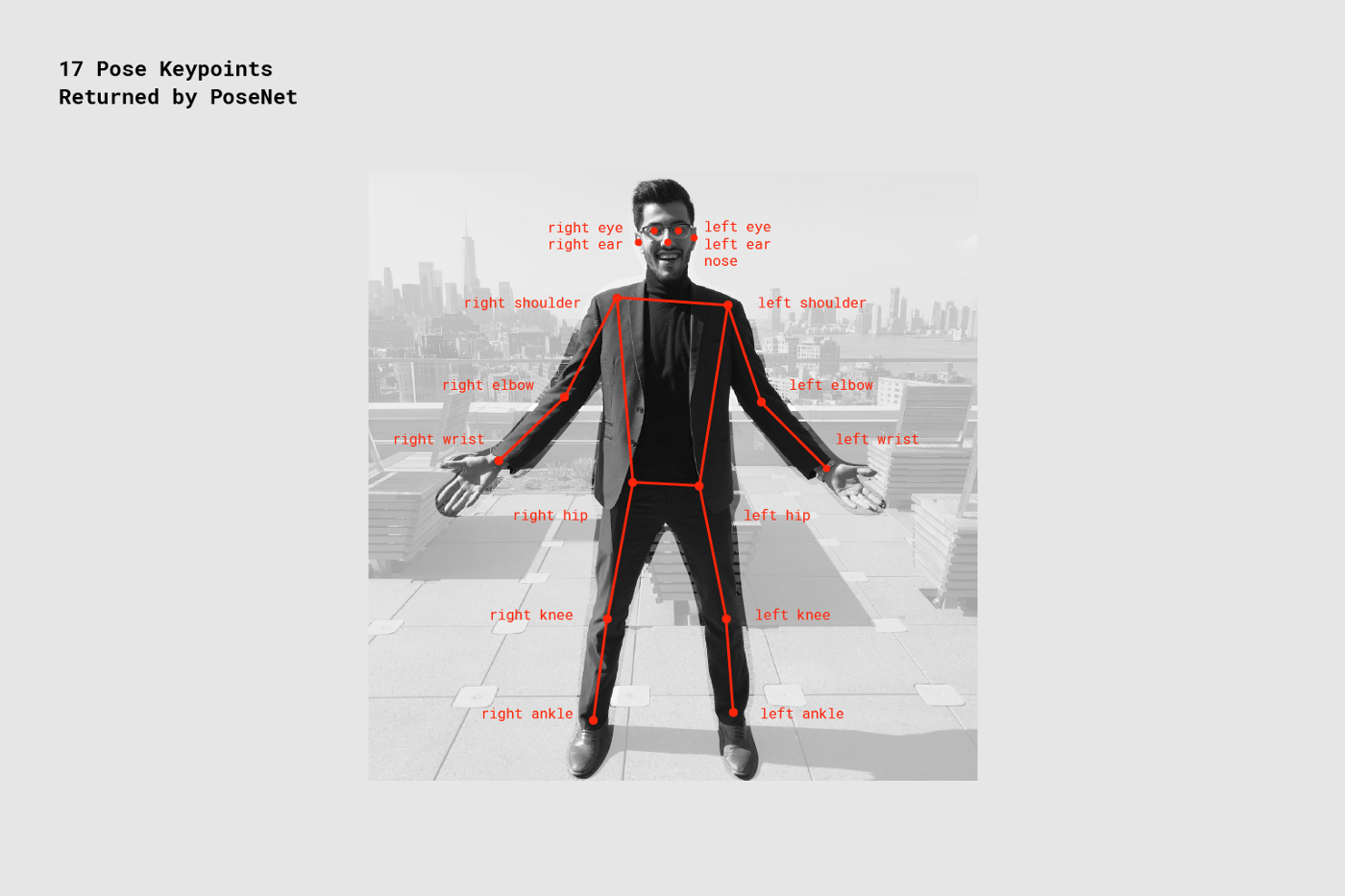
PoseNet
PoseNetは画素の情報から姿勢を推定するタスクです.
p5.js上で実行していきましょう.
文字列で関節名を指定して,特定の関節に何か描いたりすることもできます.
対応する文字列は表の通りです.
| 関節名 | 対応文字列 |
|---|---|
| 左耳 | leftEar |
| 右耳 | rightEar |
| 左目 | leftEye |
| 右目 | rightEye |
| 鼻 | nose |
| 左肩 | leftShoulder |
| 右肩 | rightShoulder |
| 左肘 | leftElbow |
| 右肘 | rightElbow |
| 左手首 | leftWrist |
| 右手首 | rightWrist |
| 左尻 | leftHip |
| 右尻 | rightHip |
| 左膝 | leftKnee |
| 右膝 | rightKnee |
| 左かかと | leftAnkle |
| 右かかと | rightAnkle |
パーツの場所の対応は画像の通りです.
Keras
KerasはTensorFlow(Googleが開発したオープンソースの機械学習用フレームワーク)が提供するニューラルネットワーク作成用の高レベルなライブラリです.簡単なコードで素早く実装可能であるため,深層学習初学者に適したフレームワークと言えます.
初学者は深層学習の入門編であるため,Kerasを用いることをおすすめします.
ライブラリ自体は
- TensorFlow
- Keras
- PyTorch
- Caffe
- Microsoft Cognitive Toolkit
- MxNet
- Chainer
など,多種多様ですが詳細にわたる説明は割愛します.
Google Colaboratory
Googleが提供するサービスで,環境構築なしにノートブック形式のPythonで行なう深層学習を始めることができます.
使用するにはGoogleアカウントが必要になります.
Google Driveと連携可能であるため,
- 学習に必要なデータセットを準備
- 学習の結果得られたモデルの保存
- 推論の結果得られた画像の保存
などのあらゆることをGoogle Drive上で行なうことができます.
プランが3つありますが,ヘビーな使い方をしなければ基本的に無料で使えます.
| プラン | 料金 | 特徴 |
|---|---|---|
| Colab Free | 無料 | 高速なGPUが割り当てられない,ランタイムが最長12時間,RAMに制限 |
| Colab Pro | 月額1,072円 | 高速なGPU割り当て,ランタイムが最長24時間,大きなRAM |
| Colab Pro+ | 月額5,243円 | より高速なGPU割り当て,ブラウザを閉じても実行を継続,,より長いランタイム,より大きなRAM |
最近のモデルではネットワークもデータセットも膨大であることが多く,自身で用意したデータセットで学習させようと思うとRAM関係でエラーが出たりすることが多くなってきます.
Colabを使ってみる
Google Colaboratoryのページを開きます.
https://colab.research.google.com/?utm_source=scs-index
次に,File>New Notebookを選択して新しいNotebookを作ります.

Googleアカウントにサインインしていない場合はサインインを促されるため,ログインします.
このような画面になれば開始できます.
CIFAR-10の分類モデルの学習と推論の実行
以降は学習のパラメータの説明も兼ねてこちらを実行しながら進めていきます.
CIFAR-10分類モデルColabリンク
作品例
UNLABELED
AIに抵抗するプロジェクトの一例として,UNLABELEDというプロジェクトを紹介します.このプロジェクトは,一言で言えば,AIの検出から逃れる服を作るプロジェクトです.
近年では,様々な場所に監視カメラが設置され,私たちの生活は常に監視の目に晒されることになりました.そしてそのカメラにAIが搭載されていた場合,私たちの情報はAIによって解析・識別されてしまいます.実際に中国では,そのようなAIを搭載したカメラによって個人を監視するようなシステムがある程度完成しています.
そのような社会では,私たちの情報は収集・解析されてしまい,私たちのプライバシーは大きく脅かされることになってしまいます.その中で,私たちはどのようにして自分のプライバシーを守れば良いのでしょうか?
その手段として,このプロジェクトではAIに誤認識されやすい服を制作しました.この服を纏うことで,AIを搭載した監視カメラによって人間と認識されなくなり,データ化され監視されてしまうことから逃れることができます.
ベースとなっているのは,Adversarial Exampleという技術です.このAdversarial Exampleとは,簡単に言えば,AIに対する脆弱性攻撃のようなものです.説明としては,よく以下の画像が使用されます.
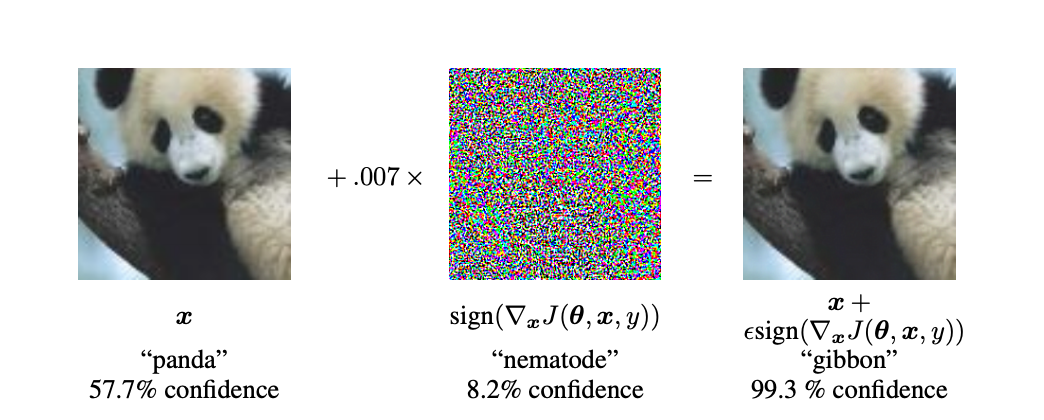
(「Explaining and Harnessing Adversarial Examples」より引用)
元々,左の画像は57.7%の確率でパンダとして認識されていました.この画像に微弱なノイズ(真ん中の画像)を加えた結果(右の画像),AIはこの画像を99.3%の確率でテナガザルとして認識しました.皆さんの目から見て,右の画像はテナガザルに見えるでしょうか?
このように,とある画像に対して,人の目には判別できないほどのノイズを加えることでAIを騙すことができてしまう事例が報告されており,Adversarial Exampleと呼ばれています.このAdversarial Exampleは画像に限らず,文章や音楽など他の領域においても報告されています.
その後,このAdversarial Exampleの考え方を応用したAdversarial Patchという手法が登場しました.以下の動画が,実際のデモ動画になります.
この動画では,YOLOv2という物体認識モデルを使用して,画面に映る物体が何であるかをリアルタイムに判別しています.何も持っていない男性はpersonとしてAIに認識されていますが,一枚の紙をもった男性はpersonとして認識されていません.この紙がAdversarial Patchです.このAdversarial Patchを持つことで,YOLOv2という物体認識AIからはpersonとして認識されなくなります.
そして,このAdversarial Patchを発展させてUNLABELEDが生まれました.Adversarial Patchのように,YOLOv2という物体認識AIから人としてされなくなる上,紙ではなく服を開発しました.服を開発したことにより,常に身に纏い街へと出かけることができるようになりました.


かつて,戦場にて身を隠すために迷彩柄が生み出されました.周りの景色と溶け込むような柄を見に纏うことで,自らの身を守っていたのです.あらゆる場所に監視カメラが設置されるようになった現代では,かつての戦場のように,監視カメラから自らの身を守る必要があります.その手段として,UNLABELEDのような現代の迷彩柄を見に纏う,といった方法も考えられるのでしょう.
Threshold (2019) Martin Adolfsson
自身のスマホ上の過去に撮影された写真と比べて,似ている場合は写真を撮らせてくれないアプリケーションです.
写真が撮れなくなる,という体験を通して自分がこれまで撮ってこなかった写真撮影に強制的に挑戦させられることは独創的な写真を生む可能性があります.
また,アプリを活用して自分が撮ってきた写真の特徴を意識することは,自分自身で判断することが難しい側面があることを考えると,意義深いでしょう.
A Computer Walks Into a Gallery (2018) Philipp Schmitt



コンピュータの検出結果を視覚化したこのインスタレーションは,鑑賞者が作品を別の方法で見ることで,新しい見方で作品を鑑賞することを促します.
Perception Engines (2017) Tom White

シンプルな線や円を使った描画を行ない,随時画像分類にかけて目的のオブジェクトの確度が高くなるように線や円を動かしていきます.
コンピュータが見立て可能であるという判定のみを使った抽象的な絵を描くことによって,これまでの絵画などの発想と全く異なる風合いの抽象画を作っています.


Evolutionary faces (2020) Matty Mariansky
曲線を描くペンプロッターを制御するモデルと顔認識アルゴリズムを敵対的に学習させることで,人間にとっては顔に見えるけれども認識されないイラストを生成します.
Perception Enginesとはまた違った抽象的なグラフィックを生成することに成功しています.