目次
監視社会とAI
コンヴィヴィアリティとAI
見立てとAI
- 見立てとは
- パレイドリア
- パレイドリアの歴史
- Reversing Rorschach
- 分子度
- 機械の見立て
- Grid Corrections (2018) Gerco de Ruijter
- Cloud Face (2012) Shinseungback Kimyonghun
- Unseen Portraits (2014) Philipp Schmitt and Stephan Bogner
- Cat or Human (2013) Shinseungback Kimyonghun
- Altergraph (2021) Scott Allen + Ryosuke Nakajima
- Threshold (2019) Martin Adolfsson
- A Computer Walks Into a Gallery (2018) Philipp Schmitt
- Perception Engines (2017) Tom White
- Evolutionary faces (2020) Matty Mariansky
複雑性とAI
監視社会とAI
監視社会
わたしたちは普段色んなカメラに接して生活しています.一日生活してみていくつのカメラが自分の周りにあったか数えることができるでしょうか?スマートフォンやPCのウェブカメラなどの意識しやすいものもあれば,監視カメラなどの普段あまり意識しないものまで様々です.
ここではその意識しない側の存在である監視カメラについて考えてみたいと思います.
CCTV
CCTVとはイギリスの監視カメラシステムです.現在イギリス全体で約600万台の監視カメラが存在します.イギリスより国土の広い日本はその1/100程度の監視カメラがあるようですが,それでも多いように感じる方もいるかもしれません.
もともとは防犯目的でイギリス政府が推進してきたプロジェクトで,ロンドン同時多発テロなどを契機にかなり拡大したようです.これが犯罪の抑止力になるかどうかという議論はさておき,このような徹底的に監視された状況で一市民として何を感じるでしょうか.
Pros
- 犯罪に遭う確率が減って嬉しい
- 犯罪に遭っても犯人が見つかる確率が上がって嬉しい
Cons
- カメラの死角はより危険な場所になるのではないか
- 防犯以外の目的で記録されているのではないかと不安になる
- ちょっとした交通違反などでも徹底的に監視されて気が抜けない
など,色々なことが想定されると思います.
近年,AIベースのコンピュータビジョンの発達によって,より高度な分析がなされていることは間違いありません.
この状況を踏まえた上で,どのように生きていくかという問題を各々が考えていく必要があるかもしれません.
データセットとプライバシー
前回大量の画像をデータセットとして学習するプロセスを経ることで,AIが高次元の特徴を捉えられるようになるということがわかりました.しかし画像を集めようにも,著作物の無断のダウンロードや使用は禁止されているため,既存の絵画を学習して新しい絵画を生成したりすることは難しいように思います.
実は,著作権法47条の7では情報解析(深層学習含む)目的では自由に著作物を使用できる旨が記されています.しかも,商用であっても可能です.
今後深層学習に取り組むことがある場合は,利用範囲に注意しつつ慎重にデータを集めるようにしましょう.
みなさんが使うサービスには,今後のサービス向上のためのユーザー情報の提供の同意確認がよくあります.
このように個人情報などを含むデータは厳重に扱われています.
しかし,一度SNSやウェブサイトにアップロードされた写真や個人情報は誰でも閲覧可能です.
アメリカではClearview AIという企業がスクレイピングにより収集した顔画像などのデータが,FBIをはじめとする多数の法執行機関によって利用されてることがわかりました.
I Got My File From Clearview AI, and It Freaked Me Out
なにげなく利用しているSNSからかなり詳細なデータが収集されていることが現実に起きている現在,これらのテクノロジーとの付き合い方について再考してみても良いかもしれません.
AIを誤用する
誤検出させる
REALFACE Glamouflage
REALFACE Glamouflageは,顔認識アルゴリズムを混乱させるように設計されたTシャツのコレクションです.
この作品の当時,Facebookにおける写真のタグ付け機能が流行していました.この機能は,画像をアップロードするだけで個人を識別しタグ付けしてくれるという便利な機能ではありますが,そのアルゴリズムの詳細については明らかになっていません.かつては写真にタグを付けるという行為は,自らが能動的に行う行為でしたが,この機能が開発されて以降は,Facebookの提案を受け入れるという受動的な行為へと変化していきました.
かつては任意の機能としてタグ付け機能が存在していましたが,Facebookによる自動タグ付けが普及して以降は,以前にも増して顔というものがある種の価値を持つようになりました.タグ付けされることでプロフィールにも表示されやすくなり,「いいね」も集めやすくなります.元々SNSに顔写真をアップロードすることはリスクも孕んでいましたが,自動タグ付けによってアップロード行為は促進されることにも繋がりました.
そのような背景の中で,REALFACE GlamouflageはFacebookの顔認識アルゴリズムを混乱させることを目的として制作されました.以下のように,有名人の顔画像をTシャツに貼り付けることで,顔認識アルゴリズムはそれらの画像を顔として認識し,余分なタグを付与します.

このTシャツを着ることで余分なタグが付与され,着ている人の情報はある程度分散させることができます.顔認識アルゴリズムを混乱させることで,個人のプライバシーを守ることができているわけです.顔認識アルゴリズムが一般に普及した現代の社会においては,このようなデザインが自らの身を守る役割を果たすのかもしれません.そのようなアルゴリズムから身を守るにはどうすれば良いのか,その解決策について私たちに導線を与えてくれるような作品です.


(画像は https://www.designforsustainability.info/signals/realface-glamouflage より引用)
検出から逃れてみる
どうすれば検出から逃れることができるのか,実際にOpenCV(Open source Computer Vision)ベースの顔認識プログラムを動かして試してみましょう.
プログラムではなく,映り込む自分自身の見た目を変化させることによって,自分の顔が認識されなくなるように工夫してみましょう.
今回もGlitch.comのテンプレートから必ずRemixして自身のプロジェクトとして編集できる状態にしてから作業してください.
OpenCV face detection template
要件
- 認識されている証拠である赤い四角が見えない状態にすること
- 本人であることは認識できるようにすること
検出から逃れる
UNLABELED
次に,AIに抵抗するプロジェクトの一例として,UNLABELEDというプロジェクトを紹介します.このプロジェクトは,一言で言えば,AIの検出から逃れる服を作るプロジェクトです.
近年では,様々な場所に監視カメラが設置され,私たちの生活は常に監視の目に晒されることになりました.そしてそのカメラにAIが搭載されていた場合,私たちの情報はAIによって解析・識別されてしまいます.実際に中国では,そのようなAIを搭載したカメラによって個人を監視するようなシステムがある程度完成しています.
そのような社会では,私たちの情報は収集・解析されてしまい,私たちのプライバシーは大きく脅かされることになってしまいます.その中で,私たちはどのようにして自分のプライバシーを守れば良いのでしょうか?
その手段として,このプロジェクトではAIに誤認識されやすい服を制作しました.この服を纏うことで,AIを搭載した監視カメラによって人間と認識されなくなり,データ化され監視されてしまうことから逃れることができます.
ベースとなっているのは,Adversarial Exampleという技術です.このAdversarial Exampleとは,簡単に言えば,AIに対する脆弱性攻撃のようなものです.説明としては,よく以下の画像が使用されます.
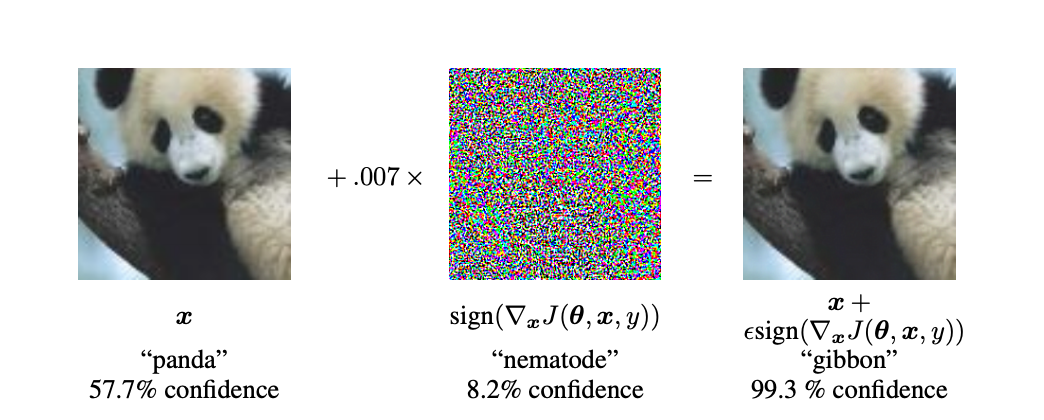
(「Explaining and Harnessing Adversarial Examples」より引用)
元々,左の画像は57.7%の確率でパンダとして認識されていました.この画像に微弱なノイズ(真ん中の画像)を加えた結果(右の画像),AIはこの画像を99.3%の確率でテナガザルとして認識しました.皆さんの目から見て,右の画像はテナガザルに見えるでしょうか?
このように,とある画像に対して,人の目には判別できないほどのノイズを加えることでAIを騙すことができてしまう事例が報告されており,Adversarial Exampleと呼ばれています.このAdversarial Exampleは画像に限らず,文章や音楽など他の領域においても報告されています.
その後,このAdversarial Exampleの考え方を応用したAdversarial Patchという手法が登場しました.以下の動画が,実際のデモ動画になります.
この動画では,YOLOv2という物体認識モデルを使用して,画面に映る物体が何であるかをリアルタイムに判別しています.何も持っていない男性はpersonとしてAIに認識されていますが,一枚の紙をもった男性はpersonとして認識されていません.この紙がAdversarial Patchです.このAdversarial Patchを持つことで,YOLOv2という物体認識AIからはpersonとして認識されなくなります.
そして,このAdversarial Patchを発展させてUNLABELEDが生まれました.Adversarial Patchのように,YOLOv2という物体認識AIから人としてされなくなる上,紙ではなく服を開発しました.服を開発したことにより,常に身に纏い街へと出かけることができるようになりました.


かつて,戦場にて身を隠すために迷彩柄が生み出されました.周りの景色と溶け込むような柄を見に纏うことで,自らの身を守っていたのです.あらゆる場所に監視カメラが設置されるようになった現代では,かつての戦場のように,監視カメラから自らの身を守る必要があります.その手段として,UNLABELEDのような現代の迷彩柄を見に纏う,といった方法も考えられるのでしょう.
CV Dazzle
CV Dazzleは,Adam Harveyにより制作された,顔認識システムから逃れるためのヘアスタイル/メーキャップ術です.
先述したように,現代ではあらゆる場所にカメラが設置され,私たちのセキュリティやプライバシーは常に危険に晒されています.そのような状況下で,ヘアスタイルやメーキャップを使うことでカメラから自らを迷彩することを目的としています.
CV Dazzleでは,ダズル迷彩という迷彩をベースとしています.ダズル明細は第一次世界大戦中に多く見られた迷彩パターンで,艦船の船体外装に全面的・全体的に塗装して施されました.迷彩とは本来,周囲に溶け込むことを目的とするため,ダズル迷彩のような目立つパターンは一見逆効果のように思えます.しかし,ダズル迷彩においては敵艦隊の射撃システムを困惑させることを目的としているため,このような派手なパターンとなっています.つまり,何を目的とするかによって,迷彩のパターンというのも状況ごとに変化していくのです.

ダズル迷彩を施されたエンプレス・オブ・ロシア(1918年)(画像はWikipediaより引用)
このCV Dazzleは全ての顔認識アルゴリズムに対して機能するわけではなく,Viola-Jonesアルゴリズムを使用したアルゴリズムに対してのみうまく機能します.以下の動画は,Viola-Jonesアルゴリズムの実際の動作を視覚化したものです.
このアルゴリズムでは,長方形の領域ごとに計算を実行し,明るい領域と暗い領域の違いを分析します.その領域内に顔が存在するかどうか判別するためにさまざまなスケールでスキャンを実行し,顔があると認識された場合には赤い長方形でマークされます.そしてこの赤い長方形が複数個重なった場合にのみ,顔が存在すると認識されます.そのため,単に濃いメイクアップをするだけでは顔認識アルゴリズムを騙すことはできません.
そこでCV Dazzleは,前衛的なヘアスタイルやメーキャップを使い顔の連続性を隠しすことで,顔認識アルゴリズムを騙すことに成功しました.うまく騙すためのポイントとしては,左右を非対称にすることや,顔の輪郭を隠すことが効果的なようです.



この例では,髪型によって顔の輪郭は隠れ,さらに右頬のメイクによって顔の左右は非対称になっており,うまく顔認識アルゴリズムを騙すことができています.他にも,以下のようなパターンで成功を収めています.



(画像は https://cvdazzle.com/ より引用)
このようにCV Dazzleでは,顔認識アルゴリズムの特性を分析することで,逆に顔認識アルゴリズムを騙すことに成功しました.この作品は2012年の作品ですが,当時の段階ですでに監視カメラなどの普及に伴うセキュリティー/プライバシー侵害は大きな問題となっていたことがわかります.その対抗手段としてヘアスタイルやメーキャップを活用するという視点を見出したアーティストAdam Harveyの視点は大きな意義を持つでしょう.
INCOGNITE
INCOGNITEは顔認識システムから逃れるためのアクセサリです.
CV Dazzleと同様のコンセプトではありますが,眼鏡のように着脱可能である点でとても有用であると言えます.


identity disperser -afforestation-
identity disperser -afforestation-は自分に似ているけど少し違う顔をSNS上に氾濫させて写真やアイデンティティの意味を揺らがせることを試みるプロジェクトです.実際に画像をSNSにアップロードすると,本人であると認識されなくなります.
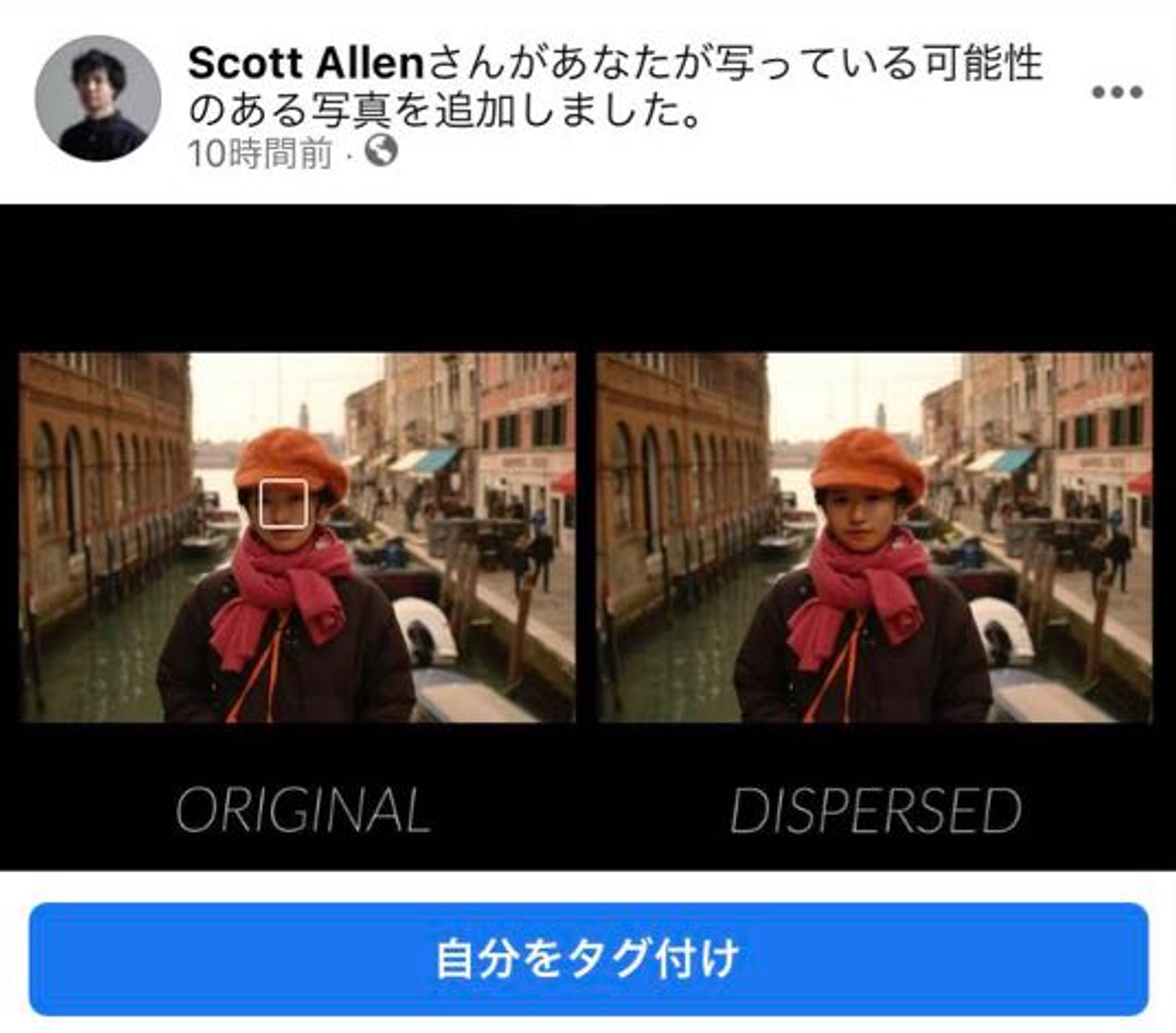
How To Avoid Facial Recognition
この作品は,Kyle McDonaldとAram Barthollによる,アナログな方法で顔認識アルゴリズムを回避するための一連の方法の実験です.これまで紹介してきた事例では,デジタルな手法を用いて顔認識アルゴリズムを騙すような事例が多くありましたが,この作品では,誰でも実践可能なアナログな方法を模索している点が異なります.
まず,彼らは以下のようなマスクを装着します.この場合にはほとんど顔が見えないので,もちろん顔認識アルゴリズムを騙すことは容易いでしょう.

次に,透明なマスクを装着します.マスクが光を反射するため,顔認識アルゴリズムがきちんと動作しなくなるのでしょう.

そして最後に最もアナログで簡単な方法として,顔を傾けるという方法を紹介しています.特別な道具や準備は何も必要とせず,誰でも気軽に実践できるという点で,効果的であると言えるでしょう.

街中で皆で実践している様子.

こうした取り組み自体はとてもユーモラスに思え,監視社会というディストピア的な未来に対して,私たちができることは何があるのか,希望的な見地を与えてくれます.現在のAIをベースとした顔認識システムに対してはこの方法はうまく機能しない可能性はありますが,私たちの想像力次第で,新たな方法が発見されるかもしれません.
コンヴィヴィアリティとAI
最適化される社会
現代社会においては,様々なシステムが洗練化・合理化され私たちの生活は大変便利になりました.とりわけAIを用いたシステム,例えば翻訳システムや顔認証システムなどは近年目覚ましい進歩を遂げています.こうしたAIシステムは最適化を押し進める一方で,個々人が秘める多様性が失われてしまう危険性を孕んでいます.
スキナーボックス
個々人が秘める多様性が失われてしまう状況をスキナーボックスを例に説明したいと思います.
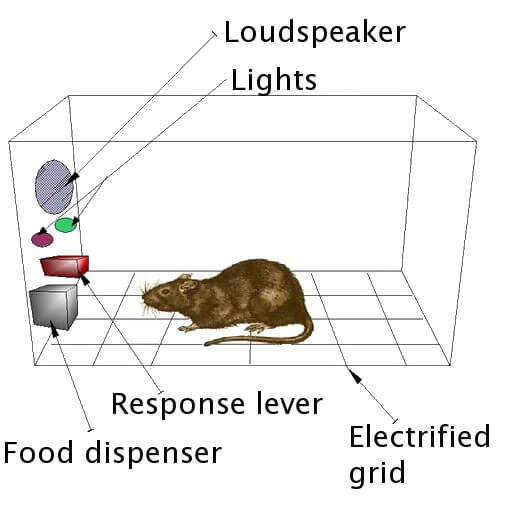
スキナーボックスとは,刺激と反応の関連付け(オペラント条件づけ)を行なう実験箱のことを指します.
ねずみはライトがオンになったのを合図にレバーを倒すことで,フードディスペンサーから餌を得ることができます.そのように簡単なプロセスで餌が手に入るようになると,ねずみはやがて,自分自身で餌を得ることをしなくなります.つまり,この合理化,洗練化されたシステムをラットは享受し,本来の狩りの能力を放棄してしまうことになります.さらに,餌はフードディスペンサーから得られるものだけに限定されてしまいます.
普段のわたしたちはどうでしょう?
- メモしなくても,またGoogle検索すれば良い
- 翻訳システムも精度が高いので,自分で勉強する必要はない
- 音楽はレコメンドシステムで適当に聴いていても良いアーティストにたどり着ける
- 適当にFacebookに画像をアップするとタグ付けの提案をしてくれて便利
など,粒度の違いはあれど,スキナーボックスと同じ状況が人間社会に起こっていると言わざるを得ません.
コンヴィヴィアリティとは
イヴァン・イリイチは著書「コンヴィヴィアリティのための道具」で,コンヴィヴィアリティを
- 人間の自立・創造性・自由・公平を保障するような道具(や制度)のありかた
- 使用価値をつくり出す自由があり、その自由が公平に配分されるような道具(制度)のありかた
- 過度な「合理化」になんらかの制限・抑制をあたえることによって実現
として,合理化追求型のモデルなどを例示・比較して論述しています.
最適化された社会システムとコンヴィヴィアルに付き合うことができれば,スキナーボックスのような状況は防げるかもしれません.
自転車
イリイチは自転車をコンヴィヴィアルな道具として例示しています.
人間の移動する能力を増強し,過度な最適化や暴走もない絶妙な道具であると言えます.
それ以上の最適化が起こると,自動車の虜となってしまいます.
コンヴィヴィアリティを担保するには
| 項目 | 詳細 | 例 |
|---|---|---|
| 生物学的退化 | 人工的な環境により自然の中で生きる力が失われる | 公共交通機関 |
| 根元的独占 | 代替できない独占による依存を招く | Googleマップ |
| 過剰な計画 | 創造性や主体性を奪い,思考停止させる | シンプルなUIのアプリ |
| 二極化 | 独占する側・される側に分かれる | SNS |
| 陳腐化 | 既存のものの価値を過小評価する | スマートフォン |
イリイチは表のような項目が起こっていると,2つめの分水界を越えていると説明しています.
逆に言えば,これらに注意することで,道具が一定の洗練度を越えてしまわないようにコントロールすることができそうです.
では,すでに社会に実装されてしまっている過度な最適化・合理化システムと対峙した時はどうでしょうか?
考えられる対策は大きく分けて2つありそうです.
- 既存の合理化システムからコンヴィヴィアリティを探索する
- 合理化システムを放棄する
しかし,イリイチは2のように合理化システムを単に放棄して先祖返りするということは主張していません.
ではどうやって1のように既存の合理化システムからコンヴィヴィアリティを探索していくのでしょうか.
誤用する
誤用はここでは道具の想定されていない使い方を指します.
これによって,既存の合理化システムを使いつつ想定されない多様な出力を得る事が可能になります.
道具の作成者の想定から逸脱するという行為は過度の最適化からも逃れることができるため,コンヴィヴィアルということができるでしょう.
では具体的に誤用の例を見てみます.
手法例
DJ scratching
もともとレコードはスクラッチなどせず,音楽を聴くためのものでしたが,スクラッチにより独特の音を出すことができます.さらに楽器のような身体化が必要で,スクラッチによってDJは大きくアップデートされたと言えます.
Circuit bending
回路を繋ぎ変えたり部品を加えることで,楽器として使用します.
作品例
Dog Star Man (1961) Stan Brakhage
フィルムを物理的に削ることで独特の表現(シネカリ)を得た作品です.
Demi-pas(Half-step) (2002) Julien Maire
既製品を分解したり自作のモジュールを使用することで,単なる映写機やプロジェクターでは出せない独特の映像表現を得ている作品です.
思い過ごすものたち (2013) 谷口彰彦
iPadとそのアプリケーションを想定されない使い方で”思い過ごし”を起こしています.
AI DJ Project (2018) Qosmo Inc.
AI DJ ProjectはAIにバックトゥーバックで選曲させます.
AIは最適化のための存在のように考えられていますが,このプロジェクトでは敢えて人間の模倣はさせずに,曲の特徴から次にどの曲をかけるか選択させています.
そのため,思いも寄らないアーティストが提案されることもあるようですが,そのときこそ人間の選択しそうな範疇を越えた興味深い表現になります.
過去にアーティスト別で提案するようなAIのモデルを作成したときに,それっぽい・攻めていないもの(マイケル・ジャクソンをかけると間違いない など)ばかり提案してしまう経験があったため,敢えて模倣させないスタイルになったとのことです.
単なる最適化をさせないというのは,AIを使用するときに必須になってくるかもしれません.
見立てとAI
見立てとは
- 選ぶ
- 定める
- 診断する
- 見栄え
などがありますが,今回の見立てとデザインで扱う「見立て」は,
あるものを別のなにかとして見ること
とします.
「見立てる」ことはその類似性をもとに連想し,認識を改めていく行為であると言えます.
日本の文化には古くから「見立て」が関係しています.
日本文化と見立て

茶の間では意図的に完成形ではない状態にする,あるいは空間的に満たされていない状態を作ることで,想像の余地を与えられた利用者が,自分なりに見立てを行なって屏風などで仕切ったり,掛け軸など装飾を施したりします.これは全く特別なことのようには感じませんが,西洋の文化と固定型の空間様式と比較すると大きく異なることがわかります.それらは当然茶道などの日本の文化にも色濃く反映されています.

日本庭園などにも見立ての概念は反映されています.
庭石などは,見立てによって単なる石ではなく亀石や鶴石など特別な意味を持つものとして扱われたりします.
このように日本人は古くから,見立てることで想像力を膨らませてきたことがわかります.
教育と見立て
美術やデザイナー,教育者として様々な顔を持つブルーノ・ムナーリの提唱した教育方法のうちの一つに不定形な紙に絵を描くワークがあります.
破られた紙に対してスケッチをすることで,先入観を排して,子どもたち一人ひとりが紙を何かに見立てていきます.
動物に見立てて顔を描く,穴を利用してお面を作る,など様々な見立てが起こり,多様な表現が立ち現れます.
子どもたちに能動的に観察,想像,発見させ,自身で考えることを促されるのです.
このように教育的観点からみても,見立ての重要性は言うまでもなさそうです.
パレイドリア
パレイドリアとは,あるものが他のものとして認識される現象のことを言います.
写真を見てみましょう.






これらはよく見ると動物や人のように見えてきます.
また,特に人に見える現象をシミュラクラと言います.
ここでは,パレイドリアと創造性について扱ってきます.
パレイドリアの歴史
パレイドリアという言葉自体は,心理学分野の用語でドイツの精神科医カール・ルートヴィヒ・カールバウムが彼の論文「感覚の妄想について」(1866)で最初に使用しました.その後,ポーランドの精神科医であるシモン・ヘンスがそれを発展させ,非自発的想像力を測る「子供,健康な成人,精神障害者のインクブロットを使用したファンタジーのテスト」(1917)という論文を発表しました.そして,スイスの精神科医ヘルマン・ロールシャッハはインクブロットに見られるパレイドリアを使用して,人の性格を調査して心理状態を評価したロールシャッハ・テストを発表します.

Reversing Rorschach
リチャード・グレゴリーはnatureのエッセイの中で,リバーシングロールシャッハを提唱しています.
ロールシャッハ・テストは描かれたインクブロットに対して,(パレイドリアによって)何を想像するかという検証であることに対して,
リバーシングロールシャッハはパレイドリアを引き起こす絵を描かせる検証を行ないます.
このテストを行なった結果,芸術や音楽に強い関心を持つ参加者は,全体としてより独創的なパレイドリアの絵を描いたようです.
つまり,独創性や創造性とパレイドリアの視点が大きく関わっているということがわかります.
パレイドリアを誘発する絵を描く能力というのは,言い換えると見立てる能力ということができます.
この能力を育てることで,創造性を養うことができるかもしれません.
分子度
リチャード・グレゴリーは上記エッセイで,「分子度」という概念についてもmagnetic poetryを例に述べています.
magnetic poetryとは冷蔵庫に貼って使用するような,磁石のプレート上に英単語が書かれたものです.
複数の磁石を並べることによって文節や文章を作っていくような子供用のおもちゃです.

ここで,彼は
- 「原子的」(一文字単位)すぎると,関連性や概念を示唆することができない
- 「分子的」(文章単位)に説明しすぎると,独創性を阻害する
と述べています.
細かすぎると組み立てられず,粗すぎると他の可能性を考えられなくなる
というようなニュアンスです.
そして彼はその分子的である度合いを「分子度」と名付けました.
ではmagnetic poetryを応用して,人間のパレイドリアについて具体例で考えてみます.

- 左: 砂利が乱雑に散らばっている状態は,それぞれの石の粒以上の全体の関連性を見出だせない
- 中央: 家のパーツが程よい規則によって,人の顔のような「目」「鼻」「口」を見出すことができる
- 右: 人間の顔はもう顔にしか見えず,独創的な連想は得られない
のように程よい分子度によって見立て可能性が高まると言えます.
ちがうみかたで
以下のOpenCVベースのプログラムをスマホのウェブブラウザで開き,顔ではないのに顔として検出されてしまうものを探してきましょう.
以下のObject Detectionのプログラムをスマホのウェブブラウザで開き,誤検出されてしまうものを探してきましょう.
機械の見立て
これまで,見立てと創造性の関係について扱ってきました.
ここでは機械によって見立てを行なっている作品を紹介します.
Grid Corrections (2018) Gerco de Ruijter
こちらはコンピュータの力ではなく,人力で類似した画像を並べて表現された作品であるため,コンピュータの力によって見立てた作品と区別しつて考える必要がありますが,ことのようなそれぞれが関連のないものを並べ替え連続的なアニメーションとして見立てる作品はとても独創的です.
他にも以下のような作品があります.
こちらは画像をグリット状に並べて表示したり,多少脚色することによってアニメーションとしての見応えを演出しています.
Cloud Face (2012) Shinseungback Kimyonghun
Cloud Faceは,韓国のアーティストShinseungback Kimyonghunによる作品です.まずは,以下の動画をみてください.
Cloud Faceは,AIの顔検出アルゴリズムによって顔であると認識される雲の画像を集めた作品です.これらの画像は,AIによる誤認識,エラーの結果です.一方で,私たち人間も雲の中に顔を発見することがよくあります.ここで,AIのエラーと私たちの想像力とが交差することになります.




一般的に,AIによる誤認識はエラーとして否定的に捉えられます.もちろん,例えば画像解析による異常検知など,AIに正確な結果が求められる場面は多々あります.AIにエラーが多発するとなれば,そのようなAIを利用したシステムは非常に不安定で信用に欠けるものになってしまうでしょう.それでは,AIによるエラーは悪であり必ず避けなければならないものなのでしょうか?
Cloud Faceを例にとって考えてみましょう.Cloud Faceは,AIによって顔であると認識された雲の画像を集めた作品でした.これらの画像は実際には雲であり,顔ではありません.そのため,エラーであると捉えられるわけです.
しかし,Cloud FaceにおけるAIのエラーは,私たち人間が持つ想像力と非常に近いように思えませんか?顔でない画像から顔を見出す,それはまさに人間の想像力によってもたらされるものであり,AIのエラーはそれと非常に近しい現象であると考えることもできるわけです.
画像認識とは本来,そこに映っているもの正しく認識するための技術として想定されています.しかしこの作品では,あえて想定されていない使い方をすることで,非常にユニークで興味深い画像を集めることに成功しているのです.
Unreal Pareidolia (2023) Scott Allen
見立てを機会に委ねてみる作品として作ったインスタレーションです.
Unseen Portraits (2014) Philipp Schmitt and Stephan Bogner
顔認識で監視し続けて,人と認識されない瞬間を探す作品は数あれど,顔を変化させるときの崩し方が特徴的な作品です.

Cat or Human (2013) Shinseungback Kimyonghun



人間の顔を猫の顔として認識する「猫顔検出アルゴリズム」(OpenCV),人間の顔検出アルゴリズムによって人間の顔として認識された猫の顔(KITTYDAR)を左右に並べた作品です.
猫に分類される人の顔がそういうものとして見ていると確かに見えてきたり,猫も凛々しい人に見えてきたりする,「見立て」られた瞬間にそう見えてしまう不思議があります.
Altergraph (2021) Scott Allen + Ryosuke Nakajima
顔認証を使い「顔のように見える植物」を探すなど,AIの本来の使い方ではない「誤用」を通して一味違った写真を撮るためのアプリケーションです.Altergraphは,写真を撮影するためのAltergraph.capture,そして写真集の素材となる写真を選ぶためのAltergraph.curationという2つのアプリケーションで構成されます.このアプリケーションはどちらも画像認識のAIを使用しており,普段私たちが写真を取るプロセスとは少し違った仕方で写真を撮影することができます.また,自分で改造する事もできます.
Threshold (2019) Martin Adolfsson
自身のスマホ上の過去に撮影された写真と比べて,似ている場合は写真を撮らせてくれないアプリケーションです.
写真が撮れなくなる,という体験を通して自分がこれまで撮ってこなかった写真撮影に強制的に挑戦させられることは独創的な写真を生む可能性があります.
また,アプリを活用して自分が撮ってきた写真の特徴を意識することは,自分自身で判断することが難しい側面があることを考えると,意義深いでしょう.
A Computer Walks Into a Gallery (2018) Philipp Schmitt



コンピュータの検出結果を視覚化したこのインスタレーションは,鑑賞者が作品を別の方法で見ることで,新しい見方で作品を鑑賞することを促します.
Perception Engines (2017) Tom White

シンプルな線や円を使った描画を行ない,随時画像分類にかけて目的のオブジェクトの確度が高くなるように線や円を動かしていきます.
コンピュータが見立て可能であるという判定のみを使った抽象的な絵を描くことによって,これまでの絵画などの発想と全く異なる風合いの抽象画を作っています.


Evolutionary faces (2020) Matty Mariansky
曲線を描くペンプロッターを制御するモデルと顔認識アルゴリズムを敵対的に学習させることで,人間にとっては顔に見えるけれども認識されないイラストを生成します.
Perception Enginesとはまた違った抽象的なグラフィックを生成することに成功しています.




複雑性とAI
人工知能の限界
人間の知能や身体は複雑性の極みと言えます.
では人工知能はどのような点で人間の知能を再現できており,どこに限界があるのでしょうか.
シンボリズムとフレーム問題
シンボリズム(記号主義)とは現象を記号に置き換えて考えていくことであり,エキスパートシステムなどの,古典的な人工知能が具体例であると言えます.
古典的な人工知能では人間の処理を膨大な条件分岐で記述します.
そうしたときに起こる問題としてフレーム問題があります.
ダニエル・デネットが論文で示した例について考えてみようと思います.
画像のようにロボットはバッテリーを持ち帰らなければいけないですが,爆弾が上にのっています.

このときロボットはどのようにしても失敗してしまいます.
- バッテリー交換するために爆弾も同時に持ってきてしまう
- バッテリー近くで膨大に考えている間に爆発してしまう
- バッテリーを取りに行く前に無関係な事項を洗い出してフリーズ
このようにシンボリズムには限界が訪れてしまうのです.
コネクショニズムと中国語の部屋
一方,コネクショニズムは現在の深層学習のようにニューロンの調整によって,複雑な処理が可能となっています.
しかし,複雑なタスクが可能になっただけで本質的に人間の知能を達成したと言えるでしょうか?
ジョン・サールの中国語の部屋について考えてみようと思います.

何か複雑なタスクを達成するとき,ある入力に対して深層学習ベースの人工知能を駆使して適切な出力を得られたとします.
そのとき人工知能内では入力から出力への変換を翻訳のように行なっているだけであって,人工知能自体はそのタスクの本質的な意味を理解していません.
このように人工知能もまだまだ人間に匹敵するような状態にはなれていないということがわかります.
コンピュータはアートを作れるか
Obviousによるこの作品は果たしてAIがアーティストなのでしょうか?

訓練された動物による絵画はアートと呼べるのでしょうか?
このチンパンジーはアーティストと呼べるのでしょうか?
Aaron Hertzmannによる論文,”Can Computers Create Art?”では,コンピュータがアーティストになり得るかということについて様々な観点から分析され語られています.
https://arxiv.org/abs/1801.04486
結論から言うと,
現状ではどんなソフトウェアシステムもアーティストとは呼べない
と述べています.
その理由を見ていきたいと思います.
社会性
デイヴィッド・ホックニーはアートは主に社会的な行動であると主張します.アートは人ー人のコミュニケーションであり,ディスプレイであるとも言っています.
つまりアートは他人に何かを伝達したり,議論したりする仲介物であるということです.
意図
現代アートの世界では,アーティストの役割は作品の「意図」「アイデア」などを与えることであり,作品のコーディネート以外に実装の必要はないというものがあります.
デュシャンの「レディメイド」などがその典型と言えます.

逆に言えば,意図を忠実に再現する役割である実質的な制作作業はアーティストとしての実践とは区別しなければいけないということです.
成長性
人間の芸術家はアートを制作することを通して,自分自身をアップデート(成長)させます.
プログラムが同じように自身をアップデート(自己修正)するためには,単に自分自身を評価するだけでなく,自分自身の世界観を持っていることが必要です.
そのため,表面的な成長(単なる最適化方向への変化など)は簡単ですが,意味のある成長をコンピュータ自身が定義することは難しいです.
また,プログラムに欠けている重大な要素は
- 自分の経験
- 世界の出来事
- 自分の作品への反応
- その他の環境
に対して,意味のある反応をする能力です.
これらを実現するにはSNSなどのインターネットを介したデータの収集や解釈などの機能が必要かもしれません.
Emissaries (2015-2017) Ian Cheng
Ian Chengは作品の中に人工知能を「住まわせ」,鑑賞する作品Emissariesを制作しました.

動画のembedが不可能だったため,MoMAの紹介リンクから御覧ください.
https://www.moma.org/calendar/exhibitions/3656
作品は3つの世界から構成されています.
- “The Squat of Gods”のエージェントは,自分の部族が住む火山が噴火することを知っていて,みんなを逃がそうとする少女.
- “Forks at Perfection”のエージェントは,犬と長くて細い金色の首輪付きリードが組み合わさった「シーバ(Sheba)」と呼ばれる不思議な存在.このリードこそが主体であって犬は乗り物に過ぎない.犬とリードは一緒に,「完璧な人生」や人間性を理解する方法を探し求めていく.
- “Sunsets the Self”のエージェントは,知覚をもつ黄色い水たまりで,「Wormleaf」に命を吹き込むことで生命を得ようとしている.Wormleafは、半人間「Oomen」との戦いを繰り広げる
また,それぞれの世界で3つの脳が働いています.
- 脅威(戦うか逃げるか判断)
- 欲望と意味(欲求が満たされない場合,飢えを感じて怒る)
- 物語(設定された最終目標を達成しようとする)
観賞者はこれらの世界に何らかのストーリー,成長性,知性を見出すかもしれません.
BOB (Bag Of Beliefs) (2018-2019) Ian Cheng
Ian Chengは,意識についての探求を深めるため,動物の感覚のモデル化にトライしています.
「デーモンの連邦会議」と呼ぶ動機モデルと,感覚的な入力から「信念」を構築して適応するモデルのフィードバックで構成されます.
また,それぞれの頭が異なるAIのモデルで動いており,それらの合意として行動が決定されます.
意識は,自分が望む,より良い「信念」を取り戻すためのエージェントの能力であるとしています.
AIとは
昨今では,AIや人工知能という言葉を毎日のように目にしますが,今現在完全なAIというものは存在しません.
ですが,AIには約60年ほどの歴史があり,着実に発展を遂げてきました.まずは,これまでAIがどのような経緯で発展してきたか,その歴史を紐解いてみましょう.
歴史的側面
まず,以下の画像を見てください.AI研究は,時代の流れに伴いブーム期と冬の時代を繰り返して発展してきました.このブーム期は全部で3つあり,それぞれ第1次AIブーム,第2次AIブーム,第3次AIブームと呼ばれています.現在は,第3次AIブームの渦中です.
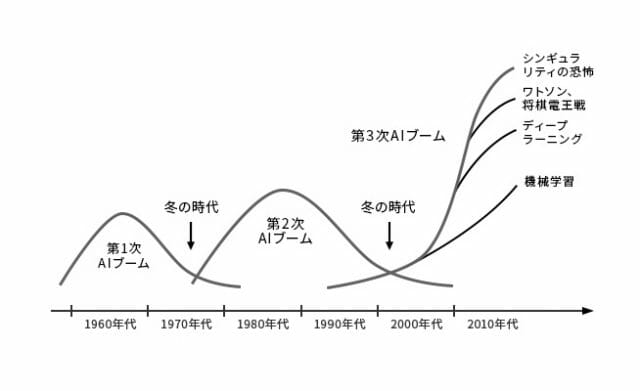
(松尾豊『人工知能は人間を超えるのか ディープラーニングの先にあるもの』KADOKAWA 発行 より引用)
起源
AI研究が本格的に始まったのは,1956年に行われたダートマス会議という会議がきっかけとされています.この会議は,ジョン・マッカーシーという科学者が主催し,他にもマービン・ミンスキーやクロード・シャノンといった科学者等が参加しました.そしてこの会議の提案書において,人類史上初めて人工知能という用語が使われたと言われています.
この会議の提案書では,人間の知的な活動を機械をシミュレートするための研究を進めるといった旨の内容が記載されていました.今は人間にしか解けない問題を機械でも解けるようにする,機械が自ら学習できるようにする,など現在のAIのイメージに近い内容がすでに構想されていました.
そしてこのダートマス会議以降,第1次AIブームが訪れます.第1次ブームでは,推論と探索が中心的に研究されました.ここでの推論とは,人間の思考パターンのことを指します.人間の思考パターンを分解し,問題に対して適切なパターンを探索することで,機械に人間と同じように思考することを目指しました.その成果として,パズルや迷路を人間よりも高速に解くことができるようになりました.しかし,問題もありました.パズルのようなルールが明確な問題に対しては成果を発揮しましたが,それ以外の問題に対しては成果を発揮することができませんでした.その結果,AI研究は一度目の冬の時代へと突入していくことになります.
エキスパートシステム
その後1980年代より,AIは第2次ブームへと突入します.第2次ブームでは,機械に知識を入れるというアプローチで研究が進み,エキスパートシステムというシステムが生まれました.エキスパートシステムではまず,機械に専門家の知識をデータとして入力します.データを入力した後は,第1次ブームで培った推論システムと組み合わせることで,機械は専門家と同じような役割を担うことができるようになります.このエキスパートシステムは医療や金融など様々な分野での応用が期待されました.
しかし第1次ブームの時と同じく,第2次ブームにおいても問題が発生します.知識を機械に入力していくことでエキスパートシステムを構築していきますが,入力されるデータが膨大になりルールの量が増えていくにつれ,ルール同士の一貫性が失われ矛盾が発生してきました.また,私たち人間が普段曖昧に使用している言葉を機械にどのように入力すればいいのか,その難しさが再認識されることとなりました.例えば,「なんとなく気分が重い」という症状の場合,「なんとなく」とはどのような意味なのか,明確にすることは難しいです.このような問題に直面し,AI研究は再び冬の時代へと突入していくことになります.
第3次AIブーム
そしていよいよ,AI研究は第3次AIブームを迎えます.第3次AIブームは現在も続いており,AI研究に大きな発展をもたらしました.その発展を支えるのが,深層学習という技術になります.
第2次AIブームまでは,人間がルールを設定し,機械がそれを計算することにとって問題を解くことが想定されていました.一方で,第3次AIブームで大きく発展した深層学習では,人間がデータを集めて機械に与えることで,機械が自らルールを発見することができます.このことにより,これまでの機械が解けなかった問題を機械が解けるようになりました.
深層学習
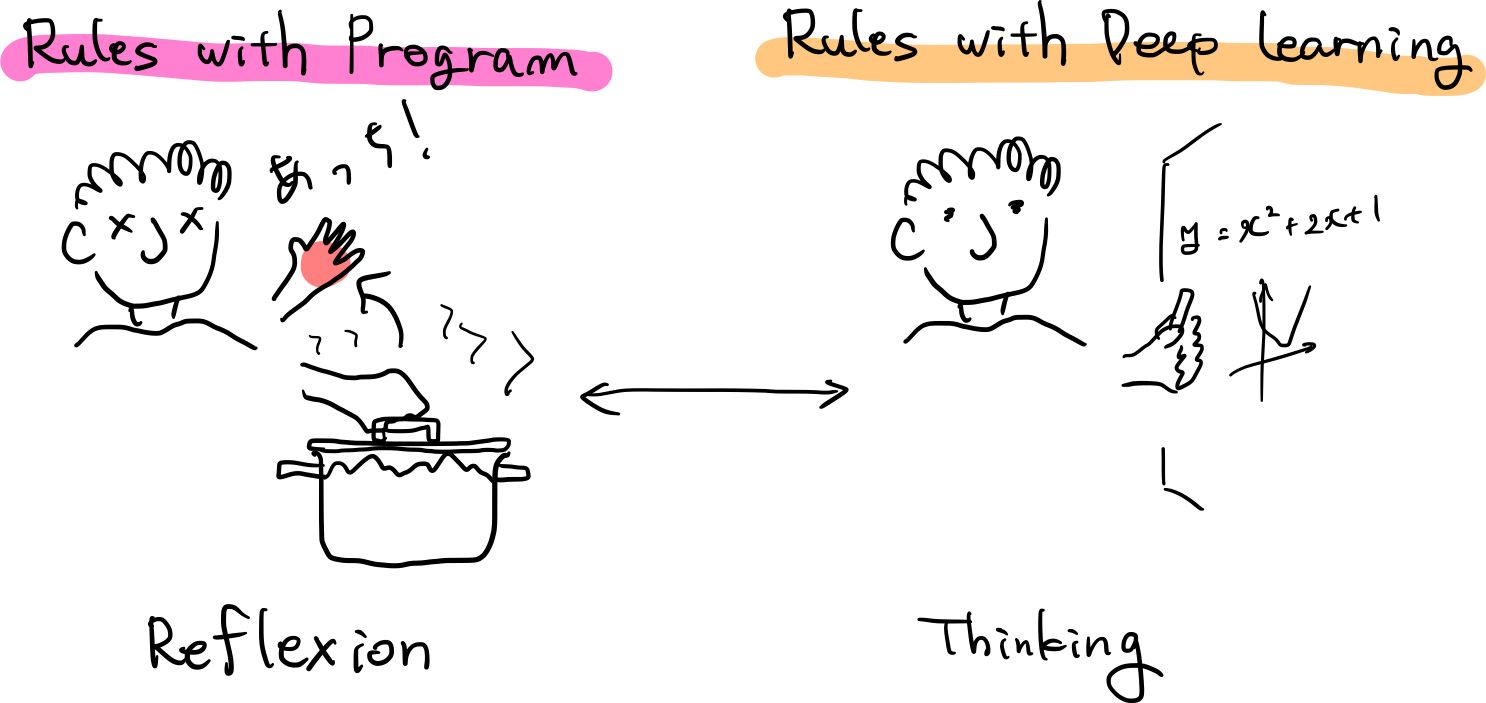
古典的プログラムと深層学習の違い
古典的プログラムは人間がある事象を観察したりしてルールを導き出して記述し,そのルールに基づいてコンピュータが演算し結果を出力します.
それに対して,深層学習は人間が用意した素材(データセット)と構成(アーキテクチャ)を元に,コンピュータがルール自体を学び,演算の結果を出力します.
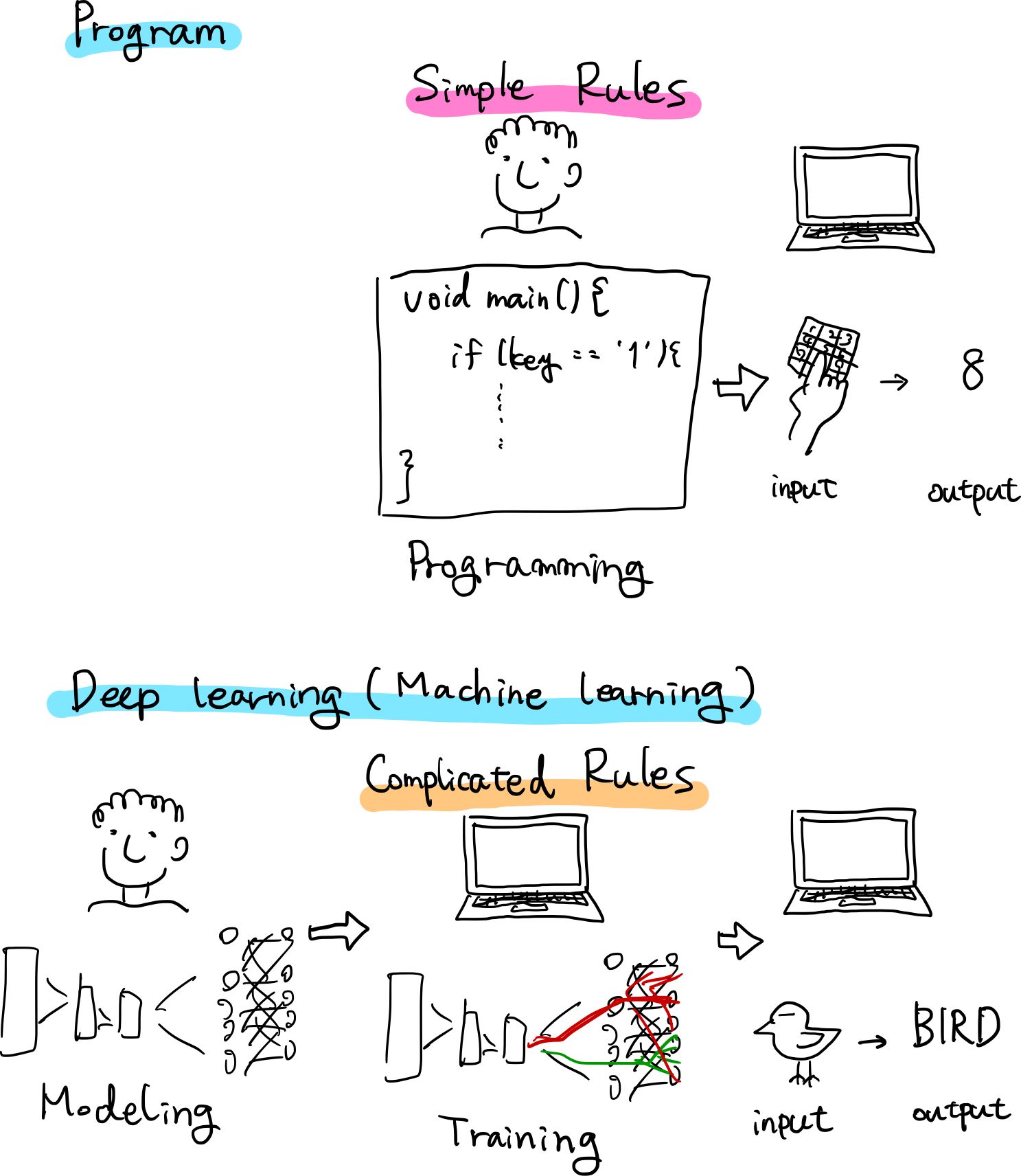
わたしたち人間が普段していることに置き換えると,
- 古典的プログラムは反射
- 深層学習は思考
と言うことができるかもしれません.
深層学習の仕組み
人間の脳はニューロン上で電気信号が伝わっていくことにより処理が行なわれます.そしてそれらは,シナプス結合の強さによって軸索から次の神経細胞への信号の伝わりやすさが変化します.
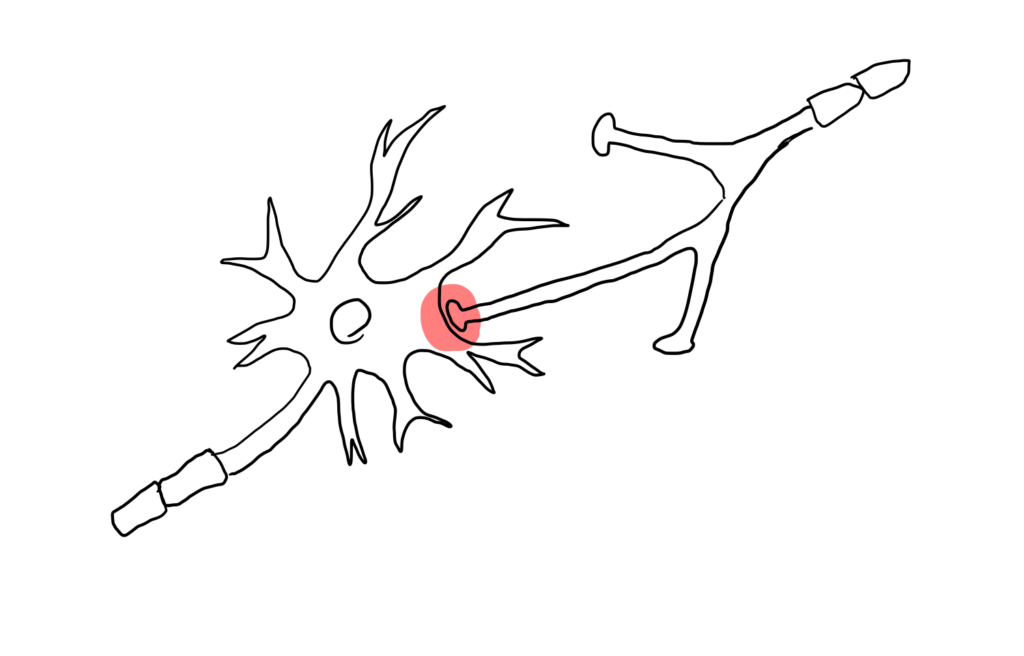
一方,人工知能の構造を画像分類を例に説明します.
- 人工的なニューロンをまず場(アーキテクチャ)として作成
- それを乱数でシナプス結合の強さを初期化
- 最終的に0-9の確率を算出
- 学習用のデータである正解ラベルを元に少しずつそれぞれの結合強さを調整(訓練,勾配法)
- 演算結果とラベルとの誤差(loss,損失関数)が少なくなると学習完了
そのモデルと結合強さ(重みW)の情報が学習済みモデルということになります.
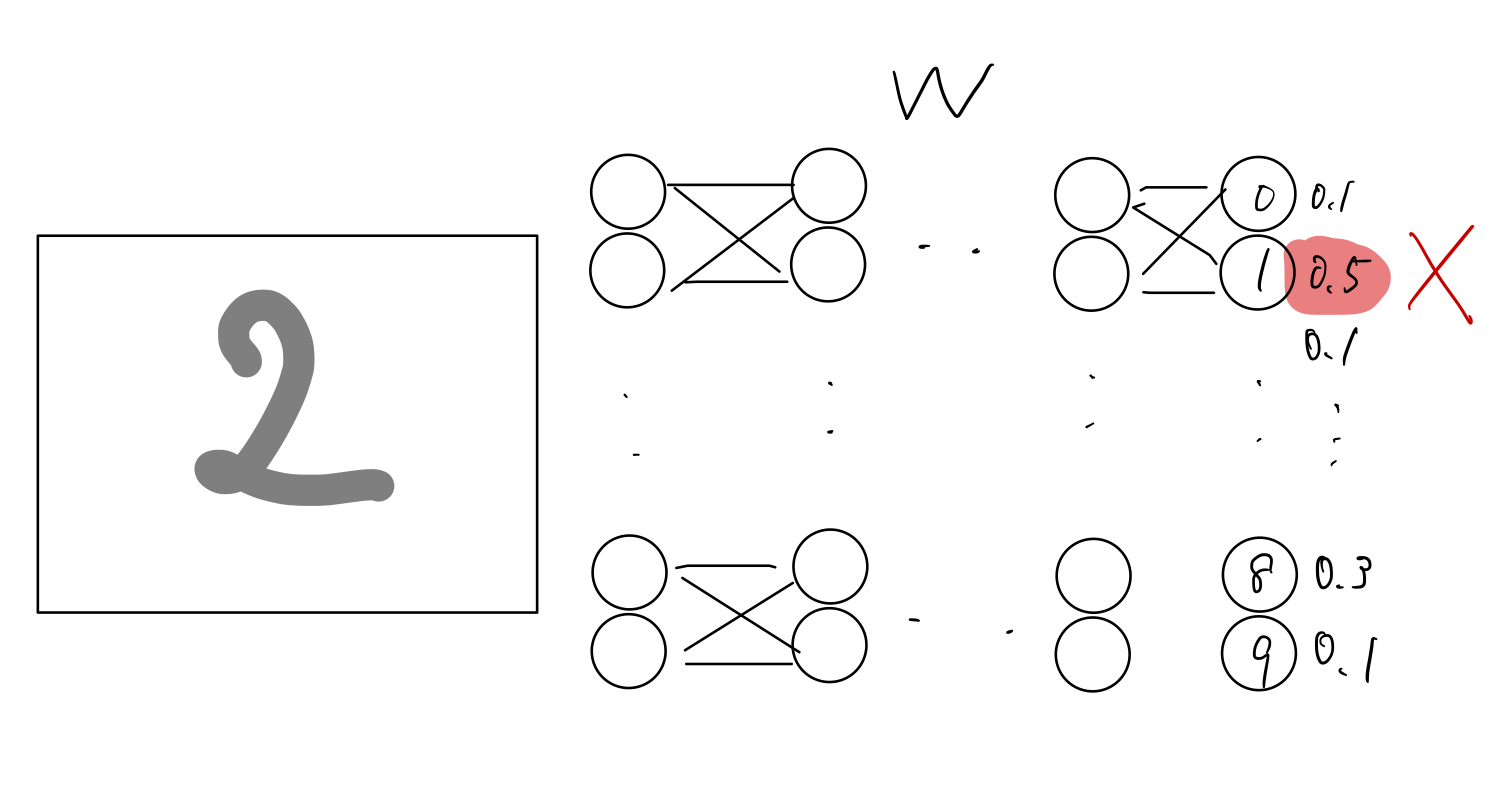
ここの中間層(隠れ層)が複数あるもののことを深層学習と言います.
E(loss): 「目標」と「実際」の出力の誤差 が小さくなるように更新していく方針で,EのWに関する微分をとり,正負からアップデートをかけて調整していきます.
どのようにAIは見るか
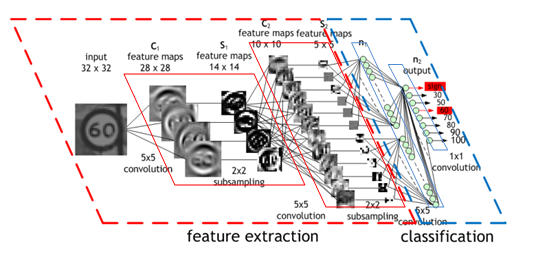
(Convolutional Neural Network (CNN) by NVIDIA より引用)
深層学習を飛躍的に発展させた1つの要素がCNNです.
CNNは単なる深層学習モデルDNNと違い,畳み込み演算(フィルター)を適用することで、画像の時空間的な依存性(隣り合ったピクセルとの関係)をうまく捉えることができます.
畳み込み演算が行われた結果の画像は図のように変化します.
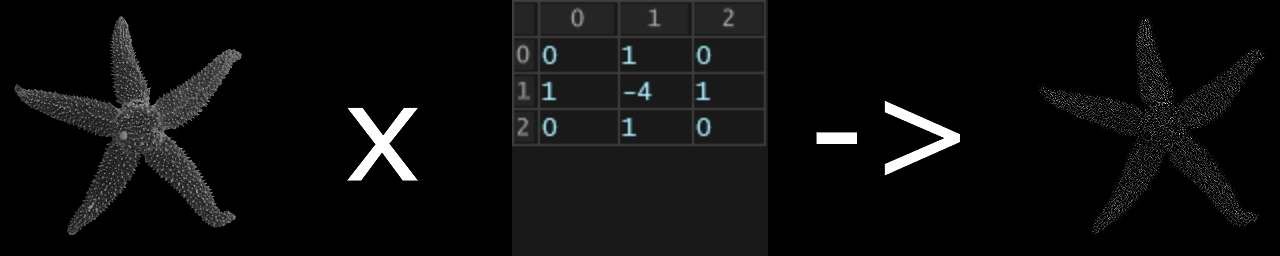
異なるフィルタを複数用いて画像を加工し,層を増やしていくことで
- 第一層: 輪郭
- 第二層: テクスチャ(質感)
- 第三層: パーツ(目,耳など)
.
.
.
などより詳細な特徴マップを得ることができます.
以下の可視化動画の”Convolutional Neural Network”部分がわかりやすいです.
こちらのGoogle Arts & CultureのCurator tableはアートの画像的な特徴を捉えて,2Dにマッピングしています.
日本画と西洋絵画が一部かなり近いことに気付かされたりします.
https://artsexperiments.withgoogle.com/curatortable/
モデル
識別モデル
識別モデルとは,先程何度か出てきた画像分類タスクのように,入力が特定のクラスに属するか判定します.
画像分類以外にも,
- オブジェクトディテクション
- セマンティックセグメンテーション
- 深度推定
- 姿勢推定
など,数多く存在します.

例えばセマンティックセグメンテーションは,画素1つ1つに対してモデル内の何のクラスに属するか分類するため,画像のように厳密に領域を区別できます.
生成モデル
これまで紹介してきた識別モデルとは別に,生成モデルと呼ばれるモデルがあります.
識別モデルでは,例えば画像分類のように,与えられた入力に対してその画像がどのクラスにあたるかを判別することを目的としていました.
一方で生成モデルでは,今あるデータの生成過程をモデル化することを目的としています.生成過程をモデル化することができれば,学習データと似たデータを新しく生成することができるようになります.
This Person Does Not Exist
This Person Does Not Exist
というサイトはGANという生成モデルで作られた実際には存在しない顔を表示するサイトです.
Edmond de Belamy, from La Famille de Belamy (2018) Obvious
2018年に,パリのアーティストグループであるObviousが,AI (GAN) を用いて制作した絵画をオークションに出品しました.そこで,7,000(約79万円)~10,000(約113万円)ドルの予想価格に対して,それを大きく上回る432,500ドル(約4894万円)の値段で落札されました.このオークションは,クリスティーズという世界で最も長い歴史を誇る美術品オークションハウスで行われたものでした.以下が,実際にオークションに出品された作品です.

右下には,アーティストの署名として,とある数式が記載されています.この数式は,この後紹介するGANというアルゴリズムの数式を意味しています.つまりObviousは,この作品の作者がAIであると主張しているのです.
果たしてAIはアートを作ることができるのか,またこのアルゴリズムの出どころで一悶着あったりなど,この作品の是非については意見が分かれると思いますが,何かと話題を呼んでいることは間違いありません.
このように,生成モデルを用いることによって,非常にクオリティの高い画像やアート作品を作り出すことができます.
ここで紹介した事例以外にも,生成モデルを用いることで以下のようなことができます.
- 絵画のデータを学習して,新しく絵画を生成する
- 音楽のデータを学習して,新しい音楽を生成する
- 文章を学習して,新しく文章を生成する
- 俳句のデータを学習して,新しく俳句を生成する
ここまで見てきた生成モデルには様々な種類があり,現在もたくさんの研究が行われています.今回は,その中でも有名なVAEとGANについて扱います.
VAE
生成モデルの一つに,Variational Autoencoder (VAE) と呼ばれるモデルがあります.VAEは生成モデルの一種なので,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.
VAEは,Autoencoderと呼ばれるモデルを発展させたモデルになります.そのため,まずはAutoencoderについて説明します.
Autoencoderとは,訓練データを表現する特徴を学習するためのネットワークです.
訓練データとは,学習したい画像を集めたデータセットになります.ここでは,例としてmnistという有名なデータセットを取り上げます.
mnistは,以下の画像のように手書きの文字を集めたデータセットになります.画像認識や画像生成など,AI研究において頻繁に用いられるデータセットなので,これからも目にする機会は多いでしょう.

Autoencoderとは,ニューラルネットワークのモデルの一つであり,入力画像に近い画像を出力することを目的とするモデルです.Autoencoderは,EncoderとDecoderという二つのネットワークで構成されます.Encoderは入力画像を潜在変数zと呼ばれる低次元の特徴へと変換します.逆に,Decoderは潜在変数zを入力として画像を出力します.これにより,Autoencoderは入力された画像を復元することができます.以下が,Autoencoderのネットワーク図になります.
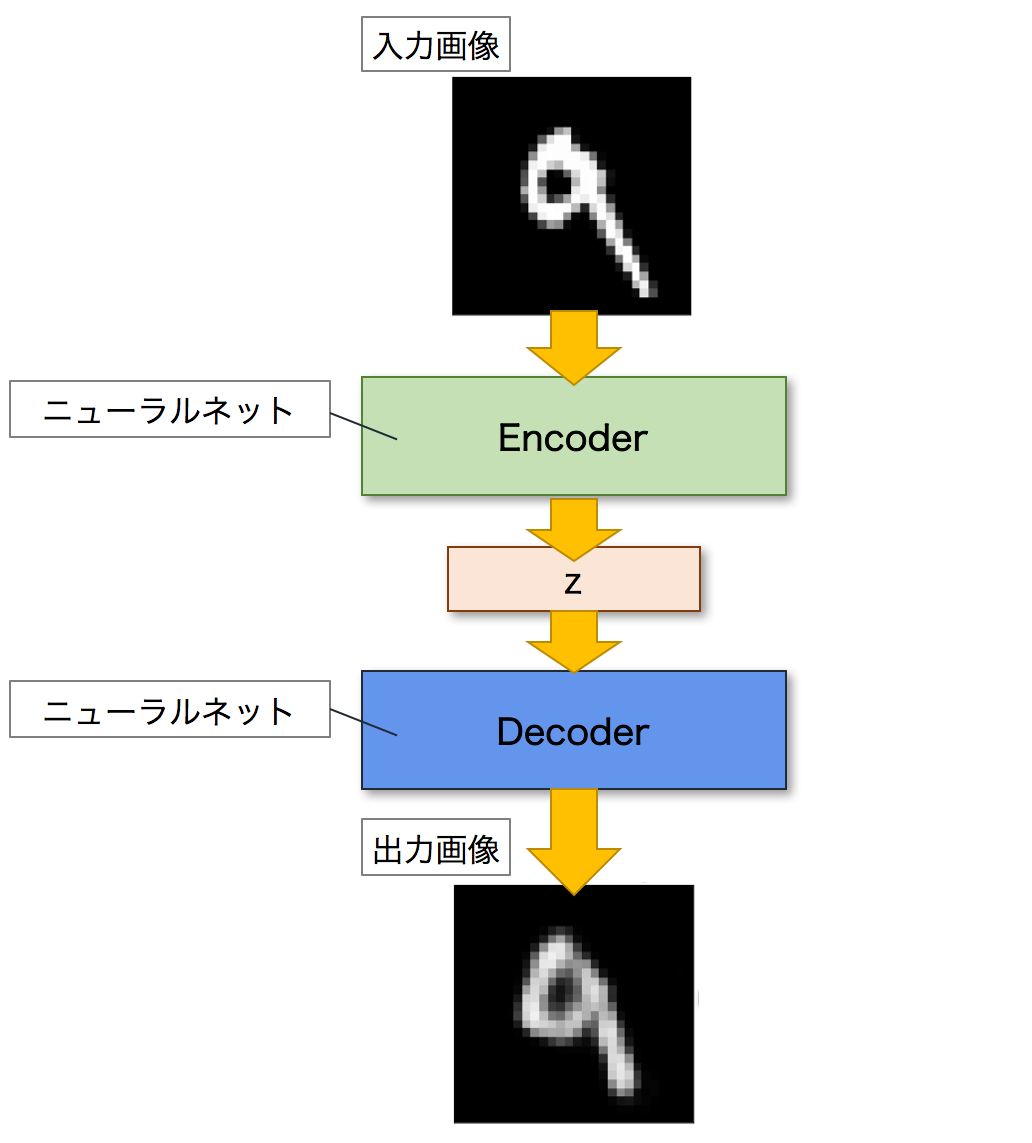
次に,VAEについて見ていきましょう.VAEは,Autoencoderを発展させたモデルになります.以下がVAEのネットワーク図になります.全体的な構造としては,Autoencoderと同じくEncoderとDecoderの二つのネットワークで構成されています.そしてAutoencoderと同じように,Encoderが入力画像を潜在変数zへと変換し,Decoderがこの潜在変数zを元の画像へと復元して出力します.
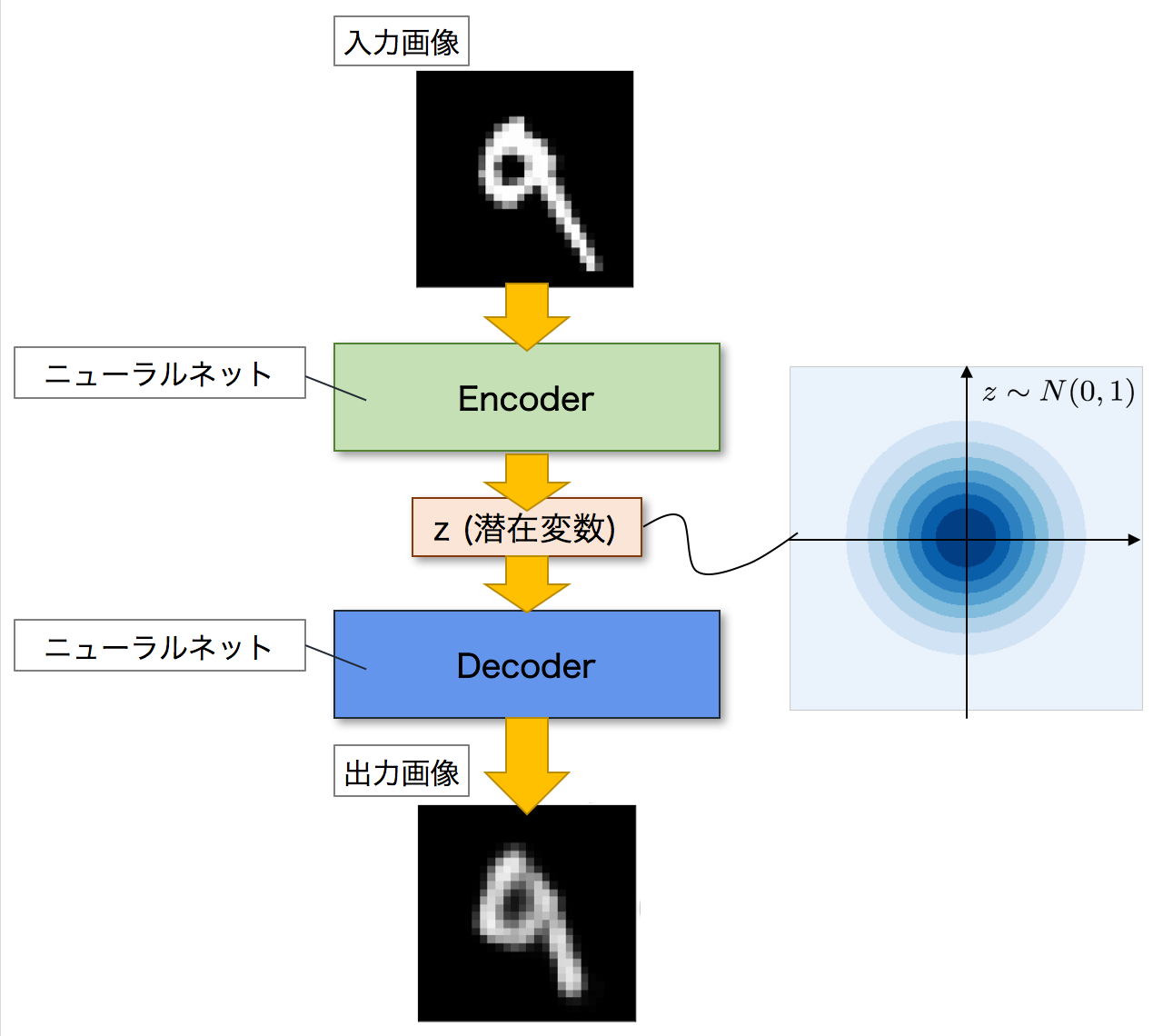
VAEがAutoencoderと異なるのは,潜在変数zの分布です.Autoencoderでは,潜在変数zにデータが押し込められますが,その分布については詳細はわかりません.一方で,VAEの場合には,潜在変数zに同じようにデータを押し込めますが,その分布が特定の確率分布に従うことを仮定しています.つまり,潜在変数zがどのような分布をしているのかが分かるということです.
VAEは生成モデルなので,学習を終えた後は,新しく画像を生成することができます.その際,Decoderに潜在変数zを入力して画像を生成しますが,この時に潜在変数zがどのような分布をしているのかがわかれば,生成する画像を細かくコントロールすることができます.
例えばmnistであれば,そのデータには0~9までの10種類の数字が含まれます.VAEを使ってmnistのデータを学習することで,潜在変数zのうち,ある領域には0,ある領域には1,そして別の領域には他の数字が含まれるようになります.以下の画像は,実際に潜在変数zの分布を可視化した画像です.画像右上の領域には0が,左下の領域には1が含まれていることがわかります.

(https://github.com/ChengBinJin/VAE-Tensorflow より引用)
そのため,もしこのVAEを使って0という数字を生成したければ,0が含まれる領域から潜在変数zを選べばいいことになります.上の画像で言えば,右上の潜在変数zを選べば良いわけです.この時,VAEであれば潜在変数zの分布がわかるので,狙った数字を生成しやすくなるのです.この点が,VAEがAutoencoderよりも優れている点になります.
GAN
GANも生成モデルの一種です.そのためVAEと同じように,訓練データを学習することで,そのデータに近いデータを新しく生成することができます.また,NVIDIA Canvasのように,ある入力を別の入力へと変換することもできます.
GANがVAEと大きく異なる点は,その学習方法にあります.GANは,日本語では敵対的生成ネットワークと訳されますが,その名の通り,GANでは「敵対的」に学習が進んでいきます.「敵対的に」学習が進む,とはいったいどういうことなのでしょうか.
GANの構造を以下の画像に示します.GANは,GeneratorとDiscriminatorという2つのネットワークで構成されます.Generatorは,データを生成するネットワークです.Discriminatorは,Generatorが生成した偽物のデータと本物の学習データに対して,どちらが本物のデータであるかを識別します.この2つのネットワークを交互に学習していくことで,Generatorはより本物に近いデータを生成できるようになり,Discriminatorは本物・偽物をより正確に判断することができるようになっていきます.この時,GeneratorとDiscriminatorがお互い競い合うように学習していくため,「敵対的」と呼ばれているのです.
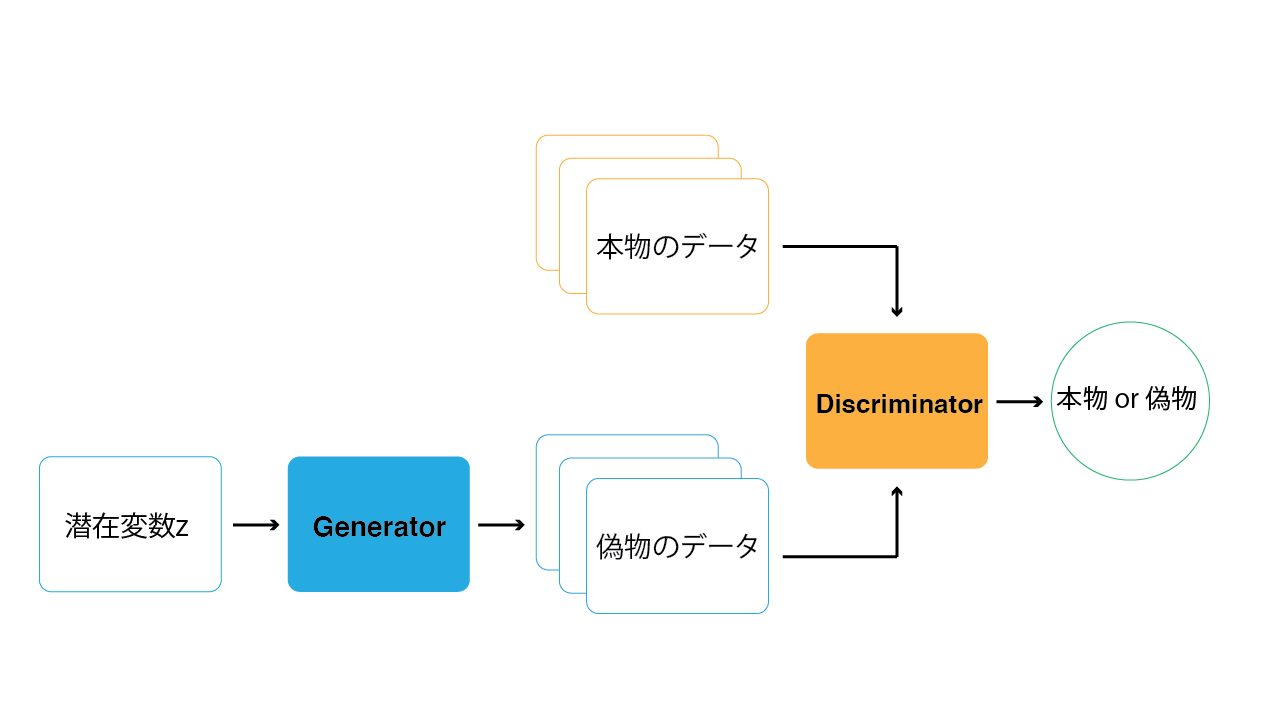
このGeneratorとDiscriminatorの関係は,よく紙幣の偽造に例えられます.偽札の作成者 (Generator) はなるべく本物に近い紙幣を作ろうとし,警察官 (Discriminator) はより正確に偽札を見分けようとします.そしてお互い交互に学習していくことで,最終的に偽札の作成者は本物とほぼ区別のつかない偽札を作れるようになっていきます.
この学習方法のおかげで,GANはVAEと比べてより鮮明な画像を生成することができます.一方で学習が難しいという問題もありますが,それを改善するために様々な研究が行われています.はじめに紹介した「This Person Does Not Exist」や「NVIDIA Canvas」もGANを使用したサービスです.
他にもGANを活用したサービスとして,Artbreederというサイトを紹介します.Artbreederは,AIを用いて様々な画像を生成することができるサービスです.
人物画像やアニメキャラ,風景画やクリーチャーなど,多種多様な画像を生成することができます.
また,Artbreederでは生成した画像に対して,パラメータを操作することで自由に編集を行うことができます.